졸업프로젝트 때 직접 dataset, dataloader를 구현했었는데 시간에 쫓겨서 개발한지라 정말 개발새발로 내 기억 속에 남아있다.. 이 참에 헷갈리거나 몰랐던 내용들 위주로 정리해봤다.
data 흐름
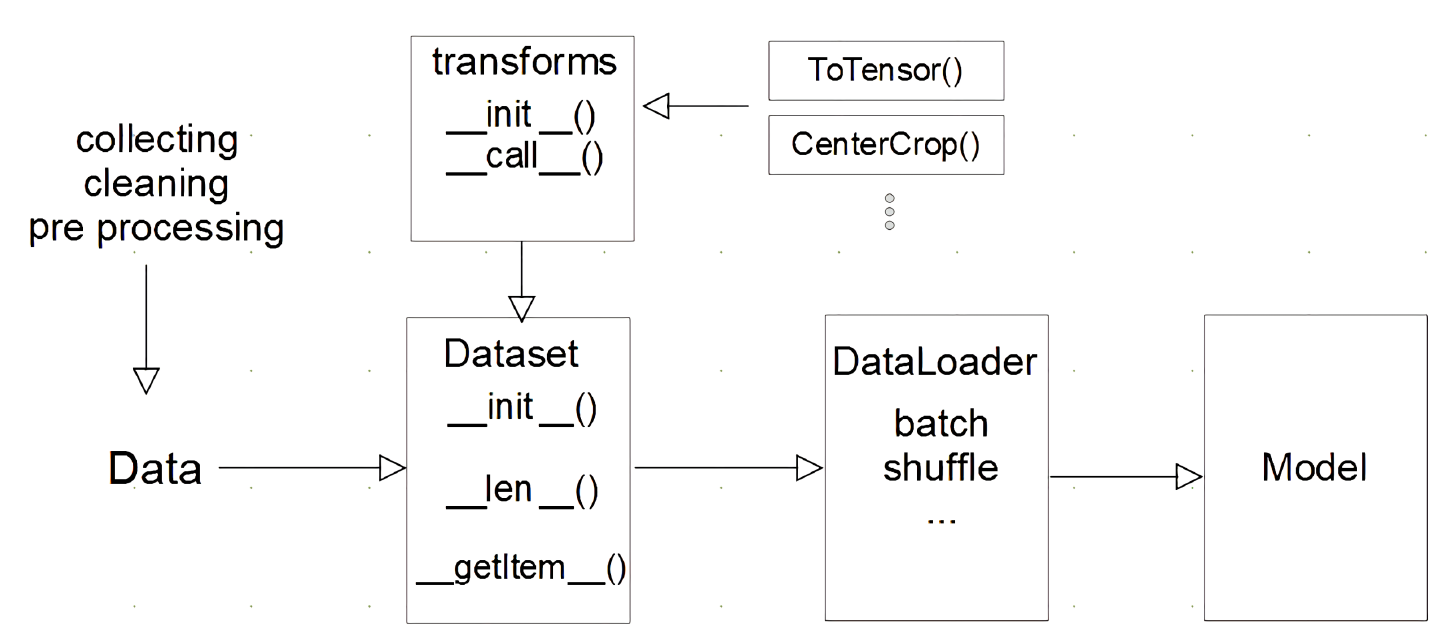
중요한 것은 데이터를 tensor로 바꿔주는 것 또한 따로 고려를 해야한다는 것이다. 난 그냥 아무 곳에나 마구잡이로 막 넣었는데 ...
torch.utils.Data.Dataset
__len__, __getitem__ 등은 데이터에 맞춰 적당히 개발하면 된다.
Tensor 변환
__getitem__에서 안한다!
즉, data를 load하는 시점에서는 데이터를 tensor로 변환하지 않는다. 학습이 시작되는 시점에 transformer와 같은 함수를 통해 일괄적으로 tensor로 변환한다.
다행히 cpu, gpu가 병렬적으로 이러한 작업들을 하게 개발되서 빠르다고 한다.
최근에는 HuggingFace라고 표준화된 라이브러리를 사용하기도 한다고 한다.
torch.utils.Data.DataLoader
- data의 batch를 생성해주는 클래스
- 학습직전(gpu feed전) 데이터 변환 담당
- tensor로 변환
- 병렬적 데이터 전처리에 대한 고민이 필요하다.
아래 블로그 참고
https://subinium.github.io/pytorch-dataloader/
sampler
getitem의 idx를 조절하는 방법을 정의한다고 한다. batch_sampler도 동일하다고 하다.
collate_fn
getitem을 통해 [[data, label], [data, label], [data, label] ... ]과 같은 형식으로 모여있는 batch를 [[data, data, data ...], [label, label, label, ...]]로 바꿔주는 형식을 정의한다고 한다.
torchvision.transforms
data_transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])이처럼 아예 데이터 변환을 위한 transform을 따로 구성해야 한다. 졸업프로젝트처럼 dataset에서 하나하나 전부 변환하는 바보같은 짓 하지말자..
