
Voice Palette
🎤 음성 데이터를 활용한 목소리 유형 자가진단 서비스
About
👥 팀 구성 : 프론트엔드 2, 백엔드 1, 디자이너 1
🙉 내 역할 : 프론트엔드 및 팀 리더
📆 기간 : 2024.10.19(토) ~ 2024.10.20(일)
💻 기술 스택 : React, Typescript, FastAPI, MySQL

링크
Preview



참가 전
참가이유
최근 개발이 다소 지루하게 느껴졌고, 기존 프로젝트나 외주 개발로는 채워지지 않는 무언가가 있다고 느꼈다.
그래서 새로운 자극을 위해 전국의 사람들과 겨뤄볼 기회를 찾던 중, SPARCS 과학 해커톤이 눈에 띄었다.

SPARCS는 카이스트 총학생회 산하 단체로, 이전에도 여러 해커톤을 개최했지만 이번에는 대전 사이언스 페스티벌에서 해커톤 기간 동안 제작한 서비스로 직접 부스를 열어 일반 시민들의 반응을 볼 수 있는 좋은 기회라고 생각했다.
새로운 경험과 자극이 될 것 같아 기대를 가지고 지원하게 되었다.
팀 빌딩
개인 지원이나 4인 팀 지원이 가능했는데, 이전 SPARCS 해커톤에 참가했던 지인으로부터 참가자들의 스펙이 매우 좋았다는 이야기를 들어 팀 지원이 합격에 유리할 것 같아 4인 팀으로 신청하기로 결정했다.
그런데 팀을 꾸리는 과정에서 어려움이 있었다.
이상적인 팀 구성을 생각하면 기획자 1명, 디자이너 1명, 프론트엔드 1명, 백엔드 1명이 좋지만 주변에 개발자는 많아도 기획자나 디자이너 인맥이 부족해 고민했다.
그래서 결국 기획자는 섭외하지 않고, 디자이너는 예전에 교양 수업 팀 프로젝트를 같이 했던 분에게 떨리는 마음으로 연락해봤다..
디자이너 분에게 함께하자고 했을 때 당연히 거절할 줄 알았는데, 잠시 고민하시더니 같이 하겠다고 해서 놀랐다!!
그렇게 우리 팀은 디자이너 1명, 프론트엔드 2명, 백엔드 1명으로 구성되었다.
아이디어 기획
본 대회 전에 미리 주제 발표가 있었다.

과학을 일반인도 쉽게 접할 수 있도록 하는 소프트웨어를 개발하는 것이 목표라는 이야기를 들었을 때, 나 또한 과학이 어렵다고 느껴왔기에 흥미로웠다.
우리 팀은 대회 3일 전에 아이디어를 구체화하기 위해 약 1시간 반 정도 회의를 진행했다.
처음에는 다소 막막했지만, 대화를 이어가며 점차 방향을 잡아나갈 수 있었다.
-
브레인스토밍
-
최종 아이디어 기획

참가 전에 최종 아이디어로 사람들의 목소리 파형을 분석하여 퍼스널 컬러처럼 목소리의 특징을 분류하는 서비스를 기획했다.
이 서비스는 유명인의 파형과 비교해 비슷한 목소리 유형도 찾아주고, 목소리의 단점을 캐치해 개선할 수 있는 솔루션 피드백도 제공하는 것으로 기획했다.
우리 팀 모두가 이 아이디어에 꽂혀 만장일치로 동의했다!!
해커톤 시작
1일차
대전 컨벤션센터에서 낮 12시부터 등록을 시작했기 때문에 아침 6시 반에 일어나 기차를 타고 팀원들과 함께 대전으로 출발했다.

시작 전에 팀원들과 와이어프레임을 점검하며 필요한 기능들을 확정 지은 후 본 행사가 시작되었다.
초반에는 디자이너가 기획을 바탕으로 본격적인 디자인 작업에 들어갔고, 개발자들은 PoC 과정에 집중했다.
하지만 이 과정에서 목소리의 파동만으로는 원하는 특징을 뽑아낼 수 없다는 문제에 부딪혔다.
해결 방법을 찾기 위해 데이터 종류를 탐색하던 중에 MFCC(Mel-Frequency Cepstral Coefficient)라는 목소리의 특징을 추출할 수 있는 데이터를 발견하게 되었다.
