Mahdi Yusuf 님이 작성한 Redis Explained
를 번역하는 문서입니다. 원작자분의 허락을 받았습니다.
레디스란?
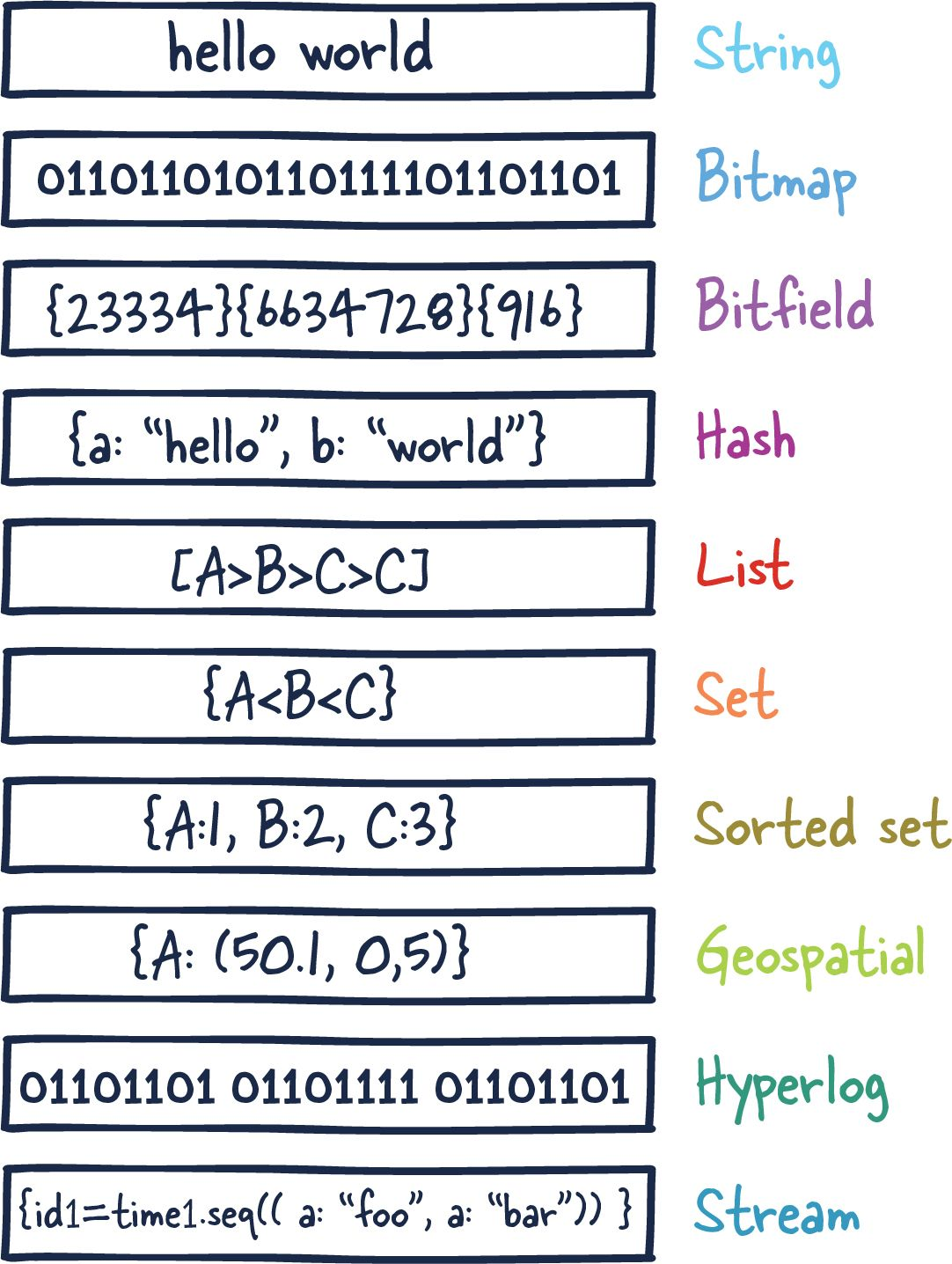
레디스(원격 딕셔너리 서비스) 는 키-밸류 형식의 오픈소스 데이터베이스 서버입니다.
