
인프라 구축
이전 인프라 구축에 이어서 오늘도 인프라 구축을 작업할 것이다.
- 오늘의 목표는 스토리지 구축, HPA, EC2 AutoScailing 구축이다.
클러스터 오브젝트 생성
스토리지
-
여러 AZ에 배포된 EC2인스턴스들이 동시적으로 하나의 스토리지에 접근해서 읽기/쓰기가 가능하게 하기 위해 EFS스토리지를 사용하는 것으로 결정했다.
📒 EBS스토리지는 AZ단위에서만 작업이 가능하다면, EFS는 AZ가 다른 인스턴스들도 하나의 스토리지에 접근이 가능하다. 물론 비용은 EBS보다 비싸다. -
이전 블로그에서 EFS스토리지 구축을 일부 하였고, EFS-CSI 드라이버와 이 드라이버를 이용하여 스토리지 클래스를 구축하는 작업을 하였다.
IAM정책 및 역할을 생성해서 이것을 부착한 서비스 계정을 생성한뒤 EFS-CSI 드라이버 설치과정에서 이 서비스 계정을 등록하여야 했다. 문제는 그냥 kubectl로 EFS-CSI드라이버를 설치해버린것이다. 이후 스토리지클래스와 PVC를 생성해서 ArgoCD에 배포를 해봤지만 당연히 접근권한이 존재하지 않아 EFS에 연동이 되지 않았다.
-> 이것을 해결하기 위해 클러스터를 다시 배포하였고, 클러스터 배포 YAML파일에서 IAM OIDC를 추가하여 EFS-CSI에 권한이 있는 서비스 계정을 생성하였다.
# IAM OIDC & Service Account
iam:
withOIDC: true
serviceAccounts:
. . .
- metadata:
name: efs-csi-controller-sa
namespace: kube-system
wellKnownPolicies:
efsCSIController: true
. . . - efs-csi에 권한(IAM 정책, IAM 역할)이 있는 서비스 계정 생성
- 해당 코드를 추가후 클러스터를 다시 배포하여 AWS콘솔에서 EFS스토리지가 생성되어 있는 것을 확인
helm repo add aws-efs-csi-driver https://kubernetes-sigs.github.io/aws-efs-csi-driver/
helm repo update
helm upgrade -i aws-efs-csi-driver aws-efs-csi-driver/aws-efs-csi-driver \
--namespace kube-system \
--set image.repository=602401143452.dkr.ecr.ap-northeast-2.amazonaws.com/eks/aws-efs-csi-driver \
--set controller.serviceAccount.create=false \
--set controller.serviceAccount.name=efs-csi-controller-sa- 위에서 생성한 서비스 계정을 이용하여 EFS-CSI 드라이버를 설치한다.
vpc_id=$(aws eks describe-cluster \
--name finalproject \
--query "cluster.resourcesVpcConfig.vpcId" \
--output text)
cidr_range=$(aws ec2 describe-vpcs \
--vpc-ids $vpc_id \
--query "Vpcs[].CidrBlock" \
--output text \
--region ap-northeast-2)- 이후 EFS가 클러스터와 통신하기 위해서는 보안그룹이 필요한데 이 보안그룹을 생성하기 위해 클러스터의 vpc_id와 cidr_range를 변수로 저장해놓는다.

- AWS 콘솔에서 보안그룹 생성을 클릭해 echo "$vpc_id" 로 나온 vpc_id에 해당하는 vpc를 선택하고, 인바운드 규칙을 편집하여 유형에 NFS(TCP ,2049)선택 및 소스에는 echo "$cidr_range" 로 나온 ip값을 추가한다.
aws ec2 describe-subnets \
--filters "Name=vpc-id,Values=$vpc_id" \
--query 'Subnets[*].{SubnetId: SubnetId,AvailabilityZone: AvailabilityZone,CidrBlock: CidrBlock}' \
--output table- 쉘에서 클러스터의 EC2인스턴스들의 서브넷 ID와 VPC ID를 출력한다.
kubectl get nodes- 마찬가지로 EC2인스턴스의 IP를 출력한다
- 출력된 인스턴스의 IP를 위의 테이블형태로 나온 CIDR과 비교해서 인스턴스가 어떤 서브넷에 포함되어 있는지 확인한다.
