
애드온
이전 블로그에서 말했다시피, 클라우드환경에서는 온프레미스와 다른점이 몇가지 존재한다.
- 네트워크
- 스토리지
- 스케일링
이러한 다른점을 해결하기 위해 애드온을 설치해야한다.
네트워크
클라우드환경(AWS)에서 ingress(L7)를 사용하기 위해서는 ALB(L7)를 사용해야하고, LoadBalancer(L4)를 사용하기 위해서는 NLB(L4)를 사용해야 한다. 따라서 ALB와 NLB를 사용하기위해 로드밸런서 컨트롤러 애드온이 필요하다.
# 이전 블로그에서 배포한 2번코드의 클러스터를 기반으로 한다.
# 해당 클러스터는 이미 애드온을 코드로 추가했기 때문에 설치만 해준다
helm repo add eks https://aws.github.io/eks-charts
# repo다운
helm repo update
# repo의 차트목록 업데이트
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=myeks --set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller
# 애드온 설치
helm list -A
# 확인
kubectl get all -n kube-system
# 파드와 서비스 등이 잘 설치되었는지 확인 EKS에서 NLB 생성
- 로드밸런서 컨트롤러 애드온을 설치했다면 Ingress or 로드밸런서 타입의 리소스를 NLB or ALB로 사용할 수 있다.
- 로드 밸런서 타입으로 서비스를 생성하였다면 아래의 명령어를 어노테이션에 추가해 NLB를 생성한다.
service.beta.kubernetes.io/aws-load-balancer-type: "external"
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: "ip"
# NLB 생성
service.beta.kubernetes.io/aws-load-balancer-scheme: "internet-facing"
# 코드 추가시 퍼블릭에 배치(외부에 노출), 추가 안할시 프라이빗에 배치 1 . 로드밸런서 타입의 서비스 생성
apiVersion: v1
kind: Service
metadata:
name: myapp-svc-nlb
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "external"
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: "ip"
#service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: "instance"
service.beta.kubernetes.io/aws-load-balancer-scheme: "internet-facing"
#service.beta.kubernetes.io/aws-load-balancer-scheme: "internal"
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: myapp-rs-> 어노테이션에서 ip타입인지 인스턴스 타입인지는 아직은 상관이없다.
2 . rs로 파드 생성
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs
template:
metadata:
labels:
app: myapp-rs
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
- NLB가 정상적으로 생성되어있는 것을 확인
- 브라우저에 로드밸런서 외부용IP를 입력하면 정상적으로 페이지가 뜬다
EKS에서 ALB생성
- Ingress리소스를 생성하였다면 아래의 명령어를 어노테이션에 추가해 ALB를 생성한다.
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/target-type: instance
# ALB 생성
alb.ingress.kubernetes.io/scheme: internet-facing
# 코트 추가시 퍼블릭에 배치(외부에 노출), 추가 안할시 프라이빗에 배치1 . Ingress 생성
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: myapp-ing
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
#alb.ingress.kubernetes.io/scheme: internal
alb.ingress.kubernetes.io/target-type: instance
#alb.ingress.kubernetes.io/target-type: ip
spec:
defaultBackend:
service:
name: myapp-svc-np
port:
number: 80
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: myapp-svc-np
port:
number: 80-> 어노테이션에서 ip타입인지 인스턴스 타입인지는 아직은 상관이없다.
2 . NodePort타입 서비스 생성
apiVersion: v1
kind: Service
metadata:
name: myapp-svc-np
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
selector:
app: myapp-rs3 . 파드 생성
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs
spec:
replicas: 3
selector:
matchLabels:
app: myapp-rs
template:
metadata:
labels:
app: myapp-rs
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080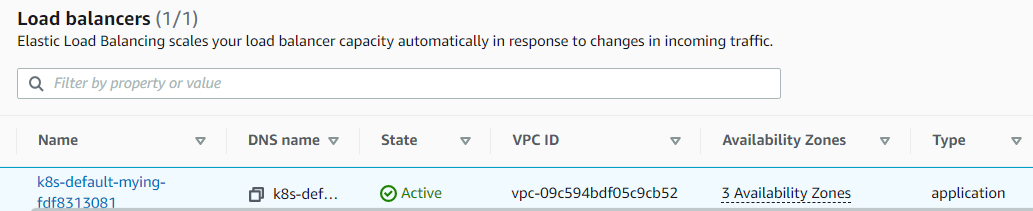
- ALB가 정상적으로 생성되어있는 것을 확인
- 마찬가지로 브라우저에 DNS name( =외부에 노출된 주소, 외부용IP)를 입력하면 정상적으로 페이지가 뜨는 것을 확인
스토리지
동적 프로비저닝을 하기 위해서는 pv의 프로파일 정보를 가지고 있는 스토리지 클래스가 필요하다.