레디스에 대한 가장 정확한 설명은 자료 구조 서버라는 것인데요. 레디스의 이러한 특별한 성격은 많은 개발자들 사이에서 레디스가 채택되고 인기를 얻을 수 있게 해주었습니다.
순회하고, 분류하고, 열들을 순서대로 정렬하는 것보다는, 데이터가 처음부터 원하는 자료 구조로 되어있다면 어떨까요? 초기에 레디스는 Memcached와 매우 유사하게 사용되었지만, 점차 개선됨에 따라, 게시-구독 메커니즘과 스트리밍 및 큐를 비롯한 다른 많은 경우에서도 실행할 수 있게 되었습니다.
주로, 레디스는 어플리케이션 성능을 개선하는데 도움을 주기위해 MySQL이나 PostgreSQL같은 다른 "진짜" 데이터베이스의 앞단에서 캐시로서 사용되는 인-메모리 데이터베이스입니다.레디스는 주로 아래와 같은 데이터들을 위해서 메모리 속도를 활용하고 중앙 애플리케이션 데이터베이스의 부하를 완화합니다.
- 자주 변경되지는 않지만 자주 요청되는 데이터
- 덜 중요하면서 자주 관여하는 데이터
위의 데이터들의 예시로는 세션 또는 데이터 캐시, 대시보드용 리더보드 또는 롤업 분석이 포함될 수 있습니다.
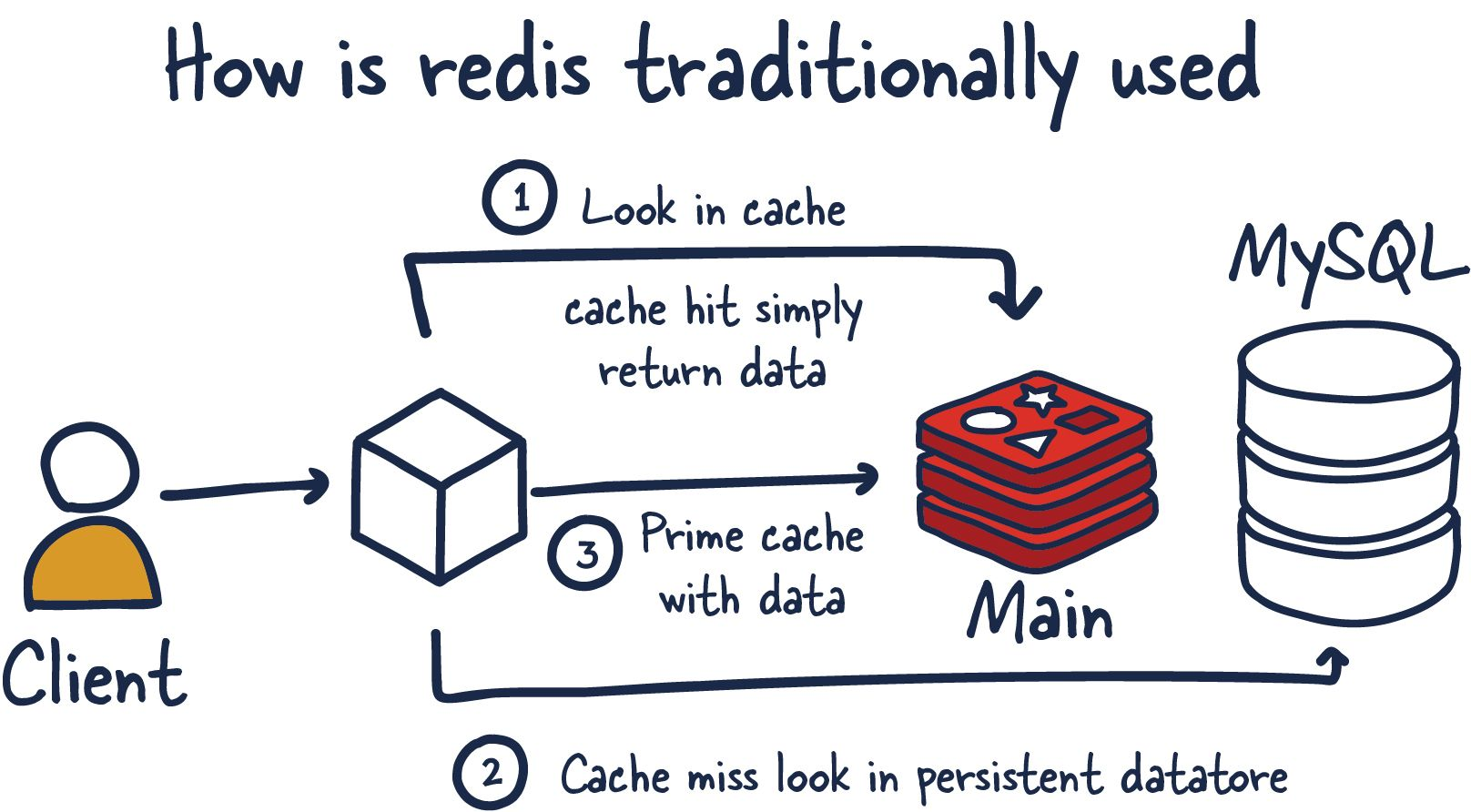
① 캐시를 조사하고, 캐시 히트는 단순하게 단순히 데이터를 반환만 합니다.
② 데이터와 함께 캐싱을 (사용할 수 있게) 준비합니다.
③ 캐시 미스(캐시에 필요한 데이터가 없는 상황)의 경우 영속적인 데이터 저장소를 조사합니다.
그러나, 많은 사용 경우에, 레디스는 본격적인 주요 데이터베이스로 사용될 수 있음을 충분히 보장하고 있습니다.
레디스 플러그인 및 다양한 고가용성(HA) 설정과 함께, 레디스를 데이터베이스로 사용하면 특정 시나리오나 워크로드에 매우 유용합니다.
또 다른 중요한 측면은 레디스가 캐시와 데이터 저장소 사이의 경계를 모호하게 만들었다는 것입니다. 여기서 이해해야 할 중요한 점은, 메모리에서 데이터를 읽고 조작하는 것이 SSD 또는 HDD를 사용하는 기존 데이터 저장소에서 가능한 것보다 훨씬 빠르다는 것입니다.