MFCC란?
MFCC는 오디오 신호에서 추출할 수 있는 feature인데, 소리의 고유한 특징을 나타내는 수치이다.
주로 음성 인식, 화자 인식, 음성 합성, 음악 장르 분류 등 오디오 도메인의 문제를 해결하는 데 사용된다.
MFCC는 다음과 같은 단계로 소리를 숫자 데이터로 바꿔 나간다.
1. 소리 신호를 짧은 구간으로 자르기
소리는 시간에 따라 변화하기 때문에 전체를 한꺼번에 분석하는 대신 짧은 구간으로 나누어 분석한다.
보통 오디오 신호를 프레임별(보통 20ms - 40ms)로 나누어 FFT를 적용해 Spectrum을 구한다.
2. 프레임 별로 주파수 분석 (푸리에 변환)
각 구간(프레임)에 대해 푸리에 변환을 적용하여 주파수를 분석한다.
이 과정에서 시간에 따라 변하는 소리를 여러 주파수 성분으로 분해하게 되는데, 이는 소리가 어떤 주파수로 이루어져 있는지 파악하는 데 도움이 된다.
3. Mel 필터 적용하기
사람의 청각은 모든 주파수에 똑같이 민감하지 않고, 낮은 주파수에 더 민감하게 반응한다.
Mel 필터는 주파수를 사람이 듣는 방식과 비슷하게 변환해 주는데, 이를 통해 낮은 주파수는 자세하게, 높은 주파수는 덜 자세하게 표현하게 된다.
이로써 사람이 느끼는 주파수에 더 가까운 데이터를 만들 수 있다.
4. 로그 변환과 역푸리에 변환
다음으로, 주파수의 크기에 로그를 씌워 소리의 강약을 더 쉽게 표현하게 한다.
이후 푸리에 변환의 반대 과정인 역푸리에 변환을 적용해 소리를 압축된 형태로 요약한다.
이 단계에서 소리의 특성이 강조되면서도 데이터의 크기는 줄어든다.
5. MFCC 계수 추출
마지막으로 나오는 MFCC 계수들은 각 소리 구간의 특징을 요약한 값들로, 숫자의 집합이다.
이 계수들은 소리의 음색이나 고유한 특징을 나타내기 때문에, 이 값들만으로도 어떤 소리인지 구분할 수 있다.
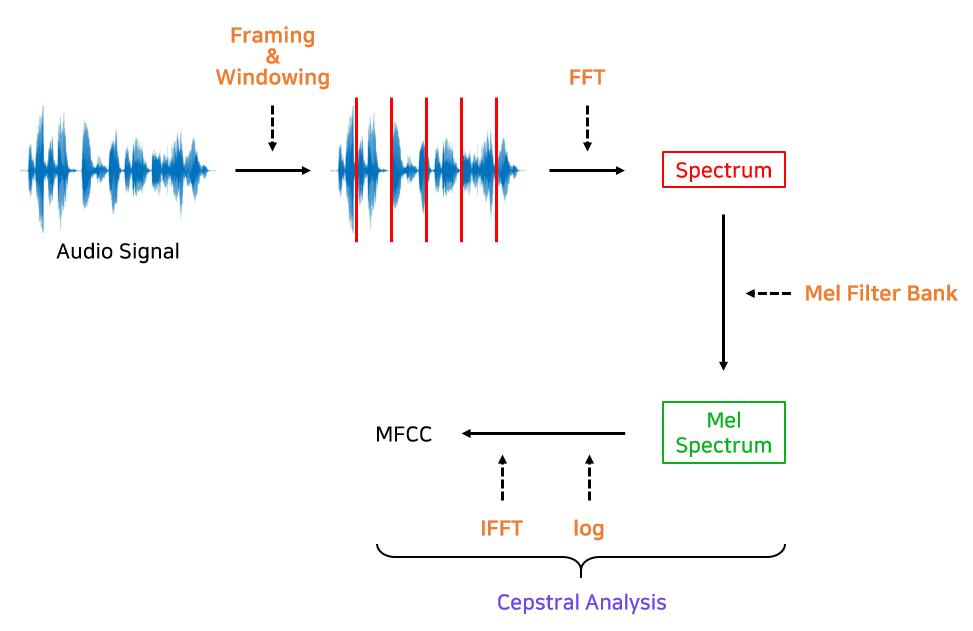
결과적으로 MFCC는 소리의 형태를 파악하는 데 아주 효과적이다.
