
Kubernetes(k8s)
- 이번 쿠버네티스 교육은 1.24v으로 다룰 예정이다
- 쿠버네티스는 CNCF라는 재단에서 관리한다.
📗 CNCF 공식 사이트 - CNCF는 Linux의 산하 재단이다
- 단지 쿠버네티스만 사용하는 것이 아니라 그 외에도 필요에 따라 수많은 서비스들을 조합하여 하나의 인프라 환경을 구축한다
📗 CNCF 서비스들
- 쿠버네티스에서 제일 중요한 것은 아래의 예시처럼 YAML파일로 코드를 작성할 줄 아는 것이고 (= 코드화), 코드를 이해하는 것이다.

- 공식 문서들을 보고 공부하는 것을 추천
📒 쿠버네티스 영상 참조 1 , 쿠버네티스 영상 참조 2
쿠버네티스의 필요성

클러스터 : 여러개의 물리/논리적인 소프트/하드웨어를 묶어서 마치 하나의 시스템으로 관리한다
가상화 : 과거의 전통적인 배포방식에서 가상화방식이 도입되면서 하이퍼바이저를 통해 하나의 물리 pc에서 여러 서버를 배포할 수 있게 되었다. 물리pc 또는 가상머신이 호스트 pc가 되어 그 아래 여러 가상머신(서버) or 컨테이너(서버)를 두어 호스트가 관리하게 한다 (=클러스터, 컨테이너 오케스트레이션). 그러나 만약 기업의 규모가 커지고 실행해야할 어플리케이션이 늘어나면 그만큼 관리해야할 호스트 또한 늘어난다. 만일 수많은 호스트를 개별pc로 일일이 관리한다는 것은 인력과 비용이 많이 든다.
-> 이러한 이유로 호스트 아래 여러 가상머신/컨테이너를 두어 클러스터링 / 컨테이너 오케스트레이션을 통해 호스트가 여러 서버를 관리하는 컨셉과 비슷하게 여러 호스트를 마찬가지로 클러스터링 / 오케스트레이션을 통해 관리하기 위해 필요한 것이 쿠버네티스이다.
-> 쿠버네티스를 사용하면 여러 서버를 관리하는 호스트를 각각 관리하는 인력이 필요하지 않기 때문에 인력에 대한 비용과 관리 효율성을 높일 수 있다.
📒 하나의 호스트가 여러 컨테이너(서버)를 쉽게 관리하게 하는 것은 Docker도 가능하다. 하지만 Docker는 여러 호스트를 쉽게 관리하는 것은 하지 못한다.
( Docker에서 Docker Swarm이라는 것을 만들긴 했지만 이미 쿠버네티스가 시장을 점령한 상태 )
쿠버네티스 설치
1 . vagrant파일을 생성 후 c디스크에 적당한 디렉터리를 만들어 넣어놓는다
- vagrantfile 코드
- 메모장으로 파일을 생성하되, 확장자 txt는 지워야한다
- vagrant는 설치되어있어야 된다
2 . 터미널에 접속하여 해당 디렉터리에 cd로 접속
3 . 상태 확인 및 설치
Vagrant status # 상태확인
Vagrant up # 설치 4 . 컨트롤 노드(호스트 pc)에 접속
vagrant ssh kube-control15 . Kubespray을 이용한 설치
- 설치 참조, 해당 링크에 들어가 순서대로 코드를 실행하면 설치 완료
- kubeadm을 이용하여 설치할 수도 있다. 그러나 거의 일반적으로 kubespray를 이용하여 설치한다. 만일 CKA를 준비한다면 반드시 kubeadm을 알아야 한다.
6 . 최종 상태 확인
kubectl get pods -A-> 모든 컨테이너의 STATUS값이 모두 Running이여야 한다
📒 쿠버네티스는 환경 또는 필요에 따라 설치 방법이 다양하다
쿠버네티스 컴포넌트(아키텍처)
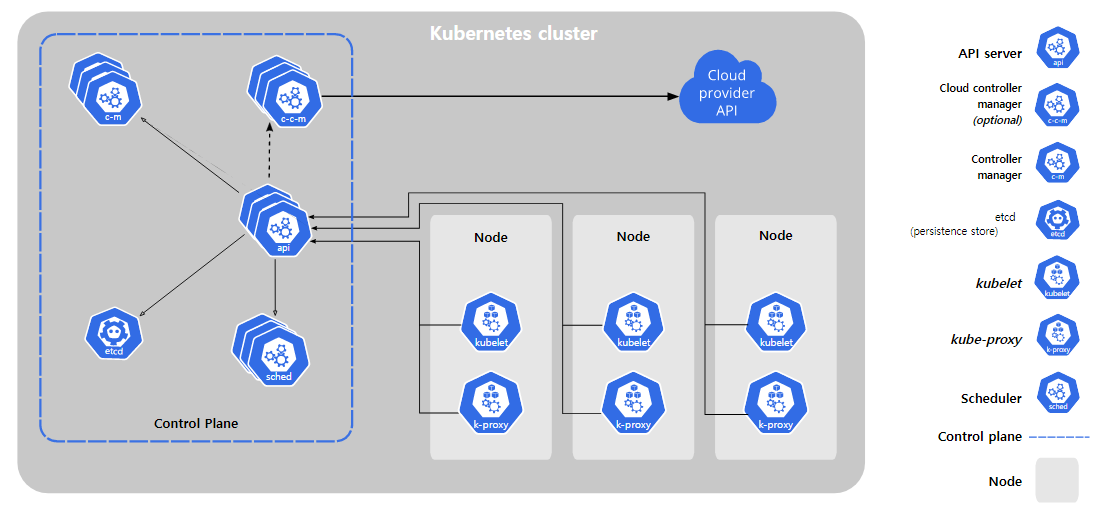
-
보통 일반적으로 VM을 이용하여 설치한다
-
Control Plane = Master
Node = Worker , Minions , Data Plane -
쿠버네티스를 배포하면 클러스터를 얻는다.