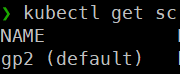
- 하지만 default로 존재하는 gp2 스토리지 클래스가 존재함에도 불구하고 pvc를 생성해보면 동적으로 pv를 생성하지 못한다.
- 이것은 EBS CSI Driver 애드온을 추가하지 않았기 때문이다.
eksctl create addon --name aws-ebs-csi-driver --cluster my-cluster --service-account-role-arn arn:aws:iam::111122223333:role/AmazonEKS_EBS_CSI_DriverRole --force
# EBS-CSI-Driver 생성 기본 형식
eksctl get iamserviceaccount --cluster myeks --name ebs-csi-controller-sa
# 서비스계정의 role-arn 확인
eksctl create addon --name aws-ebs-csi-driver --cluster myeks --service-account-role-arn < role-arn > --force
# 확인한 role-arn을 사용, 자신의 클러스터 이름 사용하여 애드온 생성
eksctl get addon --cluster myeks
# 생성한 애드온 확인 1 . pvc생성
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myapp-pvc-dynamic
spec:
accessModes:
- ReadWriteOnce # EBS 전용 접근 모드
resources:
requests:
storage: 1Gi
storageClassName: gp2 # default로 존재하는 스토리지 클래스- EBS는 ReadWriteOnce만 가능하다
- 클러스터를 생성함에 따라 자동으로 생성했던 gp2 스토리지 클래스를 사용한다.
2 . 파드 생성
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs-dynamic
spec:
replicas: 2
selector:
matchLabels:
app: myapp-rs-dynamic
template:
metadata:
labels:
app: myapp-rs-dynamic
spec:
containers:
- name: web-server
image: nginx:alpine
volumeMounts:
- name: web-content
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: web-content
persistentVolumeClaim:
claimName: myapp-pvc-dynamic
- 1G 짜리 gp2볼륨이 생성되어있는 것을 알 수 있다.
gp3타입의 볼륨 생성
1 . gp3 스토리지 클래스 생성
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: gp3
#annotations:
# storageclass.kubernetes.io/is-default-class: "true"
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer # 볼륨바인딩 모드
reclaimPolicy: Delete
parameters:
csi.storage.k8s.io/fstype: ext4
type: gp3
- WaitForFirstConsumer : 파드가 존재하지 않다면 pvc가 pv를 생성하지 않는다는 것
-> 쉽게말해 소비자(파드)가 존재하지 않다면 굳이 pv를 동적으로 생성해서 볼륨과 연결할 필요가없다. = 괜히 돈만 든다 - 이전에 온프레미스에서 한 동적 프로비저닝 실습은 볼륨바인딩모드가 'immediate'였다. 이것은 파드가 있든 없든 pvc가 pv를 생성해서 바운드시키고, pv뒤에 볼륨을 연결시킨다.
2 . pvc 생성
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myapp-pvc
spec:
accessModes:
- ReadWriteOnce # EBS전용 접근 모드
resources:
requests:
storage: 1Gi
storageClassName: gp3 # 위에서 만든 gp3스토리지 클래스 사용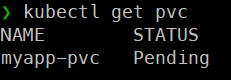
- 파드가 존재하지 않고, pvc만 생성했을 때 pvc가 pending상태가 되어있고, pv를 생성하지 못한다.
3 . 파드 생성
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp-pod
spec:
containers:
- name: web-server
image: nginx:alpine
volumeMounts:
- name: web-content
mountPath: /usr/share/nginx/html
ports:
- containerPort: 80
volumes:
- name: web-content
persistentVolumeClaim:
claimName: myapp-pvc
-> 파드를 생성후에 pvc, pv를 확인해보면 정상적으로 pvc가 작동하고 pv를 생성하여 pvc에 bound 시킨 것을 확인할 수 있다.

