
식사하는 철학자
다섯 명의 철학자가 원형 테이블에 앉아 있고, 각 철학자 앞에는 젓가락이 있고, 두 개의 젓가락을 사용하여 음식을 먹습니다. 그러나 각 철학자 사이에는 한 개의 젓가락만 있습니다. 따라서 철학자는 왼쪽이나 오른쪽에 위치한 젓가락을 기다려야 할 수 있습니다. 이로 인해 데드락(deadlock) 상태에 빠져버릴 수 있습니다. 이 상황을 피하려면 어떻게 해야할까요?
네 그렇습니다. 이번 글에서는 데드락을 해결하기 위한 방법 중 스핀락, 뮤텍스, 세마포어에 대해 알아보고자 합니다.
Critical Section(임계영역)
동시성 프로그래밍에서 공유되고 있는 리소스에 대한 접근은 알 수 없는 문제를 일으키거나 잘못된 동작을 야기할 수 있습니다. 그렇기에 동시에 접근하지 않도록 보호하는 작업이 필요합니다.
이를 해결하기 위한 방법 중 하나가 임계 영역(Critical Section) 이라고 합니다.
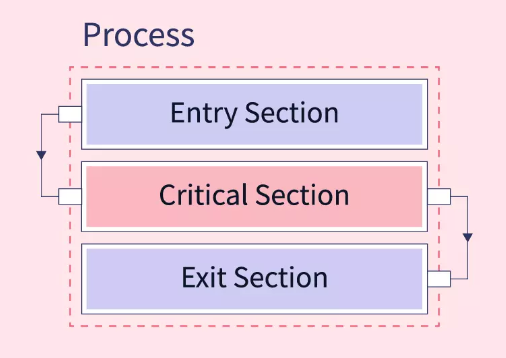
특정 프로세스가 임계 영역에 진입하게 되면 다른 프로세스는 일시 중단되어 프로세스가 끝나기를 기다립니다. 이처럼 동시에 발생하지 않고 하나의 프로세스와 스레드만 동작하는 것을 상호배제(mutual exclusion) 라고 부릅니다.
이 임계영역의 구현에는 스핀락, 뮤텍스, 세마포어가 있습니다. 말이 조금 이상할 수 있지만 스핀락, 뮤텍스, 세마포어를 이용하여 임계영역(상호배제한 구역)을 구현할 수 있다는 의미입니다.
스핀락
스핀락은 임계 영역(critical section)에 진입할 때, 다른 스레드가 임계영역을 사용중이라면 해당 스레드가 완료될 때까지 무한정 기다리는 동기화 기법입니다. 이렇게 반복적으로 기다리는 것을 Busy Waiting이라고 합니다.

스핀락 : unlock해줄때까지 안나갈거야~!!!!!
스핀락의 구현
class SpinLock {
private:
std::atomic<bool> locked = false;
public:
void lock() {
bool expected = false;
//locked가 false라면 lock을 true로 변경
//이후 다른 쓰레드가 lock() 호출 시, 이미 locked가 true이기에 unlock()호출 전까지 무한루프
while (!locked.compare_exchange_strong(expected, true)) {
expected = false;
}
}
void unlock() {
locked.store(false);
}
};스핀락에선 모든 쓰레드들이 원자적으로 처리해야 하기때문에 이부분을 관리해주는 bool 변수를 atomic<bool>로 선언해줘야 합니다.
원자적이라는 의미는 CPU가 명령어를 1개로만 처리하는 것으로 중간에 다른 쓰레드가 끼어들 수 없는 연산을 말합니다.
변수가 변경되었다면 '변수가 변경되었다와 변경되지 않았다'의 2가지의 속성만 존재하는 것을 뜻하고 이를 원자적(atomic) 이라고 합니다.
compare_exchange_strong
compare_exchange_strong는 원자연산 함수 중 하나로 원자적인 비교-교환(Compare-And-Exchange, CAS) 연산을 수행합니다.
간단하게 말하자면 첫번째 파라미터와 일치하는지 확인하고 일치하면 두번째 파라미터로 변수를 바꿉니다. 세번째 파라미터로는 std::memory_order라는 메모리 순서 지정자가 있지만 여기서 다루게되면 글이 너무 길어지기때문에 이후에 추가적으로 다루도록 하겠습니다.