-
쿠버네티스 클러스터는 컨테이너화된 애플리케이션을 실행하는 노드라고 하는 워커 머신의 집합. 모든 클러스터는 최소 한 개의 워커 노드를 가진다.
-
워커 노드는 애플리케이션의 구성요소인 파드를 호스트한다. 컨트롤 플레인은 워커 노드와 클러스터 내 파드를 관리한다. 프로덕션 환경에서는 일반적으로 컨트롤 플레인이 여러 컴퓨터에 걸쳐 실행되고, 클러스터는 일반적으로 여러 노드를 실행하므로 내결함성과 고가용성이 제공된다.
📒 파드는 클러스터에서 실행 중인 컨테이너의 집합을 나타낸다 = 쉽게 말해 그냥 컨테이너다.
📒 쿠버네티스에서는 컨테이너보다는 파드라는 개념을 사용한다.
Control Plane 컴포넌트
< kube-apiserver >
- 쿠버네티스의 구성요소들은 서로 절대 통신하지 않고 api서버하고만 통신한다 .
- kubectl명령어를 통해 api서버에 어떠한 작업을 요청한다
- API 서버는 쿠버네티스 컨트롤 플레인의 프론트 엔드이다.
< etcd >
- 쿠버네티스의 모든 data는 etcd에 저장된다
- 반드시 etcd일 필요는 없다. DB로도 대체는 가능하다.
- api서버는 장애 발생시 복구하면 그만이지만 etcd는 데이터이기 떄문에 복구가 안된다. 따라서 백업 계획은 필수이다.
< kube-scheduler >
- 노드가 배정되지 않은 새로 생성된 파드를 감지하고, 실행할 노드를 선택하는 컨트롤 플레인 컴포넌트.
- 어떤 노드(컨테이너)에 어플리케이션을 배치할 것인지 결정
- 컨테이너를 실행시키는 요소
< kube-controller-manager >
- 컨트롤러 프로세스를 실행하는 컨트롤 플레인 컴포넌트.
- 논리적으로, 각 컨트롤러는 분리된 프로세스이지만, 복잡성을 낮추기 위해 모두 단일 바이너리로 컴파일되고 단일 프로세스 내에서 실행된다.
- 이들 컨트롤러는 다음을 포함한다.
- 노드 컨트롤러: 노드가 다운되었을 때 통지와 대응에 관한 책임을 가진다. = EC2
- 레플리케이션 컨트롤러: 시스템의 모든 레플리케이션 컨트롤러 오브젝트에 대해 알맞은 수의 파드들을 유지시켜 주는 책임을 가진다.
- 엔드포인트 컨트롤러: 엔드포인트 오브젝트를 채운다(즉, 서비스와 파드를 연결시킨다.) = 네트워크
- 서비스 어카운트 & 토큰 컨트롤러: 새로운 네임스페이스에 대한 기본 계정과 API 접근 토큰을 생성한다. = 접근제어
< cloud-controller-manager >
- 클라우드에 쿠버네티스를 올릴때 사용되는 요소이다
- 쿠버네티스에서 클라우드를 제어하는 것을 담당
- 쿠버네티스와 클라우드 간의 상호작용을 담당
- 로컬에서 쿠버네티스를 사용한다면 존재하지 않는 요소이다
📒 이들 요소중 단 하나라도 장애가 발생하면 쿠버네티스는 작동을 하지 않는다. 따라서 각 요소는 반드시 3중화를 통해 구성한다.
-> 그림을 잘 보면 세개로 겹쳐있는 것을 볼 수 있다.
-> 클러스터로 다중화를 구성할 때는 짝수개로는 구성하지 않는다
-> Control Plane도 3중화한다.