목소리 분석, 음악 인식, 음성 인식 등에서 많이 활용되는 이유가 바로 소리의 특징을 잘 추출할 수 있기 때문이다.
목소리의 특징을 파악할 수 있는 MFCC 데이터를 찾아낸 후, 이 데이터를 어떻게 활용할지 고민했다.
처음에는 LLM 만을 이용해 MFCC 데이터를 분석하려 했지만, LLM 만 사용하면 차별화가 부족하다고 느껴 직접 모델을 학습시키는 방향으로 목표를 설정했다.
하지만 모델 학습에 필요한 데이터셋 수집이 쉽지 않았다.
잡음 없는 남녀 목소리, 최대한 다양한 목소리 데이터가 필요했는데, 구글링을 계속해도 저녁까지 적합한 데이터셋을 찾지 못했다.
잠시 휴식을 위해 저녁 식사를 하고, 이후 작업을 나누어 진행하는 것이 낫다고 판단했다.
그래서 나는 디자인 시안이 나오는 대로 퍼블리싱을 하고, 백엔드 개발자는 데이터셋을 찾고, 다른 프론트엔드 개발자는 애니메이션 레퍼런스를 준비하며 PoC를 이어갔다.
결국, 남녀 각 250명의 깔끔한 데이터셋을 확보할 수 있었고, 오후 9시쯤 숙소로 복귀했다.
하지만 숙소에서 개발할 장소가 마땅치 않아 택시를 타고 24시간 카페로 이동해 밤을 새며 개발을 이어가기로 했다.
아무래도 해커톤 특성상 데모의 완성도와 외관도 중요해서 애니메이션 요소를 많이 추가하다 보니 예상보다 시간이 지연되어 새벽 3~4시쯤 퍼블리싱 작업을 마쳤다.
API 연동
그리고 메인 기능인 음성을 MFCC 데이터로 변환하고 분석하는 것이 핵심이었기 때문에, 기능이 제대로 작동하는지 꼼꼼히 확인 후 API 연동을 진행했다.
API 요청에는 성별(gender), 나이대(age), 음성 파일(file)을 보내고, 응답으로는 기본 주파수의 평균(f0_mean), RMS 에너지의 평균(mean_rms), MFCC 값의 평균 배열(mfcc_mean), MFCC 분석 기반의 목소리 특징(mfcc_based_voice), 종합적인 목소리 설명(description), 그리고 목소리 유형을 나타내는 보이스팔레트(voice_type)를 받는다.
예시 데이터
{
"f0_mean": 233.1335688446574,
"mean_rms": 0.0700666606426239,
"mfcc_mean": [
-275.4292297363281,
94.72174072265625,
-11.739330291748047,
23.05756950378418,
-19.395843505859375,
-22.270776748657227,
-12.5258150100708,
-13.526935577392578,
-15.34906005859375,
-12.88875961303711,
-21.458581924438477,
-2.113084554672241,
-23.9235782623291
],
"voice_type": "젠틀 브리즈 (Gentle Breeze)",
"mfcc_based_voice": "부드러운 목소리",
"description": "당신의 목소리는 차분하고 부드럽습니다. 듣는 이를 편안하게 해주고, 따뜻한 감정을 전달하는 목소리입니다."
}새벽 5시쯤 API 연동을 진행하던 중 예상치 못한 문제가 발생했다..
음성 녹음을 위해 react-audio-voice-recorder 라이브러리를 사용하여 녹음 시작, 중단, 파일 생성을 관리하려 했는데, API 요청 시 녹음 파일이 undefined로 전달되었다.
디버깅을 하면서 문제를 파악해 보니, 녹음을 중지할 때 호출하는 stopRecording 메소드에서 recordingBlob에 음성 파일이 자동으로 저장되지 않는 것이 문제였다.
그래서 문제 해결을 위해 공식 문서를 다시 찾아보았다.

공식 문서에선 recordingBlob이 stopRecording 호출 후 생성된다고 나와 있지만 작동하지 않았다.