기본 지정자는 std::memory_order_seq_cst로 모든 쓰레드에서 모든 시점에 동일한 값을 관찰할 수 있게 해주는 지정자로 강력한 일관성을 보장해줍니다. 물론 그만큼 비싼 연산입니다.
compare_exchange_strong대신 atomic_flag와 test_and_set으로도 동일하게 스핀락을 만들 수 있습니다.
하지만 스핀락은 Busy Waiting의 형태를 띄기 때문에 CPU의 자원을 지속적으로 소모한다는 단점이 있습니다.
이를 개선한 뮤텍스 방식의 구현방법이 있습니다.
뮤텍스
뮤텍스는 스핀락과 다르게 임계영역에 접근 할 수 없다면 해당 스레드를 대기시키는 동기화 기법입니다. 다른말로 스레드를 블록시키는 방식입니다. 일반적인 상황에서는 스핀락보다 뮤텍스가 더 안정적이고 효율적으로 사용할 수 있습니다.

뮤텍스의 구현
class Mutex {
public:
void lock() {
while (flag.test_and_set(std::memory_order_acquire)) {
std::this_thread::yield(); // busy wait 방지를 위해 yield 사용
}
}
void unlock() {
flag.clear(std::memory_order_release); // 락을 해제
}
private:
std::atomic_flag flag = ATOMIC_FLAG_INIT;
};std::this_thread::yield()
std::this_thread::yield()는 해당 쓰레드가 Busy Waiting상태에 있는 경우 스레드의 실행을 다시 예약해주는 함수로 다른 쓰레드가 실행할 수 있도록 해줍니다. 이때 쓰레드가 깨어나게되면 Context Switching이 발생합니다.
간단하게 말하면 스레드 스케줄러에게 "저는 다른 스레드가 실행되도록 기회를 주는 것이 좋을 거 같아요!" 라고 알려주는 것입니다.
그렇기 때문에 실제 스레드의 전환이 무조건적을 보장되는 것은 아닙니다. 실제 전환은 OS가 결정합니다.
세마포어
세마포어는 동시에 여러 스레드가 접근할 수 있는 공유 자원의 수를 제한하는 동기화 기법입니다. 무슨말이냐면 뮤텍스가 하나의 스레드만 임계영역에 접근할 수 있었다면 세마포어는 하나 이상의 스레드가 임계영역에 접근할 수 있는 기법입니다.
세마포어의 구현
class Semaphore{
public:
Semaphore(int count = 0) : count_(count) {}
void wait() {
while (count_.load() == 0) {
std::this_thread::yield(); // busy wait 방지를 위해 yield 사용
}
count_.fetch_sub(1);
}
void signal() {
count_.fetch_add(1);
}
private:
std::atomic<int> count_; // 접근 가능한 쓰레드의 갯수
};이진 세마포어 vs 뮤텍스
세마포어에는 이진(binary) 세마포어와 계수(counting) 세마포어가 있는데, 이진 세마포어와 뮤텍스는 비슷해보이면서도 차이점이 있습니다.
위 세마포어 코드에는 우선순위 역전과 같은 추가사항을 구현하지 않았지만 실제로 이진 세마포어에서는 우선순위가 높은 스레드가 wait와 signal을 가로챌 수 있다고 나와 있습니다.
반면 뮤텍스는 priority inheritance 속성을 가지기 때문에 우선순위 역전 현상이 발생하지 않습니다.
그렇기 때문에 이진 세마포어는 여러 개의 쓰레드가 세마포어를 획득하는 경우가 생길 수 있고 뮤텍스는 그렇지 않습니다.
마무리하며
멀티스레드 환경에서 자주다루게 되는 내용이다보니 이해하기 어려운 부분이 많았습니다. 뿐만 아니라 현직자 입장에서 작성하는 글이 아니다보니 코드에 문제가 될 요소도 많다고 생각합니다. 그러니 혹시나 문제가 될 요소가 있다면 언제든지 알려주시면 감사하겠습니다!
긴 글 읽어주셔서 감사합니다. 게임 개발에 빠져살고있는 내잔이였습니다.
참고자료
https://youtu.be/gTkvX2Awj6g
https://modoocode.com/271
https://www.geeksforgeeks.org/difference-between-binary-semaphore-and-mutex/
