1.1 극댓값(Peak) 찾기
1차원에서의 극댓값
- 문제: [a,b,c] 라는 배열에서 b가 b≥a, b≥c 를 만족한다면 b는 그 배열의 절댓값이다. 이 때 길이가 n인 배열에서 극댓값을 찾아보자.
📌 a=b=c이더라도 b는 극댓값이며, 따라서 a,c도 극댓값이 될 수 있다. 또한 배열의 최댓값(global maximum)보다 작지만 자신의 양 옆 원소보다는 큰 local maximum 또한 극댓값이다. **문제의 정의에 따르면** 극댓값은 언제나 존재하며, 여러개일 수 있다.
A. 배열 순회
배열의 처음부터 끝 원소를 전부 순회하며 극댓값을 찾아낼 수 있다.
배열이 [6,7,4,3,2,1,4,5] 인 경우를 생각해 보자.
처음 원소인 6에서 시작하여 7,4,3, … 순으로 순회하면 극댓값의 기준을 만족하는 원소는 7과 5임을 알 수 있다.
def func():
arr=[6,7,4,3,2,1,4,5]
peak=[]
for i in range(len(arr)):
if i==0:
if arr[i]>=arr[i+1]:
peak.append(arr[i])
elif i==len(arr)-1:
if arr[i]>=arr[i-1]:
peak.append(arr[i])
else:
if arr[i]>=arr[i-1] and arr[i]>=arr[i+1]:
peak.append(arr[i])
return peak모든 원소를 전부 순회하므로 이때의 시간복잡도는 O(n)이다.
B. 분할 정복
배열의 중간 위치에 존재하는 원소를 기준으로 잡고 양 옆의 원소를 비교한다. 자신보다 더 큰 수를 가지는 부분에 대해 똑같은 과정을 반복한다.
배열이 [6,7,4,3,2,1,4,5] 인 경우를 생각해 보자.

중간 원소인 3을 기준으로 양 옆을 비교한다. 왼쪽은 4로 자신보다 크고, 오른쪽은 2로 자신보다 작다. 그러면 원소의 오른쪽 부분인 [2,1,4,5]는 더 이상 고려하지 않는다.