크레딧: 원본 게시물의 Jeff Dean!
Memcachced란?
Memcached는 레디스보다 6년 앞선 2003년 Brad Fitzpatrick에 의해 만들어졌습니다. 그것은 원래 Perl 프로젝트로 시작했고 나중에 C로 다시 작성되었습니다. 그것은 당시의 사실상의 캐싱 도구였습니다. 그것과 Redis의 주요 차이점은 데이터 유형의 부족과 LRU(가장 최근에 사용됨)의 제한된 축출 정책입니다.
또 다른 차이점은 Redis는 단일 스레드이고 Memcached는 다중 스레드라는 것입니다. Memcached는 엄격한 캐싱 환경에서 성능을 발휘할 수 있지만 분산 클러스터에서 일부 설정이 필요하지만 레디스는 즉시 이를 지원합니다.
다음은 이 두 캐시 간의 기능에 대한 명세입니다.
| Memcached | Redis | |
|---|---|---|
| 밀리초 미만의 지연 시간 | YES | YES |
| 개발자가 사용하기에 용이한가 | YES | YES |
| 데이터 파티션 | YES | YES |
| 다양한 프로그래밍 언어들을 지원하는가 | YES | YES |
| 고급 자료 구조 | - | YES |
| 멀티쓰레드 아키텍처 | YES | - |
| 스냅샷 | - | YES |
| 복제 | - | YES |
| 트랜잭션 | - | YES |
| Pub/Sub 기능 | - | YES |
| 루아 스크립팅 | - | YES |
| 특정 지역 지원 | - | YES |
지금은 데이터를 디스크에 유지하는 방식을 구성할 수 있지만 처음 도입되었을 때 Redis는 메모리에 있는 데이터의 비동기 복사본이 장기 저장을 위해 디스크에 유지되는 스냅샷을 사용했습니다. 안타깝게도 이 메커니즘에는 스냅샷 간에 데이터가 손실될 수 있다는 단점이 있습니다.