이전 프로젝트에서도 동일한 방식으로 react-audio-voice-recorder 라이브러리를 사용해 음성 파일을 관리했기 때문에, 코드도 비교해 보았지만 문제점을 찾을 수 없었다.
이때부턴 피로가 누적되면서 집중력도 많이 떨어졌다.
결국 1시간 정도 후, useEffect를 사용해 recordingBlob의 상태 변화를 의존성으로 설정해 API 요청이 트리거되도록 변경했다.
겨우 문제를 해결하고 드디어 API 요청을 보냈지만, 서버에서 또 다른 오류가 발생했다...
음성 파일의 타입이 사용 불가하다는 오류였는데, 특별한 파일도 아닌 일반적인 wav 파일이었다.
Swagger에서는 정상적으로 작동했지만 계속 오류가 발생했고, 결국 잠을 자겠다는 생각은 접고 문제 해결에 집중하기로 했다.
코드를 계속 수정하고 테스트해 보았지만 여전히 오류가 발생했다.
그때 예전에 비슷한 오류를 겪었던 기억이 떠올랐다.
MIME 타입과 관련된 오류였는데, 이 부분을 제대로 설정하면 요청이 정상적으로 처리될 것 같은 느낌이 들었다.
const mimeType = recorderControls.recordingBlob.type;
const extension = mimeType.split("/")[1]; // 'webm' 또는 'ogg'
const fileName = `recording.${extension}`;
const file = new File([recorderControls.recordingBlob], fileName, {
type: mimeType,
});이 코드는 녹음된 음성 파일을 recordingBlob에서 가져와, MIME 타입과 파일 이름을 설정하여 새로운 File 객체로 생성하는 로직이다.
이렇게 설정하니 드디어 정상적으로 API 연동이 되었다.
MIME이란?
MIME(Multipurpose Internet Mail Extensions)은 파일의 형식과 내용을 나타내기 위한 표준 형식이다.
주로 이메일과 웹에서 파일을 전송할 때, 콘텐츠가 어떤 종류의 데이터인지 클라이언트와 서버가 이해할 수 있도록 MIME 타입을 사용한다.
MIME 타입의 구조는 다음과 같이 주 타입/하위 타입 형식으로 이루어진다.
-
주 타입은 콘텐츠의 일반적인 범주를 나타낸다.
예를 들어,text,image,audio,application등이 있다. -
하위 타입은 주 타입에 대한 구체적인 형식을 정의한다.
예를 들어,html,plain은text의 하위 타입,jpeg,png는image의 하위 타입이다.
❗️주요 MIME 타입 예시❗️
text/html: HTML 문서
text/plain: 일반 텍스트
image/jpeg: JPEG 이미지
image/png: PNG 이미지
audio/mpeg: MP3 오디오
audio/ogg: Ogg 오디오
application/json: JSON 데이터
application/pdf: PDF 문서
2일차
API 연동이 완료되어 프론트엔드 작업만 남았기에 숙소로 돌아가 조식을 먹고, 디자이너와 백엔드 개발자는 조금이라도 쉬게 했다.
이후 다시 작업을 시작하며 API 연동을 확인해보았는데, 이번에는 gender 데이터를 인식하지 못하는 문제가 발생했다....
이때 멘붕이 왔지만, 백엔드 개발자가 이미 자고 있어서 예시 형식을 참고해 최대한 실제 데이터가 응답이 되었을 때 문제가 없도록 처리를 해놓았다.
2시간 후, 다시 대전 컨벤션 센터로 돌아가기 전에 백엔드 개발자를 깨워 상황을 설명했는데, 문제는 내가 gender 데이터를 "남자" 혹은 "여자"로 요청을 했어야 했는데 "남성" 혹은 "여성"으로 보내야 하는 줄 알고 보낸 것이었다.
잠을 한숨도 못 자서 이런 간단한 오류조차 생각하지 못했고, 해커톤 특성상 바로 옆에서 개발을 하다 보니 API 개수가 많지 않다고 명세가 없던 것도 문제가 되었다.
정말 다행히 시간 내에 모든 개발을 마쳤고, 오후 1시 30분부터 대전 컨벤션센터 제2 전시장에서 부스 심사가 시작되었다.