- 1G 짜리 gp3볼륨이 생성되어 있는 것을 확인
스케일링
- HPA와 같은 오토스케일링, top 커멘드를 통한 cpu, metric 상태 수집은 metric-server가 존재해야 한다.
- 이전에 온프레미스 실습은 metric-server 애드온을 추가했지만 현재 클러스터에는 metric-server가 존재하지 않아 HPA나 TOP커멘드를 할 수 없다.
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 메트릭 서버 애드온 설치 1 . 파드 생성
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-hpa
spec:
replicas: 3
selector:
matchLabels:
app: myapp-deploy-hpa
template:
metadata:
labels:
app: myapp-deploy-hpa
spec:
containers:
- name: myapp
image: ghcr.io/c1t1d0s7/go-myweb:alpine
resources:
requests:
cpu: 50m
memory: 5Mi
limits:
cpu: 100m
memory: 20Mi
ports:
- containerPort: 80802 . HPA 생성
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-cpu
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deploy-hpa
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
-> Metric-server를 설치했기 때문에 HPA가 정상적으로 작동하는 것을 확인할 수 있다.
Cluster Autoscaler
-
위에서 메트릭 서버를 설치해서 HPA(오토스케일링)를 하는 것은 파드에 대한 스케일링 이였다.
-
만약 파드가 계속 늘어나고 늘어나는 파드들은 계속해서
노드( =EC2 인스턴스)에 배치될 것이다. 파드의 request값이 존재하고 파드가 늘어남에 따라 노드가 더이상 request를 보장하지 못하게 된다. 이때는 노드를 스케일링 해야 한다. -
Node( =EC2 인스턴스)에 대한 스케일링은 수동으로 하는 방법과 Clsuter Autoscaler 애드온을 설치해서 자동으로 스케일링 하는 방법이 있다.
< 수동 스케일링 >
eksctl scale nodegroup --name mynodes-t3 --cluster myeks -N 3
# Nodegroup설정해서 3으로 스케일링
eksctl get nodegroups --cluster myeks
# 스케일링된 노드그룹 확인- NodeGroup = Autoscailing Group

- 오토스케일링 그룹이 존재하고 3개로 늘어난 것을 확인
- 이전에 클러스터를 배포할때 2번 코드에서 Max값을 3으로 지정했기 때문에 nodegroup을 4로 스케일링해도 늘어나지 않는다
< 자동 스케일링 >
- 수동으로 노드를 스케일링하는 것은 비효율적이고 비현실적이다.
- Cluster Autoscaler를 사용하여 각 노드가 가지고 있는 파드의
cpu or memory request값을 기준으로 metric을 자동으로 수집해서 노드를 스케일링 한다. - 만약 파드의 오토스케일링에 의해 파드가 계속 늘어나서 노드가 가진 리소스로는 더이상 늘어난 파드의 request값을 보장하지 못하게 된다면 자동으로 node를 scale up 할 것이다.
curl -O https://raw.githubusercontent.com/kubernetes/autoscaler/master/cluster-autoscaler/cloudprovider/aws/examples/cluster-autoscaler-autodiscover.yaml
# cluster autoscaler yaml파일 다운
vi cluster-autoscaler-autodiscover.yaml
# yaml파일 접속후 아래와 같이 수정 


kubectl create -f cluster-autoscaler-autodiscover.yaml
# cluster-autoscaler애드온 설치
# 코드에서 이미 service계정이 존재하기 때문에 apply로 설치하면 덮어씌워진다
kubectl logs -n kube-system cluster-autoscaler-758f7f9485-q9v6g
# 생성한 cluster-autoscaler 애드온 로그 확인
# warning이 존재하면 안된다1 . 파드 생성
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp-rs
spec:
replicas: 1
selector:
matchLabels:
app: myapp-rs
template:
metadata:
labels:
app: myapp-rs
spec:
containers:
- name: myweb
image: ghcr.io/c1t1d0s7/go-myweb:alpine
ports:
- containerPort: 8080
resources:
requests:
cpu: 200m
memory: 200M
limits:
cpu: 200m
memory: 200M- 간단하게 rs로 파드하나 생성한다.