레디스는 2009년에 시작된 이후로 성숙해졌습니다. 우리는 레디스를 데이터 스토리지 시스템 무기고에 추가할 수 있도록 대부분의 아키텍처와 체계적인 분류들을 다룰 것입니다.
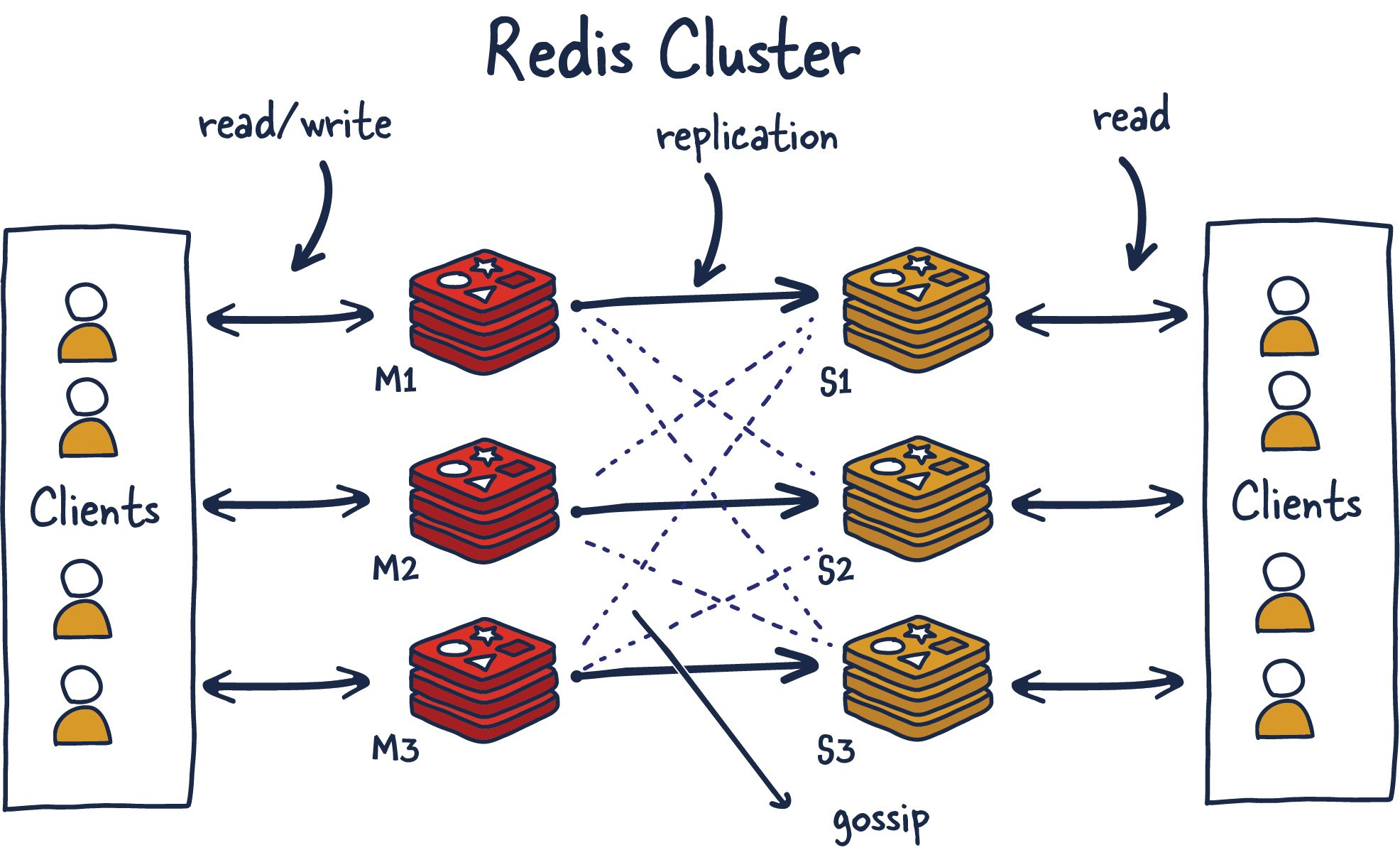
레디스 아키텍쳐
레디스의 내부 구조물에 대해 이야기하기전에, 먼저 다양한 레디스 배포와 그에 따른 장단점에 대해 논의해 보겠습니다.