부스는 대전 사이언스 페스티벌이 열리는 전시장 내에 마련되었고, 일반인들도 자유롭게 체험할 수 있는 공간이었으며, 심사위원들이 각 부스를 돌며 심사하는 방식으로 진행되었다.

처음엔 일반인 분들이 부스를 방문해 체험하면서 다양한 피드백을 주었다.
그중 아쉬웠던 점은 페이지 이동 시 녹음이 자동으로 시작되는 부분이었다.
녹음이 시작된 것을 몰라 당황하거나, 중지 버튼을 찾지 못하는 경우도 있었다.
녹음 시작 버튼을 추가하고, 녹음 중지 버튼도 더 눈에 잘 띄도록 했으면 사용자 경험 측면에서 훨씬 좋았을 것 같아 UX의 중요성을 다시 한번 깨달았다.
이후 심사위원 분들이 한 분씩 방문해서 간단한 발표와 시연을 진행했다.
평소에는 잘 긴장하지 않는 편인데, 우리 팀의 아이디어와 노력을 인정받고 싶은 마음도 있었고 심사위원 명찰에 회사명이나 학교명이 적혀있어 갑자기 긴장이 되었다.
첫 번째로 방문한 심사위원은 두나무앤파트너스에서 오신 분이었다.
두나무앤파트너스는 두나무의 투자 전문 자회사라고 한다.
그래서 그런지 기술적인 부분보다는 사업성에 관련된 질문이 많았다.
기억에 남는 질문은 다음과 같다.
🙋♂️ Q. 이 서비스가 MBTI와 차별되는 점이 뭔가요?
🛎️ A. MBTI는 성격과 관련된 특징을 다루는 반면, 저희 서비스는 목소리를 통해 유형을 분류하는 서비스입니다.
사람들이 자신의 목소리를 녹음해서 들으면 이질감을 느끼는 경우가 많은데요.
저희는 이러한 목소리를 객관적인 데이터로 분석해 유형을 분류해줍니다.
앞으로 새로운 사람들과의 대화에서 “MBTI가 뭐야?”라는 질문과 함께 “보이스 팔레트는 뭐야?”라고 묻는 새로운 패러다임을 열고자 합니다.
솔직히 그 당시엔 답변을 하면서도 머릿속이 정리가 되지 않아, 내가 잘 답했는지 확신이 서지 않았다.
하지만 심사위원의 반응이 나쁘지 않았던 것 같았다.
잠시 후 연세대학교 교수님이 심사위원으로 오셨다.
그리고 확실히 교수님이라 그런지, 기술적인 질문이 많았다.
🙋♂️ Q. 목소리의 특징을 어떻게 알 수 있어요?
🛎️ A. 우선 음성을 녹음한 후, 오디오 신호를 잘게 나누어 MFCC라는 데이터를 추출합니다.
MFCC 데이터는 목소리의 음색, 피치, 발음 습관 등 말하는 스타일을 분석할 수 있게 해주는데요.
첫 번째 MFCC 데이터는 음성의 전반적인 크기를 나타내고, 두 번째부터는 저주파에서 고주파 대역까지의 특징을 보여줍니다.
이 데이터를 저희가 학습시킨 모델에 넣어 분석해서 결과를 차트와 텍스트로 표현합니다.
그리고 교수님이 가신 후에 우리는 나쁘지 않은 것 같은데? 하면서 진짜 상받을 수도? 이러면서 김칫국을 마셨다 ㅋㅋ..
잠시 후 심사위원은 아니었지만 기술지원 멘토님이 오셔서 피드백을 주셨다.
우리 팀은 MFCC 데이터를 라인 차트로 표현하고 있었는데, 멘토님은 MFCC 데이터를 라인 차트로 나타내는 것이 다소 어색할 수 있다고 조언해 주셨다.