- 노드에 어떠한 파드도 존재하지 않아 cluster-autoscaler에 의해 자동으로 min값인 1개로 노드를 줄인상태이다.
kubectl scale rs myapp-rs --replicas 7-> 파드의 개수를 7개로 늘린다.
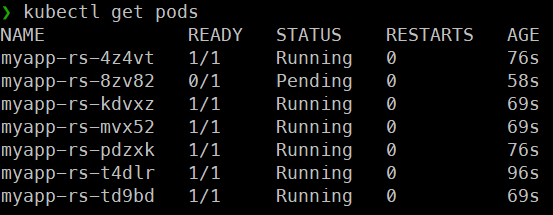
-> 하나의 노드에 6개의 파드가 배치되었고, 7번째 파드의 request값(200m)을 보장해줄수 있는 용량이 현재 노드(=EC2 인스턴스)에는 남아있지 않아 해당 파드를 생성하지 못하고 Pending상태가 된 것이다.

-> Pending상태인 파드의 로그를 보면 pod에 의해 trigger된
cluster-autoscaler가 node를 1->2로 증가시킨다는 것을 볼 수 있다.

-> 실제로 노드가 하나가 더 늘어난 것을 볼 수 있다.
= aws콘솔에 EC2 인스턴스에서 봐도 인스턴스의 개수가 2개인것을 확인
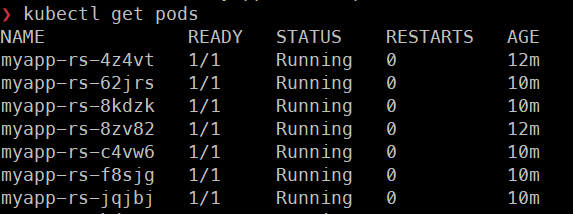
-> 새로 생성된 노드에 Pending상태였던 파드가 배치되면서 자동으로 Running상태가 된다.
CloudWatch

enableTypes: ["*"] # 모든 타입의 로그 - 클러스터를 생성할때 2번코드의 cloudwatch부분에 위의 명령어를 작성했었다. 즉 모든 타입의 로그들을 수집한다고 명시했었다.
= 위의 사진처럼 총 5가지 타입의 로그를 수집한다. - 이러한 종류의 로그들은 콘솔에 CLoudWatch에 들어가 로그 그룹에 들어가보면 수집된 로그파일로 존재하는 것을 확인
시각화 및 분석
- 이전에 온프레미스에서 prometheus(시각화,분석), EFK(로그수집)를 사용하여 데이터의 시각화를 하였다.
- 물론 prometheus나 EFK를 완벽히 대체하는 것은 아니지만 AWS에서도 Container Insights라는 데이터 시각화 도구가 있다.
ClusterName=myeks # 자신의 클러스터 이름
LogRegion=ap-northeast-2 # 자신의 리전
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
[[ ${FluentBitReadFromHead} = 'On' ]] && FluentBitReadFromTail='Off'|| FluentBitReadFromTail='On'