우리는 주로 다음 구성에 중점을 다룰 것입니다.
- 단일 레디스 인스턴스
- 레디스 고가용성(High Availability)
- 레디스 센티넬
- 레디스 클러스터
여러분의 사용 사례 및 규모에 따라, 하나의 설정 또는 다른 설정을 사용할 수 있습니다.
1. 단일 레디스 인스턴스

단일 Redis 인스턴스는 Redis에서 제공하는 가장 간단한 배포입니다.
이를 통해 사용자는 서비스를 성장시키고 속도를 높이는 데 도움이 되는 작은 인스턴스를 설정하고 실행할 수 있지만, 이 배포에 단점이 없는 것은 아닙니다.
예를 들어 이 인스턴스가 실패하거나 사용할 수 없는 경우 Redis에 대한 모든 클라이언트 호출이 실패하므로 시스템의 전체 성능과 속도가 저하됩니다.
충분한 메모리와 서버 리소스가 주어지면 이 인스턴스는 강력할 수 있습니다. 캐싱에 주로 사용되는 시나리오는 최소한의 설정으로 상당한 성능 향상을 가져올 수 있습니다. 충분한 시스템 리소스가 주어지면 이 Redis 서비스를 애플리케이션이 실행 중인 동일한 상자에 배포할 수 있습니다.
시스템에서 데이터를 관리하는 것에 대한 몇 가지 Redis 개념을 이해하는 것은 필수적입니다.