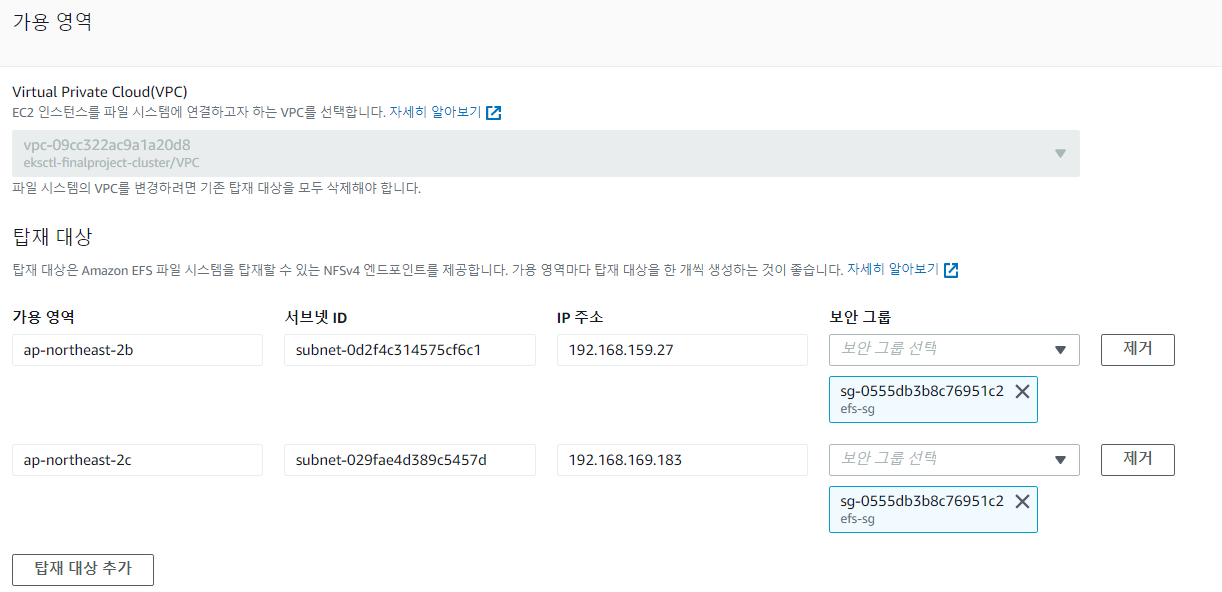
- 어떤 서브넷에 포함되어있는지 알았다면 서브넷 ID를 알 수 있고,
AWS콘솔에서 EFS에 들어가 네트워크를 Mount할 때 서브넷 ID에 해당하는 AZ를 선택한다. 해당 가용영역의 서브넷에 위에서 생성했던 클러스터에 접속가능한 보안그룹을 부착한다. - EFS는 여러 AZ에 존재하는 모든 인스턴스가 동시에 접속할 수 있기 때문에 인스턴스가 존재하는 모든 서브넷의 가용영역과 서브넷 ID, 보안그룹을 선택해 Mount한다.
스토리지 클래스 생성
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: efs-sc
parameters:
directoryPerms: "700"
fileSystemId: fs-07b34570f35c4cc5d # 위에서 생성한 EFS의 ID추가
provisioningMode: efs-ap
provisioner: efs.csi.aws.com # EFS-CSI 드라이버 선택
reclaimPolicy: Delete
volumeBindingMode: Immediate- EFS-CSI 드라이버를 이용하여 스토리지 클래스를 생성한다.
PVC 생성
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: efs-pvc
namespace: default
spec:
accessModes:
- ReadWriteMany
storageClassName: efs-sc # 위에서 생성한 스토리지 클래스
resources:
requests:
storage: 1Gi- 위에서 생성한 스토리지 클래스를 이용하여 PVC생성
backend - Deployment 수정
apiVersion: apps/v1
kind: Deployment
metadata:
name: back-deploy
spec:
selector:
matchLabels:
tier: backend
replicas: 2
template:
metadata:
labels:
tier: backend
spec:
volumes: # 위에서 생성한 PVC를 이용하여 볼륨 생성
- name: efs-volume
persistentVolumeClaim:
claimName: efs-pvc
containers:
- name: back-app
image: suhwan11/hello-world:49
ports:
- containerPort: 8080
protocol: TCP
volumeMounts: # 생성한 볼륨 마운트
- name: efs-volume
mountPath: /data
resources:
requests:
cpu: 200m
memory: 200M-
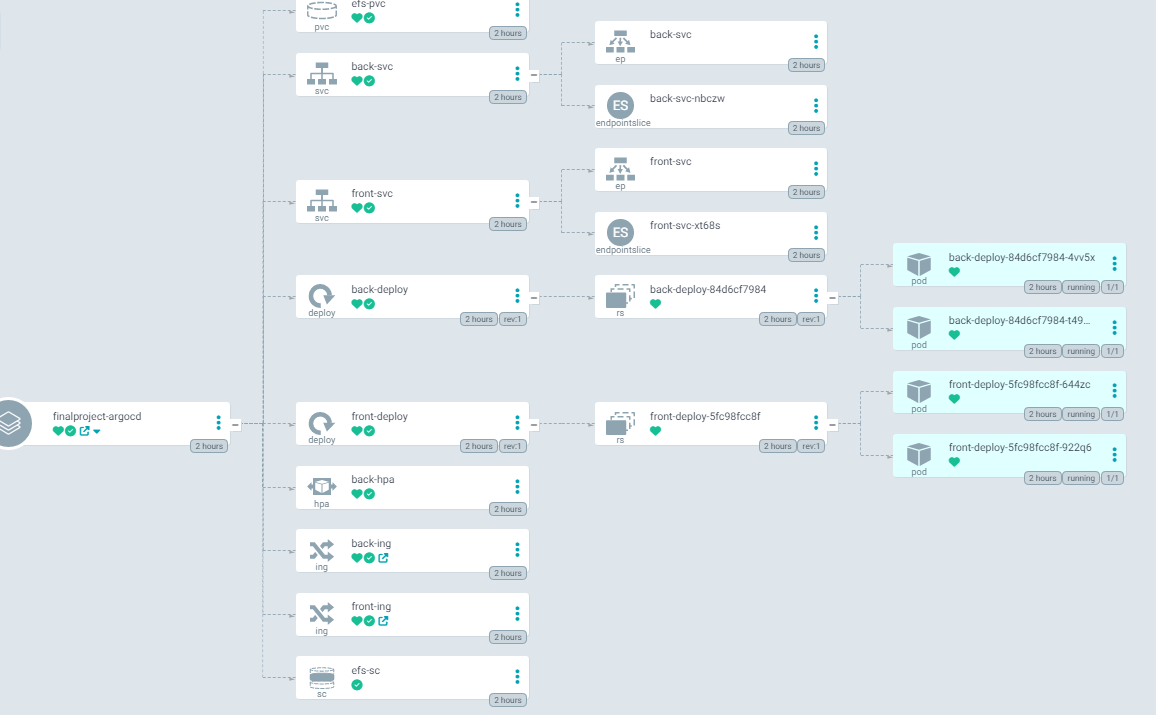