이제 배열이 [6,7,4] 가 되었다. 중간 원소인 7을 기준으로 양 옆을 비교한다. 왼쪽은 6으로 자신보다 작고, 오른쪽은 4로 자신보다 작다. 극댓값을 찾아내었다!
def func():
arr=[6,7,4,3,2,1,4,5] # 7
arr=[6,7,4,5,6,5,1,2] # 6
arr=[1,1,1,1,1,1,1] # 1
arr=[1,2,3,4,3,2,1] # 4
arr=[4,3,2,1,2,3,4] # 4
peek=arr[0]
start=0
end=len(arr)-1
while start<=end:
mid=(start+end)//2
if arr[mid]<=arr[mid-1]:
end=mid-1
elif arr[mid]<=arr[mid+1]:
start=mid+1
else: # arr[mid]>arr[mid-1] and arr[mid]>arr[mid+1]
peek=arr[mid]
break
return peek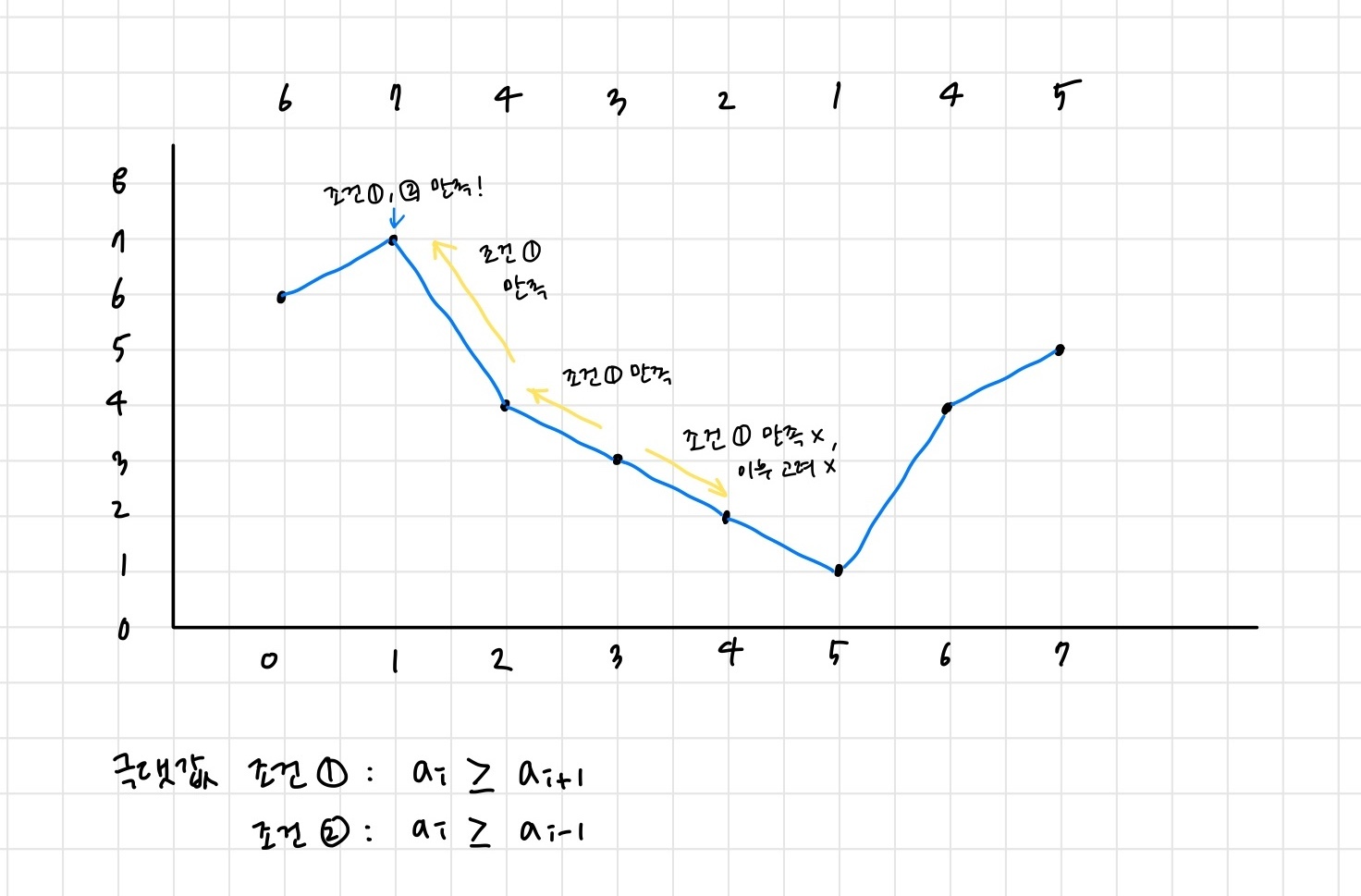
문제가 정의하는 극댓값의 조건은 ‘자신의 양 옆 원소보다 크거나 같은 원소’이다. 즉 극댓값은 언제나 존재한다는 것을 알 수 있다. 이 경우 본인()의 양 옆 원소를 비교했을 때, 자신보다 작은 원소 의 방향으로 나아갈 이유가 있을까? 나보다 작다는 것은 그 원소 는 이미 극댓값의 조건 중 하나에서 탈락한 것이다. 따라서 그 방향으로 더 탐색할 필요가 없다.
반대로 나보다 큰 원소 가 있는 방향을 생각해 보자. 우선 나보다 크다는 것만으로 극댓값의 조건 중 하나를 달성했다.
만약 원소 의 내가 아닌 다른 이웃 이 그 원소보다 작다면, 이미 그것으로 은 극댓값 조건을 만족한다. 그래프가 올라갔다가 꺾인 이미지를 상상해 보자.