[[ -z ${FluentBitHttpPort} ]] && FluentBitHttpServer='Off' || FluentBitHttpServer='On'
curl https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml | sed 's/{{cluster_name}}/'${ClusterName}'/;s/{{region_name}}/'${LogRegion}'/;s/{{http_server_toggle}}/"'${FluentBitHttpServer}'"/;s/{{http_server_port}}/"'${FluentBitHttpPort}'"/;s/{{read_from_head}}/"'${FluentBitReadFromHead}'"/;s/{{read_from_tail}}/"'${FluentBitReadFromTail}'"/' | kubectl apply -f - - 컨테이너 인사이트 설치
kubectl get ns # amazon-cloudwatch 네임스페이스 생성된 것을 확인
kubectl get all -n amazon-cloudwatch - cloudwatch agent와 fluent-bit가 각각 파드, 데몬셋으로 생성되어 있는 것을 확인
- fluent-bit = 로그를 수집
- cloudwatch agent = 수집된 로그를 cloudwatch에 전달하는 역할
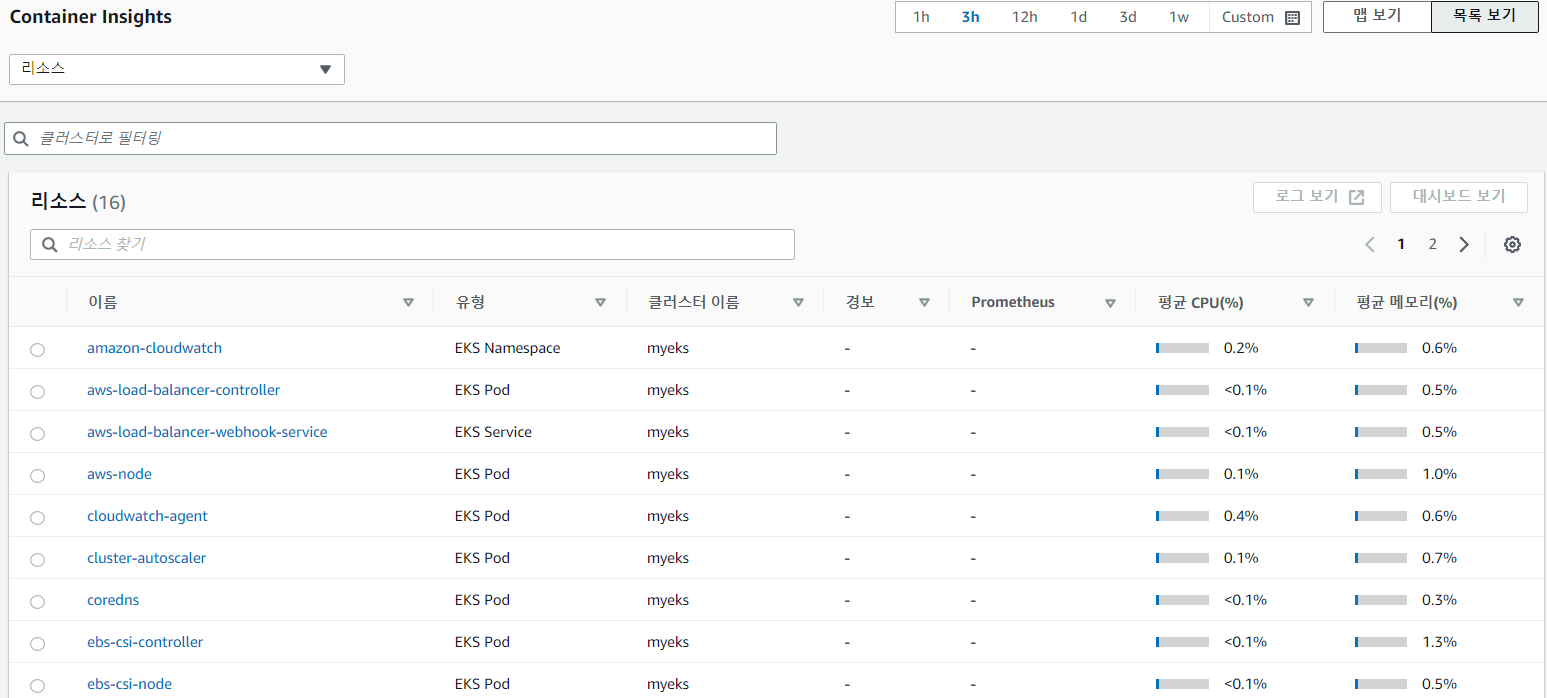
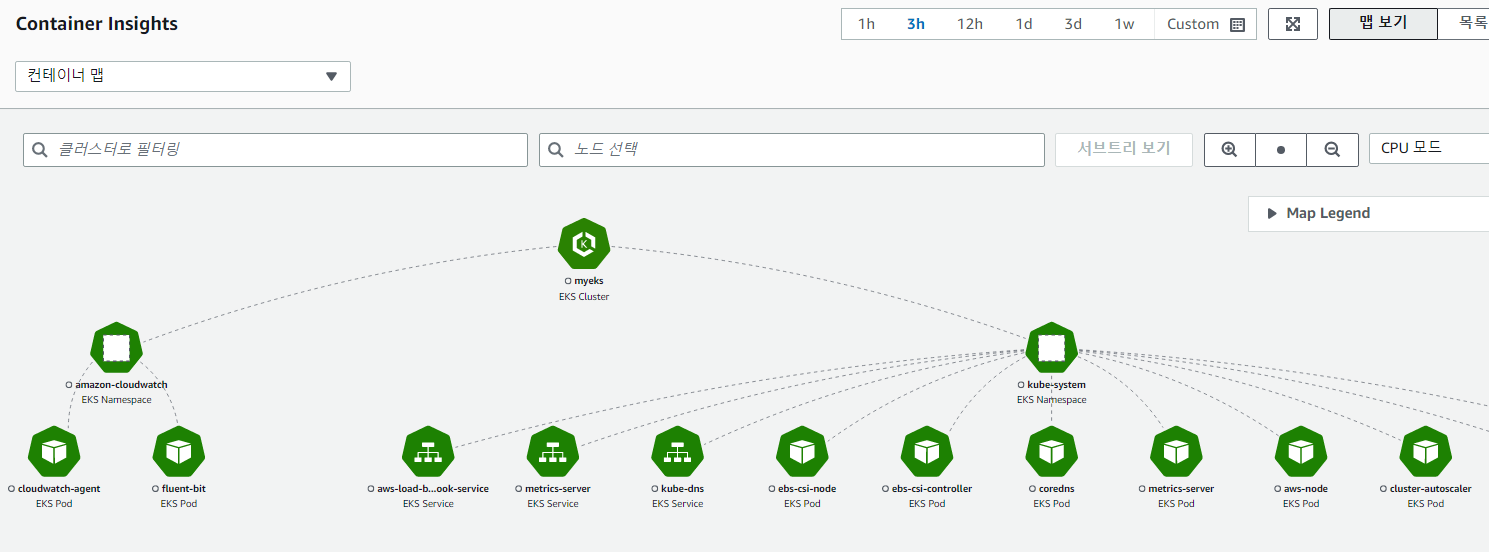
-> AWS 콘솔에서 CloudWatch의 Container Insights 항목에 들어가면 데이터를 수집해 분석 / 시각화 등의 되어 있는 것을 확인
RBAC
aws 콘솔에 IAM 사용자에서 새로운 사용자가 있다는 가정하에 eksuser1을 생성한다.
- 직접 정책 연결 선택 : AdministratorAccess
-> 모든 권한을 가진 가장 강력한 정책 부여
eksuser1의 사용자 보안 자격 증명에서 엑세스 키 생성 (CLI)
- CSV파일 다운
cd ~/.aws # credential과 config파일 존재
vi credentials # 이전에 aws configure을 통해 입력했던 엑세스 키/ 시크릿 키 정보 존재
[default]