먼저 Redis로 전송된 명령은 메모리에서 처리됩니다. 그 다음, 이 인스턴스들에 지속성이 설정되면 데이터 지속성 RDB(Redis 데이터의 매우 컴팩트한 시점 표현) 스냅샷 또는 AOF(추가 전용 파일)를 용이하게 하는 일부 간격으로 분기된 프로세스가 존재하게 됩니다.
이 두 가지 흐름을 통해 Redis는 장기 스토리지를 보유하고 다양한 복제 전략을 지원하며 보다 복잡한 토폴로지를 사용할 수 있습니다. Redis가 데이터를 유지하도록 설정되지 않았다면, 다시 시작하거나 장애 조치(failover) 시 데이터가 손실됩니다. 재시작 시 지속성이 활성화되면 RDB 스냅샷 또는 AOF의 모든 데이터를 메모리로 다시 로드하고 인스턴스는 새 클라이언트 요청을 지원할 수 있습니다.
이야기한 김에 당신이 사용하고 싶어할 지도 모르는 더 많은 분산 Redis 설정을 살펴보겠습니다.
2. 레디스 HA (High availability)
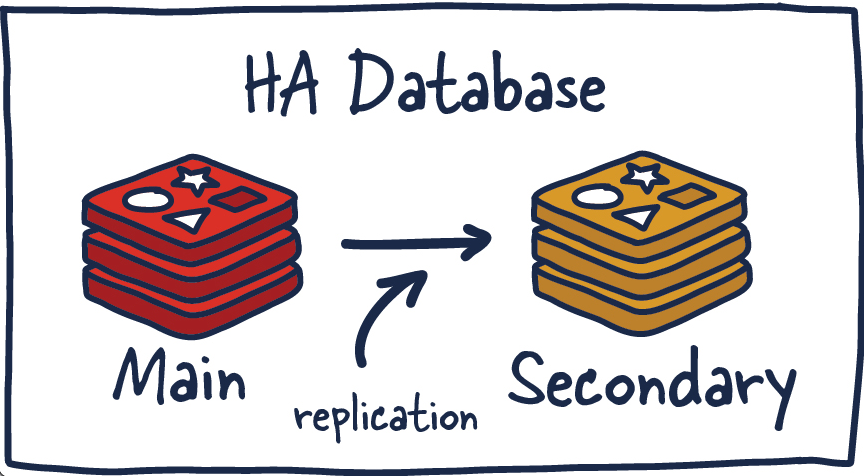
3. 레디스 복제
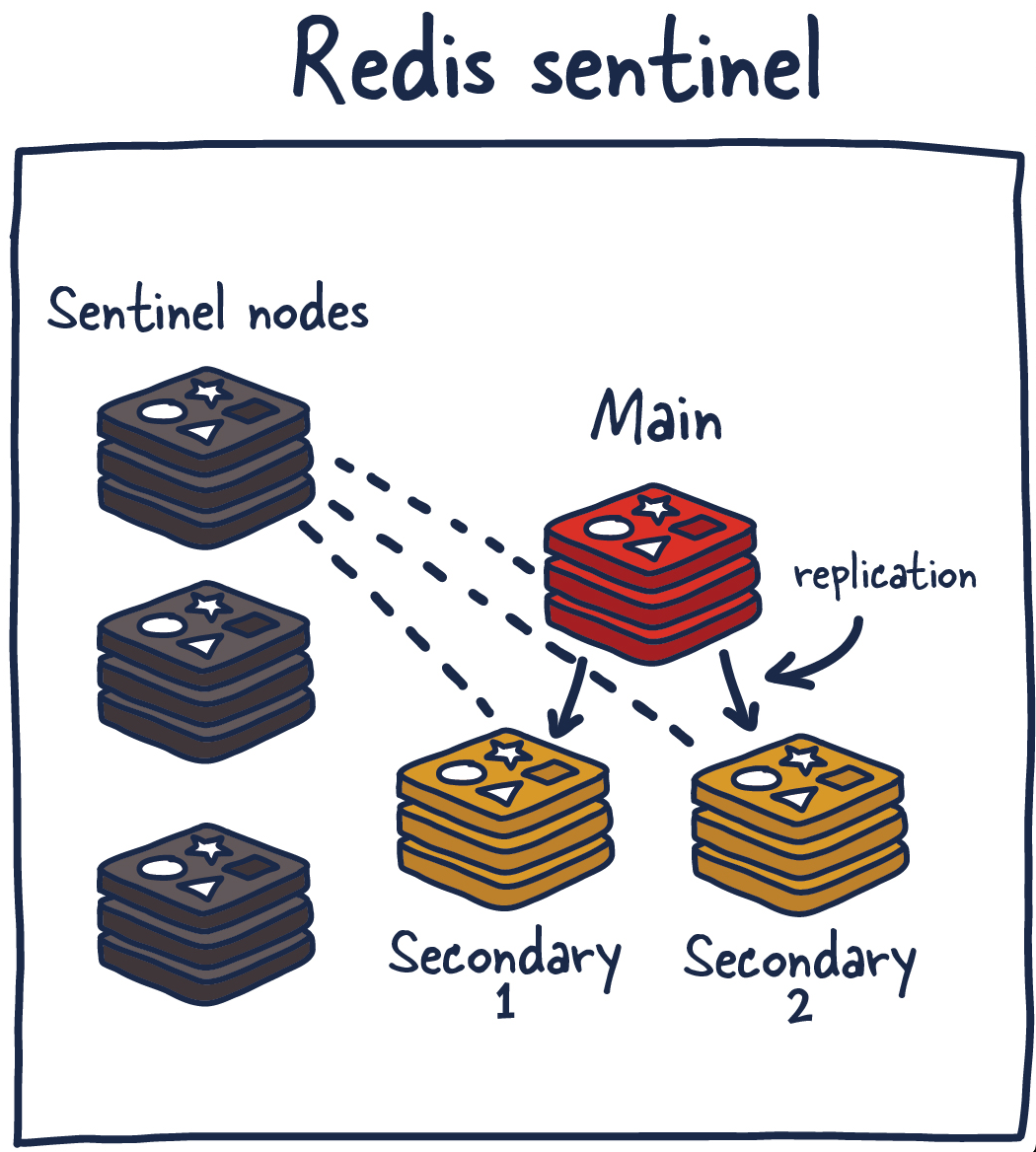
4. 레디스 센티넬
5. 레디스 클러스터