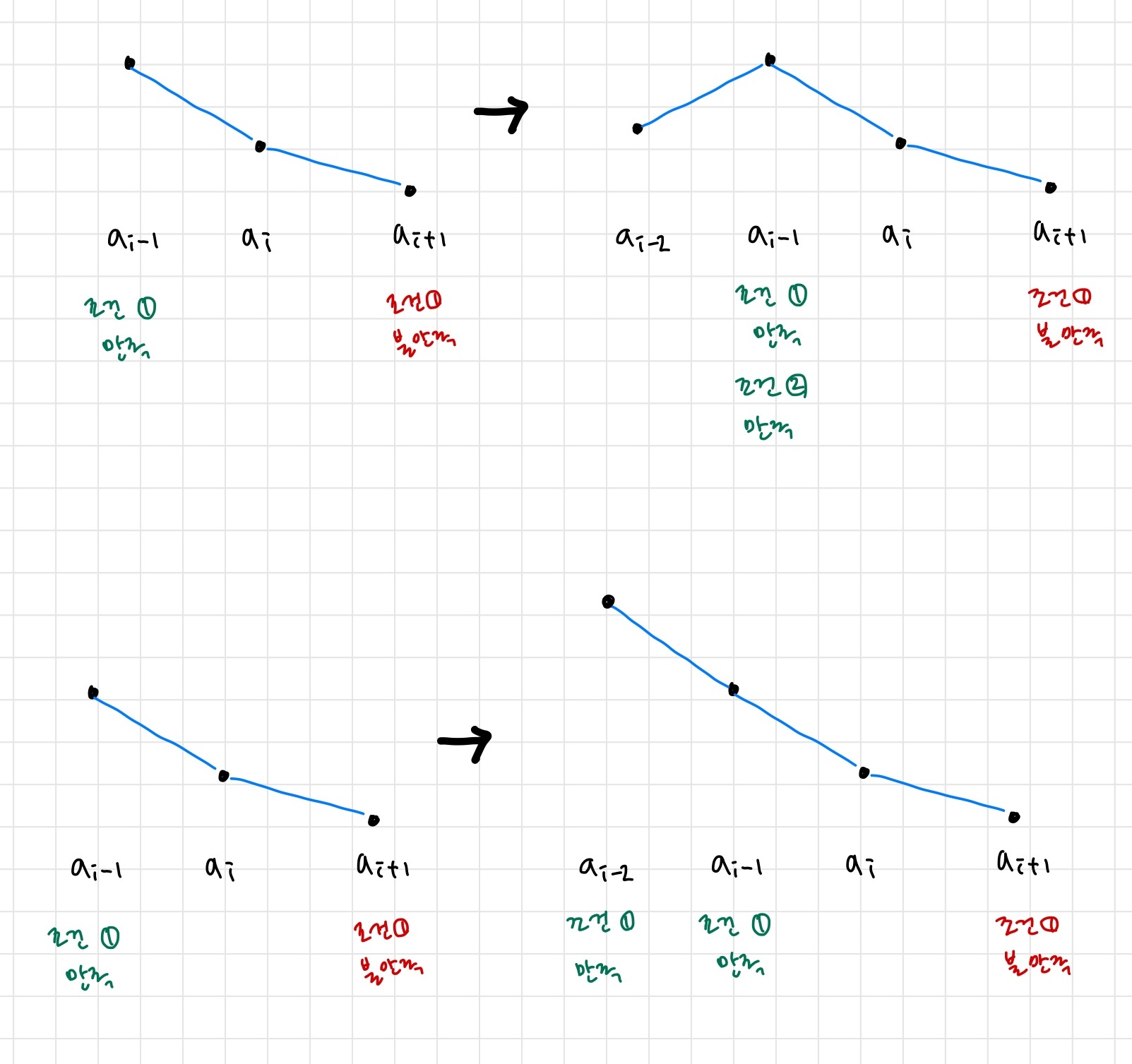
만약 원소의 내가 아닌 다른 이웃 이 그 원소보다 크다면, 계속 그 방향으로(높은 방향으로) 나아가면 된다. 그래프가 계속 상승한다면 그래프의 끝 부분이 극댓값이 될 것이다.
결국 조건을 만족하는 방향으로 나아가며 나보다 큰 쪽의 원소를 확인한다면 무조건 극댓값을 찾을 수 있다.
설명을 위해 그래프의 한쪽 방향으로 나아간다고 표현했지만, 사실 한 점의 양 옆을 비교한 뒤에는 방향만 확정하고 다시 그 방향의 절반씩 잘라나간다.
처음에는 개의 원소가 존재하고, 자신의 앞, 뒤 원소와의 비교(O(1)) 후 절반을 잘라낸다. 다음에는 개의 원소, 그 다음에는 , … 결국 남은 원소의 개수가 1개만 남을 때까지, 즉 까지 반복한다. 이 때 잘라내는 단계는 번이다.
이므로 이다. 원소끼리의 비교는 O(1), 각 단계에서 O(logN)이 걸리므로 전체 시간복잡도는 O(logN)이다. 배열 순회 방법보다 시간복잡도가 훨씬 줄어들었다!
2차원에서의 극댓값
문제: n개의 행과 m개의 열로 이루어진 2차원 배열에서 극댓값을 찾아보자. 극댓값의 정의는 동일하지만 비교 대상이 좌우에서 상하좌우로 확장되었다.
A. 탐욕 상승 알고리즘
모든 공간을 순회하며 2차원 극댓값을 찾는다.
def func():
n=m=4
arr=[[6,7,4,3],
[14,13,12,10],
[15,9,11,17],
[16,17,19,20]]
peak=[]
direction=[(0,1),(0,-1),(1,0),(-1,0)]
for i in range(n):
for j in range(m):
cnt=0
for x,y in direction:
nx,ny=i+x,j+y
if 0<=nx<n and 0<=ny<m:
if arr[i][j]>=arr[nx][ny]:
cnt+=1
else:
cnt+=1
if cnt==4:
peak.append(arr[i][j])
return peak모든 공간을 순회하기 때문에 시간복잡도는 O(n*m)이다.