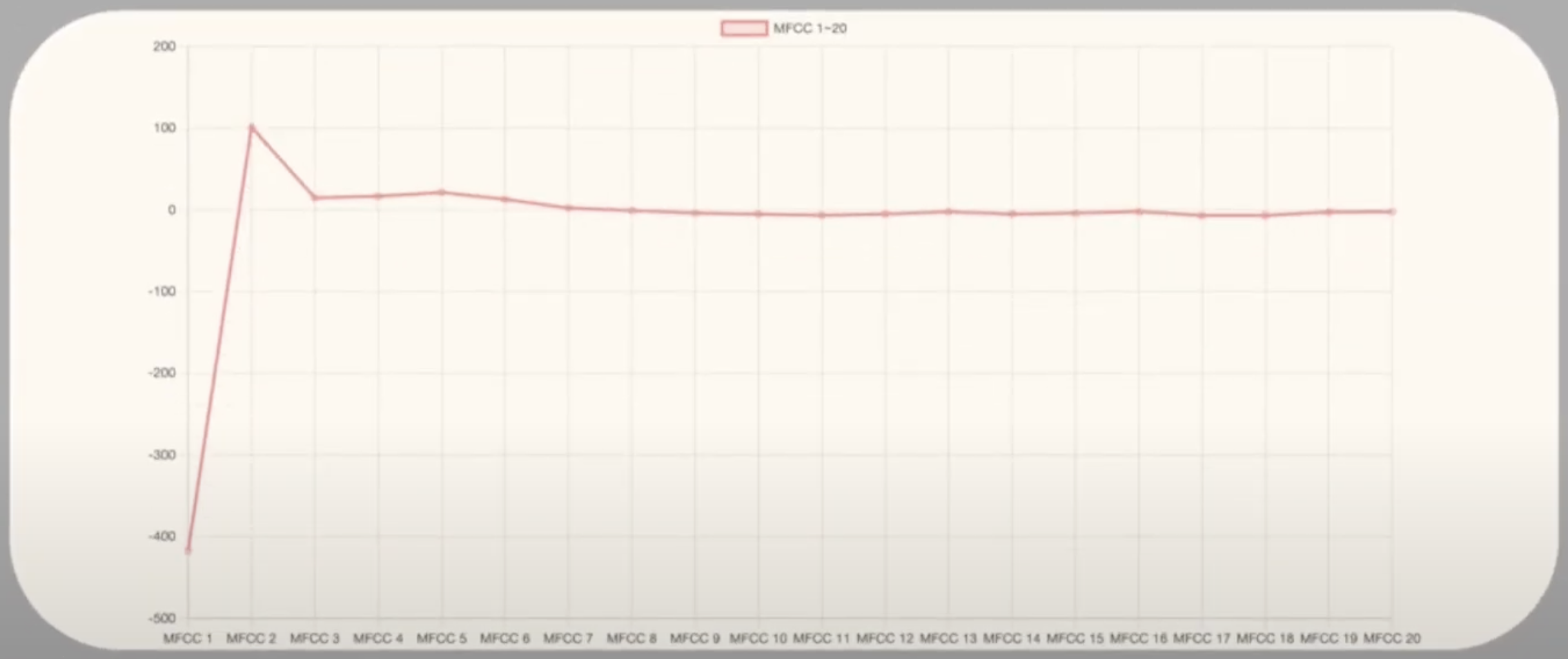
나중에 알아보니, MFCC 데이터는 주파수 대역의 에너지 성분을 표현한 것이기 때문에 파형 그래프나 스펙트로그램으로 시각화하는 것이 더 직관적일 수 있다는 것을 알게 되었다.
결과
그렇게 부스 심사가 어찌저찌 마무리되었다.
이제 18팀 중 4팀만 수상하며, 수상팀만이 PPT 발표를 통해 순위를 결정하는 방식이었다.
발표 심사에 진출할 4팀의 이름이 발표되었는데, 아쉽게도 우리 팀은 포함되지 않았다...
처음 도전이라 당연하다는 마음과 정말 열심히 준비했기에 가능성도 있었다는 아쉬움이 공존했다.
하지만 수상팀의 발표 심사를 지켜보며, 우리 팀이 4팀 안에 들지 못한 이유를 바로 깨달을 수 있었다.
수상팀들은 아이디어도 훌륭했고, 이를 뒷받침하는 기술력 또한 뛰어났다.
특히 아쉬웠던 것은 우리 팀에 기획자가 없었다는 점이었다.
발표를 통해 기획자와 PM의 역할이 얼마나 중요한지 깨달을 수 있었다.
사실 나는 기획자가 단순히 아이디어를 내고 프로젝트를 이끄는 역할이라고 생각했었다.
하지만 수상팀들의 발표를 보면서, 기획자는 그 이상의 역할을 하고 있음을 알게 되었다.