aws_access_key_id = AKIXXX
aws_secret_access_key = aGbm8XXX
[eksuser1]
aws_access_key_id = AKIXXX
aws_secret_access_key = mVoLGXXX- 새로 생성한 eksuser1에 대해서 csv파일에 있는 액세스 키 / 시크릿 액세스 키 정보 추가
aws configure list-profiles # configure list 갱신
export AWS_PROFILE=eksuser1 # 계정을 eksuser1으로 변경
aws sts get-caller-identity --no-cli-pager # 변경이 잘되었는지 확인- 아직은 권한 설정이 안되었기 때문에 해당 계정으로는 어떤것도 할 수가 없다.
export AWS_PROFILE=default # default계정으로 다시 전환
aws sts get-caller-identity --no-cli-pager # 전환 확인
kubectl get cm -n kube-system aws-auth -o yaml > aws-auth.yaml- aws-auth 컨피그맵으로부터 권한 파일 생성
vi aws-auth.yaml # 권한 파일 접속 및 아래의 내용 추가
apiVersion: v1
data:
...
mapUsers: |
- userarn: <ARN>
username: eksuser1
groups:
- system:masters
...- < ARN >은 AWS 콘솔에 IAM 사용자에 eksuser1을 클릭하면 알
수 있다.
kubectl apply -f aws-auth.yaml
# 권한파일을 실행시킨다
export AWS_PROFILE=eksuser1 # 권한이 부여된 eksuser1으로 다시 전환
kubectl get nodes
kubectl create deploy myweb --image nginx
kubectl get deploy
kubectl get po
kubectl get clusterroles
kubectl delete deploy myweb
# 여러 작업들이 가능해진걸 확인
export AWS_PROFILE=default # 다시 default로 전환 - 여러명의 개발자가 있을 때 같은 환경(= 같은 클러스터)에서 서로 다른 계정으로 작업을 할 수 있게 된다.
