
지난 포스팅에서 스토리지의 종류중 객체 스토리지, 블록스토리지에 대해서 다루어 보았다.
오늘은 마지막 칼럼형 스토리지 Redshift에 대해서 다루어보고 이와 비교되는 EMR, Athena에 대해서 다루어 보겠다.
Redshift
OLAP(online analytical processing) 데이터베이스 기반의 고성능 컴퓨팅 파워가 요구되는 복잡한 쿼리를 위해 여러개의 데이터베이스를 쌓아서 하나의 큰 데이터베이스, 즉 '데이터 웨어하우스'다. 칼럼단위로 데이터를 저장하는 칼럼형 스토리지 로도 불린다.
컴퓨트 노드
Dense node
마그네틱 스토리지에 최대 326TB의 데이터 저장
SSD에는 최대 8192TB의 데이터 저장
leader node
하나 이상의 컴퓨트 노드가 있는 경우 이 노드들의 커뮤니케이션을 조정하고 클라이언트와 소통하도록 할 수 있게 해주는 Node
데이터 분산 유형
EVEN,KEY,ALL
- EVEN : 리더 노드가 모든 컴퓨트 노드에 균일하게 분산된다.
- KEY : 단일 칼럼내 값에 따라 데이터가 분산된다.
🎇동일한 값의 칼럼은 동일한 노드에 저장 - ALL : 각각의 테이블이 모든 컴퓨트 노드에 분산된다.
Redshift Spectrum
S3에 저장된 파일에서 데이터를 쿼리할 수 있는 서비스로서 클러스터에 데이터를 직접 임포트 하지않고도 쿼리 할 수 있다.
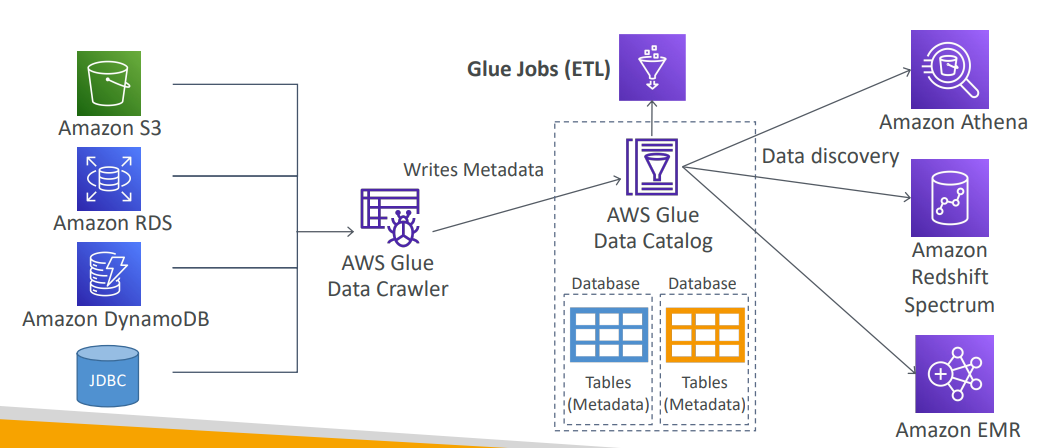
EMR
ETL(Extract,Transform,Load)서비스를 가능하게 해주며, Hadoop cluster를 만들어 대용량의 데이터를 분석하고 저장한다. 빅데이터 플랫폼 이라고 생각하면 된다.
Athena
S3 객체를 분석하기 위해 서버리스 쿼리를 가능하게 해주는 서비스이다.
또한 JSON과 같은 사람이 읽기 힘든 언어로 작성된 로그기록등의 데이터를 사용자가 원하는 형태로 포맷화 시켜서 읽기 쉽게 만들고 검색을 용이하게 해준다.
공통점
EMR,Athena,Redshift 모두 데이터를 분석하고 검색하고 저장하기 위한 용도로 사용된다.
이 세가지 서비스로 데이터를 분석해 얻은 통찰력은 Amazon QuickSights를 사용해 시각화를 할 수 있다.
차이점
- EMR : 주로 '빅데이터'에 대해 사용된다.
- Redshift : BI(Business intelligence)를 얻기 위해 사용되거나, 쿼리의 결합, 집계적인 쿼리, 대규모의 쿼리등에 사용된다.
- Athena : 서버리스 쿼리로 📌비용 효율적인 쿼리 ,가시성이 높아야하는 쿼리등에 사용된다.
💡 Redshift는 서버가 있는 플랫폼이며 Athena보다 비용효율적이지 않다. 다만 Athena도 대규모쿼리가 가능하지만 대규모 데이터에 대해서는 Redshift가 더 효율적이다.
마치며
이번 포스팅에서는 AWS에서 지원하는 분석용도구 세가지에 대해서 알아보았다. 분석할 때 사용자가 어떤 목적으로 분석하는지에 따라 적절한 분석 서비스를 이용하면 비용과 운영적인 측면에서 훨씬 효율적일 것이라 생각한다. 다음 포스팅에서는 데이터베이스에 대해서 다뤄볼 예정이다.