Node 컴포넌트
노드 컴포넌트는 동작 중인 파드를 유지시키고 쿠버네티스 런타임 환경을 제공하며, 모든 노드 상에서 동작한다
Container Runtime Interface (CRI) = 쿠버네티스 런타임 환경
- Docker등이 있다
< kubelet >
- 클러스터의 각 노드에서 실행되는 에이전트. Kubelet은 파드에서 컨테이너가 확실하게 동작하도록 관리한다.
- kubectl은 kubelet에게 요청을 하지 않는다
- Kubelet은 다양한 메커니즘을 통해 제공된 파드 스펙(PodSpec)의 집합을 받아서 컨테이너가 해당 파드 스펙에 따라 건강하게 동작하는 것을 확실히 한다. Kubelet은 쿠버네티스를 통해 생성되지 않는 컨테이너는 관리하지 않는다.
< kube-proxy >
- kube-proxy는 클러스터의 각 노드에서 실행되는 네트워크 프록시로, 쿠버네티스의 서비스 개념의 구현부이다.
- kube-proxy는 노드의 네트워크 규칙을 유지 관리한다. 이 네트워크 규칙이 내부 네트워크 세션이나 클러스터 바깥에서 파드로 네트워크 통신을 할 수 있도록 해준다.
- kube-proxy는 운영 체제에 가용한 패킷 필터링 계층이 있는 경우, 이를 사용한다. 그렇지 않으면, kube-proxy는 트래픽 자체를 포워드(forward)한다.
sudo ss -tnlp # kube-proxy 확인 가능
애드온 ( = 옵션)
애드온은 쿠버네티스 리소스(데몬셋, 디플로이먼트 등)를 이용하여 클러스터 기능을 구현한다. 이들은 클러스터 단위의 기능을 제공하기 때문에 애드온에 대한 네임스페이스 리소스는 kube-system 네임스페이스에 속한다.
< DNS >
- 애드온들이 옵션이기 때문에 반드시 필요로 하지 않지만 DNS는 많은 예시에서 필요로하고 없으면 관리가 힘들어지기 때문에 모든 쿠버네티스 클러스터는 클러스터 DNS를 갖추어야 한다
- 클러스터 DNS는 구성환경 내 다른 DNS 서버와 더불어, 쿠버네티스 서비스를 위해 DNS 레코드를 제공해주는 DNS 서버다.
- 쿠버네티스에 의해 구동되는 컨테이너는 DNS 쿼리에서 이 DNS 서버를 자동으로 포함한다. 약간 자체 DNS서버 같은 느낌이다.
< 웹 UI (대시보드) >
- 대시보드는 쿠버네티스 클러스터를 위한 범용의 웹 기반 UI다. 사용자가 클러스터 자체뿐만 아니라, 클러스터에서 동작하는 애플리케이션에 대한 관리와 문제 해결을 할 수 있도록 해준다.
- 보안상의 이유로 인해 권장하는 요소가 아니다.
< 컨테이너 리소스 모니터링 >
- 컨테이너 리소스 모니터링은 중앙 데이터베이스 내의 컨테이너들에 대한 포괄적인 시계열 매트릭스를 기록하고 그 데이터를 열람하기 위한 UI를 제공해 준다.
- 기업에서 반드시 구성하는 요소중 하나이다.
< 클러스터-레벨 로깅 >
- 클러스터-레벨 로깅 메커니즘은 검색/열람 인터페이스와 함께 중앙 로그 저장소에 컨테이너 로그를 저장하는 책임을 진다.
- 기업에서 반드시 구성하는 요소중 하나이다.
컴포넌트 확인
kubectl get pods -A # 컨테이너들을 확인할 수 있다
kubectl get pods -A -o wide # 컨테이너들을 확인할 수 있다-> 위의 아키텍처를 보면 그림에서는 생략되었지만 사실 명령어로 알 수 있다시피 control plane도 kube-proxy를 가지고 있다.
-> 즉 control plane도 사실 node의 기능을 가지고 있다.
-> control plane은 node를 관리하는 대장느낌이라면 node는 각 컨테이너를 실행하는 병사다.
systemctl status etcd
systemctl status kubelet -> etcd, kubelet은 컨테이너가 아닌 서비스이기 때문에 kubectl이 아닌 systemd로 확인
추가정보
- 컨테이너는 stateless, 즉 상태가 없기 때문에 항상 일정하다.
따라서 이미지를 통해 컨테이너를 생성할 수 있는 것이다. - 컨테이너 = Immutable Infrastructure
- 컨테이너는 stateless이지만 데이터는 state가 존재한다.
따라서 컨테이너에 데이터를 저장하고 컨테이너를 없애면 데이터도 같이 날아간다. 하지만 데이터는 매우중요하다. 따라서 이러한 데이터를 저장하기 위해서 컨테이너에 Volume을 사용하는 것이다.
kubectl api-resources- API서버가 가지고 있는 리소스의 종류를 볼 수 있다.
= 즉 만들수 있는 리소스의 리스트를 알 수 있다