- 각 계정마다 할 수 있는 권한을 달리할 수도 있다.
EKS Fargate
- AWS의 서버리스를 위한 제품
- EC2를 만들지 않고 바로 파드만 생성

- 클러스터를 생성할 때 2번 코드에서 Fargate Profiles을 지정했다.
- 쉽게말해, Fargate가 될 수 있는 조건을 명시한것이다.
= 명시한 조건의 namespace, label이 일치하면 EC2인스턴스가 아닌 Fargate로 파드를 생성
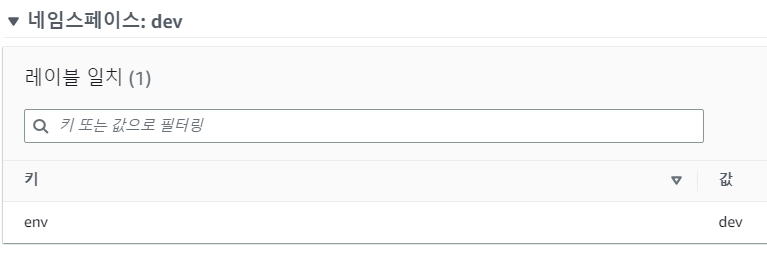
- 실제로 aws콘솔에 eks에 컴퓨팅에 Fargate profile에 가보면 위와같이 조건이 명시되어 있는 것을 볼 수 있다.
1 . 파드 생성
kubectl create ns dev # dev네임스페이스 생성
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: myapp
namespace: dev
spec:
replicas: 1
selector:
matchLabels:
env: dev
template:
metadata:
name: nginx
labels:
env: dev
spec:
containers:
- name: nginx
image: nginx:alpine
- Fargate 프로파일의 namespace오 label을 일치시켜 파드를 생성하면 일정시간 Pending 상태가 된다

- node를 확인해보면 fargate노드가 생성되어 있는 것을 확인
- 이건 아주 경량의 node(EC2 인스턴스,VM)를 띄워서 파드를 생성한 것이다.
- 즉, 노드이자 파드, 노드가 생성되지만 실제로는 노드가 아닌 것이다.
- AWS 콘솔에도 인스턴스(노드)가 보이지 나타나지 않는다
-> 따라서 인스턴스를 관리할 필요가 없고, 스케일링도 필요하지 않다.

- 경량의 Fargate 노드가 생성이 되면 자동으로 파드는 Running상태가 된다
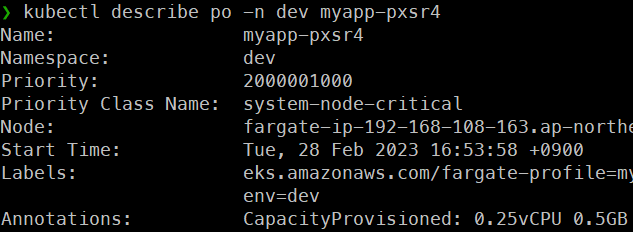
- Fargate로 생성된 파드의 describe를 보면 어노테이션에 CapacityProvisioned라는 항목이 있는데 해당 용량에 따라 비용이 부과되고 달라진다.
- 현재는 request / limits를 지정하기 않았기 때문에 자동으로 용량이 설정된 것이고, request/ limits를 지정함에 따라 비용을 조절해야 한다.
📗 fargate가 인스턴스보다 조금더 비싸다
📗 네트워크에서 NLB, ALB를 생성할 때 IP Target or Instance Target중 하나를 선택했었다.
- Instance Target을 선택하려면 파드가 반드시 EC2 인스턴스(노드)에 배치되어야 한다.
- Fargate를 사용해 파드를 배치하면 EC2 인스턴스(노드)가 존재하지 않기 때문에 IP Target을 선택해야 한다.