그래서 해커톤이 끝난 후 기획자가 하는 일을 자세히 찾아 보았다.
기획자의 역할
1. 아이디어 발굴 및 검증
- 프로젝트 초기 단계에서 아이디어를 제안하고, 이 아이디어가 사용자와 시장에 얼마나 유용한지 검토한다.
아이디어를 현실화하기 위해 타겟 사용자, 문제 정의, 경쟁사 분석 등을 진행하며 아이디어의 필요성을 입증한다.
2. 시장 조사 및 사용자 분석
- 시장의 흐름, 경쟁사, 사용자 요구를 분석해 프로젝트의 방향성을 잡는다.
사용자 페르소나(persona)를 만들어 타겟 사용자가 누구인지 정의하고, 그들의 니즈와 문제를 해결하는 방향으로 프로젝트를 설계한다.
3. 기능 정의 및 요구사항 문서화
- 프로젝트가 제공해야 하는 핵심 기능과 이를 구현하기 위한 세부 요구사항을 문서로 작성한다.
4. 프로젝트 일정 및 자원 관리
- 프로젝트 진행 일정을 세우고, 이를 위해 필요한 자원(인력, 예산 등)을 관리한다.
일정에 맞춰 진행 사항을 체크하고, 예상치 못한 문제에 대비해 조정을 한다.
5. 팀 간 커뮤니케이션 및 조율
- 프로젝트의 진행을 위해 개발, 디자인 등 여러 팀과의 소통을 담당한다.
6. 제품 비전 및 로드맵 관리
- 프로젝트의 장기적인 목표와 로드맵을 설정한다.
제품 비전은 프로젝트가 이루고자 하는 큰 목표를 의미하고, 로드맵은 이를 달성하기 위한 구체적인 단계와 일정을 나타낸다.
7. 피드백 수집 및 개선 사항 반영
- 사용자, 팀원, 이해관계자로부터 피드백을 수집하고 이를 바탕으로 프로젝트를 개선한다.
8. 성과 분석 및 후속 전략 수립
- 프로젝트가 완료되거나 주요 단계에 도달했을 때 성과를 평가하고, 데이터를 분석해 개선점을 파악한다.
이를 통해 향후 프로젝트 방향성을 조정하거나 다음 단계의 전략을 세운다.
해커톤이 1박 2일이라 이 모든 과정을 다 진행하지는 않았겠지만, 수상팀은 각 단계에서 철저한 검증 과정을 거쳤고, 철저한 시장 조사와 페르소나 설정을 통해 명확한 타겟을 잡았다는 점이 정말 대단하다고 느꼈다.
내가 디자인을 배워도 디자인 전공자를 따라가기 어려운 것처럼, 기획을 전문으로 하는 사람들의 차이가 확연히 느껴졌다.
결론 및 느낀점
솔직히 이제 개발에는 어느 정도 자신감이 생겼지만, 우물 안 개구리가 되지 않기 위해 대외활동과 해커톤에 참여해 실력을 검증받고, 다양한 사람들과의 경험을 통해 자극을 받고 싶었다.
이번 SPARCS 과학 해커톤 2024가 적절한 시기에 정말 좋은 경험과 자극이 되었고, 개발적인 부분뿐 아니라 그 외적인 부분에서도 많은 것을 배웠다.
앞으로는 더 깊이 있는 공부와 실력을 갈고 닦는 과정이 필요하다는 생각이 들었다.
그리고 데이터셋을 미리 준비했다면 개발 시간이 충분했을 것 같은데 아쉬웠다.
첫 해커톤이라 잠도 못 자서 힘들었고, 예상치 못한 오류로 정신적으로도 힘들었지만, 다음에 또 해커톤에 나가게 된다면 이번 경험을 토대로 부족한 부분을 보완해 수상까지 목표로 해보고 싶다.
우리팀 고생했다!!!

References

이번 해커톤에서 많은 것을 경험하고 배운 듯해 보이네요! 목소리 데이터를 분석해 사용자에게 맞춤형 피드백을 제공하는 아이디어도 참신하고 흥미롭네요..
이번 해커톤이 앞으로의 개발에 대한 자극을 되었다면 좋겠습니다
해커톤의 경험을 토대로 계속 발전해 나가는 모습을 응원합니다! 💪