B. 1차원 분할 정복 확장
중앙 열에서 1차원 극댓값을 찾고, 그 극댓값이 발견된 행에서 1차원 극댓값을 찾는 방식이다. 하지만 2차원 극댓값이 해당 행에 존재하지 않을 수도 있기 때문에, 1차원 분할 정복을 단순히 2차원으로 확장해서는 문제를 해결할 수 없다.
C. 최댓값을 사용한 2차원 분할 정복
중앙 열 에서 최댓값을 찾는다. 그 최댓값이 발견된 행 를 기준으로 좌우 비교를 수행한다. 1차원 분할 정복과 같이 높은 값을 가지는 방향으로 이동해 m을 절반씩 줄여나간다.
시간복잡도는 각 열에서 최댓값을 찾는 데 O(n)이 걸리고, 행의 좌우 비교에서 O(1), 열을 절반씩 줄여가는 과정에서 O(logm)이 걸린다. 즉 전체 시간복잡도는 O(nlogm)이다.
위의 방법이 가능한 이유는 우선 열의 최댓값이 자신의 상, 하보다 크다는 조건을 이미 만족하기 때문이다. 또한 열의 최댓값보다 큰 값을 가지는 방향으로 이동하면, 이후 열이나 열과 열의 행을 비교했을 때 열의 행보다 작은 값을 가질 수 없다.
이후 열을 절반씩 줄여 나갈 때 1차원 분할 정복과 같은 논리로 조건(자신의 좌, 우보다 큰 조건)을 만족하는 위치로 이동하면 무조건 극댓값을 찾을 수 있다.

위의 예시로 생각해 보자.
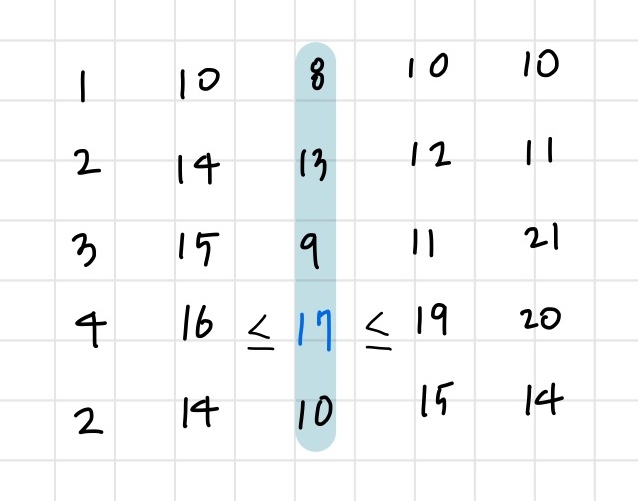
우선 중앙인 2번 열에서 최댓값을 찾는다. 최댓값 17이 존재하는 위치 (3,2)을 기준으로 (3,1), (3,3)과 비교한다. (3,3)인 19가 17보다 크기 때문에, 왼쪽 절반은 버리고 오른쪽으로 이동한다.
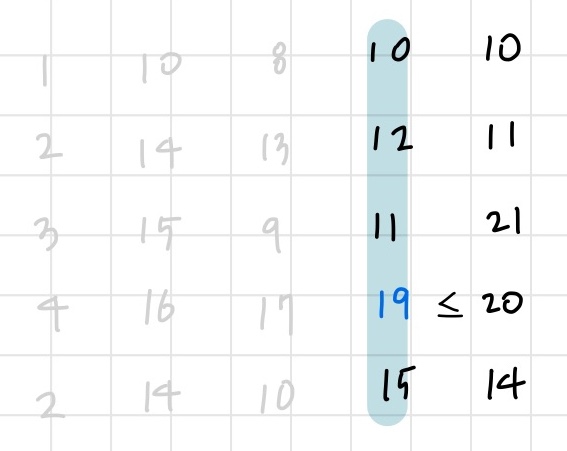
오른쪽 절반의 중앙인 3번 열에서 최댓값을 찾는다. (3,3)을 기준으로 (3,4)와 비교한다. (3,2)는 이미 비교대상에서 제외되었으므로 고려하지 않는다. (3,4)인 20이 19보다 크기 때문에, 왼쪽 절반을 버리고 오른쪽으로 이동한다.

