지난 포스팅에서 관계형DB에 대해서 포스팅했었다. 이번에는 비관계형DB에 대해서 다루어보겠다.
비관계형 DB(NoSQL)
비관계형 DB는 말그대로 관계가 없는 즉 SQL처럼 순서대로 저장후 이 순서에서 관계가 있는 구조화가 아닌 비구조화 DB이다. 하지만 모든 데이터가 나름의 구조를 갖고 있기 때문에 다중 구조라 함이 좀 더 옳은 표현 같다.
- NoSQL은 관계형 + 비관계형 데이터 둘다 저장 가능하다.
💡 Schema의 유연성을 가진다.
ex) 당장 무슨 DB를 쓸지모르고 추후에 DB를 바꿀 예정이라면 비관계형 DB를 사용해야한다.- 초당 100밀리초 이하의 처리량을 가진 매우 빠른 성능을 가진다.
- 400KB이하의 데이터를 저장해야 효율적이다.
📌 400KB이상의 데이터도 저장할 수 있지만 성능이 낮아진다. 따라서 문서나 이미지와 같은 큰 용량을 가진 콘텐츠는 저장하기 적합하지않다.
데이터 정렬/조회
- 비관계형은 관계형과 다르게 스키마가 없다는 것이고 각 아이템은 테이블 내에서 유일한 값을 지닌 기본 키 속성을 지닌다. 데이터 타입이 다양하며 무순위로 정렬한다.
- 스키마가 없기때문에 관게형DB처럼 임의적인,복잡한 쿼리는 적합하지않다 .항상 기본 키를 사용한 쿼리에 최적화 되어있다.
키벨류 스토어/도큐먼트 스토어
- 비관계형DB는 테이블에 여러개의 아이템이 있고, 아이템은 하나 이상의 속성을 갖고 있으며, 이 속성은 키/벨류 쌍으로 이루어져 있어 키벨류 스토어라 부른다.
- 반면 MongoDB와 같은 것을 도큐먼트 스토어라 부르며, 특수한 유형의 값으로 저장된 도큐먼트의 콘텐츠를 분석하고 메타데이터를 추출한다.
- Amazon Neptune과 같은 그래프 데이터베이스를 이용해 아이템 속성 간 관계를 분석 할 수 있으며 이것은 레코드 내의 관계만 분석 가능한 관계형 DB와 중요한 차이점이다.
DynamoDB
AWS에서 지원하는 비관계형 데이터베이스다. 각종 관리업무를 지원하며 다수의 파티션에 분산된 데이터 구조를 이용해서 초당 수천회의 읽기/쓰기 작업을 처리한다.
온디맨드 모드
EC2인스턴스의 온디맨드 모드처럼 워크로드의 수요에 맞춰 자동으로 수축/확장을 한다.
USE CASE: 트래픽이 제어가 안되거나, 예측이 안될 때, 워크로드가 급증할때 사용한다.
📌 프로비전모드 보다 비싸기 때문에 단기간에 필요시 사용해야한다.
프로비전 모드
사용자의 애플리케이션에 필요한 초당 읽기/쓰기 용량, 즉 프로비전 스루풋을 설정하는 것이다.
설정한 프로비전 스루풋을 처리하기 위한 토큰 WCU(쓰기 용량 유닛), RCU(읽기 용량 유닛)를 구매할 수 있다. 아이템을 읽는 읽기 방식에는 두가지가 있다.
종국적 일관성의 읽기
토큰의 소모가 강한 일관성의 읽기에 비해 절반이다.
하지만 강한 일관성의 읽기와 다르게 최근의 데이터를 반영하지 못하는 경우가 생긴다.
강한 일관성의 읽기
토큰의 소모가 종국적 일관성의 읽기에 비해 두배다.
하지만 종국적 일관성의 읽기와 다르게 최근의 데이터를 항상 반영한다.
예시로, 4KB크기의 1RCU라면 8KB를 읽기 위해 강한 일관성의 읽기는 2개의 토근을 구매해야 한다면, 종국적 일관성의 읽기는 1개의 토큰만 구매하면 된다.
Auto Scailing
EC2의 자동확장처럼 용량에 대해 정확한 예측이 안되는 경우에 최소,최대의 WCU,RCU를 정의해 활성화 비율에 따라 WCU,RCU를 늘리거나 줄이면서 변동하는 트래픽에 대응한다.
💡 온디맨드는 RCU,WCU를 정의할 필요가 없기때문에 온디맨드 모드와는 다르다.
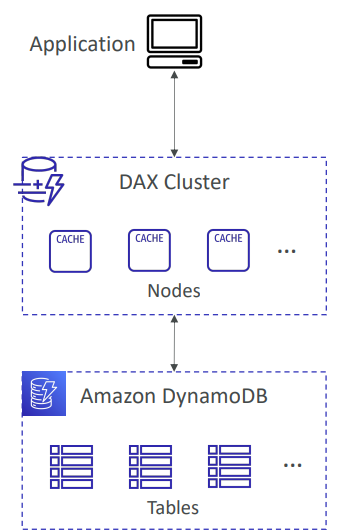
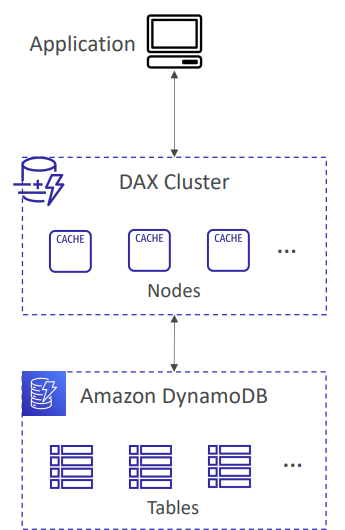
DAX
DynamoDB Accelerator(DAX)는 쉽게 말해 캐싱기능을 사용해 I/O의 성능을 향상시키는 것이다.
USE CASE 1 : 읽기트래픽이 급증하거나 읽기작업이 대규모인 경우에 성능이 저하되고 있을 때, 클러스터를 배포해 캐시노드를 여러개 배치하고 엔드포인트를 연결해 대규모의 트래픽을 분산시켜서 읽기/쓰기 성능을 향상시킨다.
USE CASE 2 : 대규모의 트래픽은 아니지만 자주 접근하는 데이터가 있을 때, 접근이 빈번한 데이터를 미리 캐시해 놓고 해당 데이터가 필요할 때 DB로 갈 필요없이 캐시노드에 쿼리하면 훨씬 더 빠르게 찾을 수 있다.
📌DynamoDB만 가능하고 코드 수정이 복잡하다.
가용성
DynamoDB는 기본적으로 Multi-AZ배포를 지원하고, Global Table을 사용하면 크로스 리전 복제까지 사용할 수 있기 때문에 가용성이 거의 100%에 가까운 수준이다.
마치며
이번 포스팅으로 DB에 대해서 다 다루어 보았다. DAX와 자주 비교되는 ElasticCache,Cloudfront에 대해서는 이번 포스팅이 아닌 추후에 다룰 예정이다. 다음 포스팅에서는 VPC,VPN,DC와 같은 AWS의 네트워크에 대해서 다루어 보겠다.