스토리지 클래스 , PVC, 수정한 Deployment를 ArgoCD를 이용해서 배포하면 아래와 같이 정상적으로 작동하는 것을 확인
-
다른 AZ에 노드가 두개 있고 각 노드에는 디플로이먼트로 배포된 백엔드 파드가 각각 하나씩 있다.
kubectl exec -it < 파드이름 > -- sh cd /data cat > test.txt # text입력 후 exit 다른 노드의 파드에 접속 kubectl exec -it < 다른 노드의 파드이름 > -- sh cd /data -
위의 파드에서 data디렉터리에 작성했던 test.txt파일이 다른 AZ에 있는 노드의 파드에 접속하여 확인해보면 data 디렉터리에 test.txt파일이 공유되어 존재하는 것을 확인할 수 있다.
HPA
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: back-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: back-deploy # backend Deployment와 연결
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70- HPA를 사용하기 위해서는 Metrics server 애드온을 설치하여야 한다.
- Deployment에 request값을 설정해줘야 한다.
Cluster Autoscaler
- HPA로 파드의 CPU 평균 사용률이 높아짐에 따라 노드(= EC2인스턴스)에 배치되는 파드의 개수를 늘렸다면, 파드의 개수가 늘어남에 따라 노드가 자신의 자원을 가지고 늘어난 파드의 request값을 보장해준다 .
- 이때 늘어난 파드의 request값을 더이상 노드가 보장해주지못한다면 노드를 늘려서 새로운 노드에 파드를 배치해야한다.
- 이것을 위해 Auto Scailing Group을 생성한다.
- EC2인스턴스의 Auto Scailing이 가능하게 하기 위해서는 Cluster Autoscaler 애드온을 설치하여야 한다.
- min 값은 2 , max 값은 5 , desired 값은 2로 지정하였다.
- 즉, 현재 배포된 클러스터의 노드의 개수는 2개이고, 2개이하로는 scale down되지 않게 설정하였으면, 최대 늘어날 수 있는 노드는 5개로 설정하였다.
느낀점
여러 사람이 동일한 클러스터에 연결해서 작업을 하다보니 한 사람이 말을 안하고 어떤 것을 지우거나 설치하게 되면, 다른 사람이 작업할때 인지를 못하고 중복으로 작업하거나, 서비스가 꼬여버려서 더이상 클러스터를 이용할 수 없게 되었다. 따라서 하나의 클러스터의 동일한 환경에서 작업을 하되, 유저 계정을 각각 생성해서 RBAC을 통해 권한을 나누어 작업을 하면 여러 사람이 동일한 환경에서 작업을 할 수 있으면서 동시에 각자의 구역을 나누어서 작업을 할 수 있을 거 같아서 훨씬 효율적일 것이다.