이제 남은 하나의 열 4번 열에서 최댓값을 찾는다. (2,4)에서 21을 찾아내었지만 왼쪽은 이미 비교대상에서 제외되었고 오른쪽은 배열의 끝이기 때문에 고려할 필요가 없다. 2차원 극댓값을 찾아내었다!
D. 극댓값을 사용한 2차원 분할 정복
만약 중앙 열에서 최댓값 대신 극댓값을 찾는다면 어떻게 될까?

아까와 같은 예시로 생각해 보자.
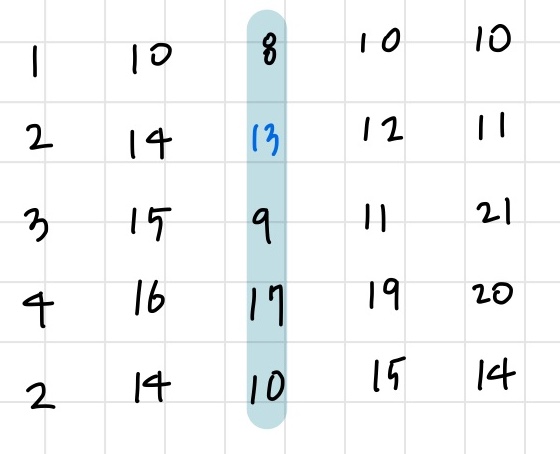
우선 동일하게 중앙 열인 2번 열에서 시작한다. 편의상 위에서 아래로 극댓값을 찾아낸다고 가정하자. (1,2)에서 1차원 극댓값 13을 찾아내었고, 이를 (1,1), (1,3)과 비교한다. 14가 13보다 크므로 오른쪽 절반을 버리고 왼쪽으로 이동한다.
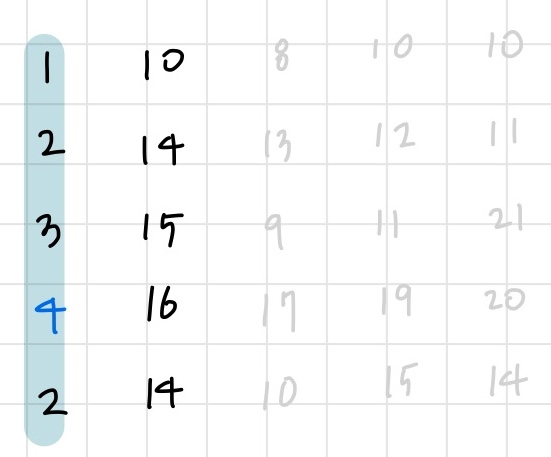
왼쪽 부분의 중간 열인 0번 열에서 1차원 극댓값 4를 찾아낸다. (3,0)에서 극댓값 4를 찾아내고 이를 (3,1)과 비교한다. 16이 4보다 크므로 왼쪽을 버리고 오른쪽으로 이동한다.
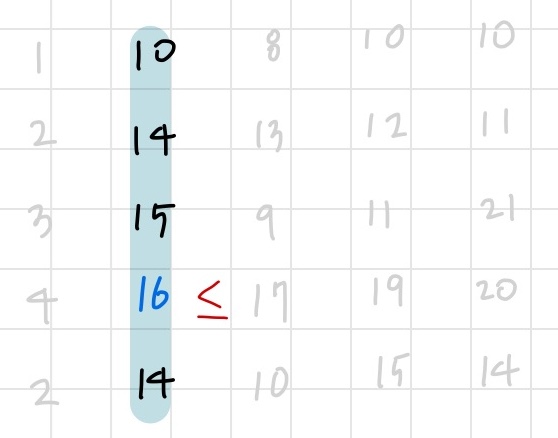
열이 하나만 남았으니 여기서 1차원 극댓값을 찾으면 된다. 16을 찾아냈지만, 2차원 극댓값의 조건인 ‘자신의 상하좌우보다 크거나 같다’를 만족하지 못한다.
예시를 통해 극댓값을 기준으로 잘라낼 열을 결정한다면 이미 잘라낸 부분에서 자신의 값보다 큰 값이 있을 수 있다는 사실을 알아보았다.
최댓값을 사용하는 경우, 열에서 가장 큰 값을 찾아내었기 때문에 보다 큰 값 이 있는 방향인 열로 이동한다면 열에는 열의 최댓값보다 큰 값이 무조건 존재한다. 하지만 극댓값을 사용하는 경우에는 열의 극댓값이 열의 모든 행보다 크다는 보장이 없기 때문에** 2차원 극댓값을 찾지 못할 수 있다. 1차원 극댓값을 찾을 때와 같은 논리로 생각하면 된다!
