데이터베이스의 규모 확장
수직적 확장
기존 데이터베이스 서버에 더 많은 혹은 더 고성능의 자원을 증설하는 방법이다. 다양한 클라우드 서비스에서 고성능 데이터베이스 서버를 제공하고, 스택오버플로도 천만 명의 사용자 전부를 단 한대의 마스터 데이터베이스로 처리하였지만 몇 가지 심각한 약점이 있다.
- 무한 증설이 불가능하다.
- Single Point of Failure로 인한 위험성이 크다.
- 비용이 많이 든다. 고성능 서버는 비싸다.
수평적 확장
데이터베이스의 수평적 확장은 샤딩(Sharding)이라고도 부르는데, 더 많은 서버를 추가함으써 성능을 확장 시킨다.
모든 샤드는 같은 스키마를 쓰지만 샤드에 보관되는 데이터 사이에는 중복이 없다.
다음은 샤드로 분할된 데이터베이스의 예이다. userId 를 해시하여 데이터가 보관되는 샤드를 정한다.
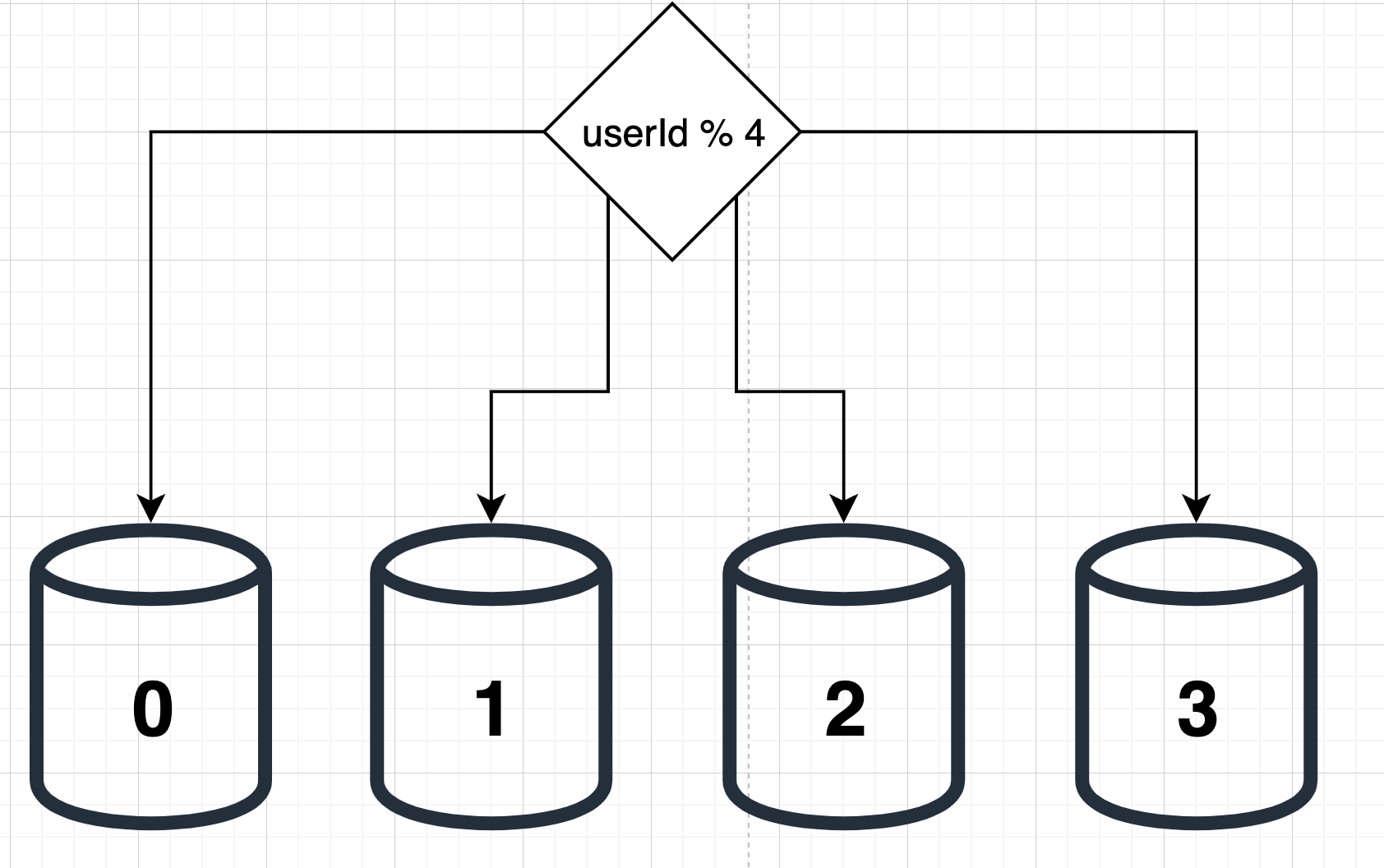
샤딩 전략을 구현할 때 샤딩 키 (Partition Key)를 어떻게 정할지 잘 고려해야한다. 위의 예에서는 userId가 샤딩 키다. 샤딩 키를 정할 때는 데이터를 고르게 분할 할 수 있도록 하는 것이 가장 중요하다.
샤딩을 도입하면 시스템이 복잡해지고 풀어야 할 새로운 문제가 생긴다.
- 데이터의 재 샤딩 : 데이터가 너무 많아져서 샤딩을 다시 샤딩해야할 때 샤드 키를 계산하는 함수를 변경하고 데이터를 재배치해야한다. 5장에서 다룰 안정 해시(Consistent Hashing) 기법을 활용하여 문제를 해결한다.
- 유명인사 문제 : Hotspot Key 문제라고도 하는데 특정 샤드에 질의가 집중되어 서버에 과부하가 걸리는 문제다. 예를 들어 SNS 서비스에서 셀럽들의 데이터가 하나의 샤드에 저장되어 있다면 그 샤드에 부하가 집중될 것이다. 이 문제를 해결하기 위해서는 각 셀럽들에 샤드 하나씩을 할당해야 할 수도 있고 심지어 더 잘게 쪼개야 할 수도 있다.
- 조인과 비정규화 : 일단 하나의 데이터베이스를 여러 샤드 서버로 쪼개면 이들을 조인하기가 힘들다. 데이터베이스를 비정규화하여 하나의 테이블에서 쿼리가 수행되도록 구현한다.
샤딩을 적용한 구조이다.
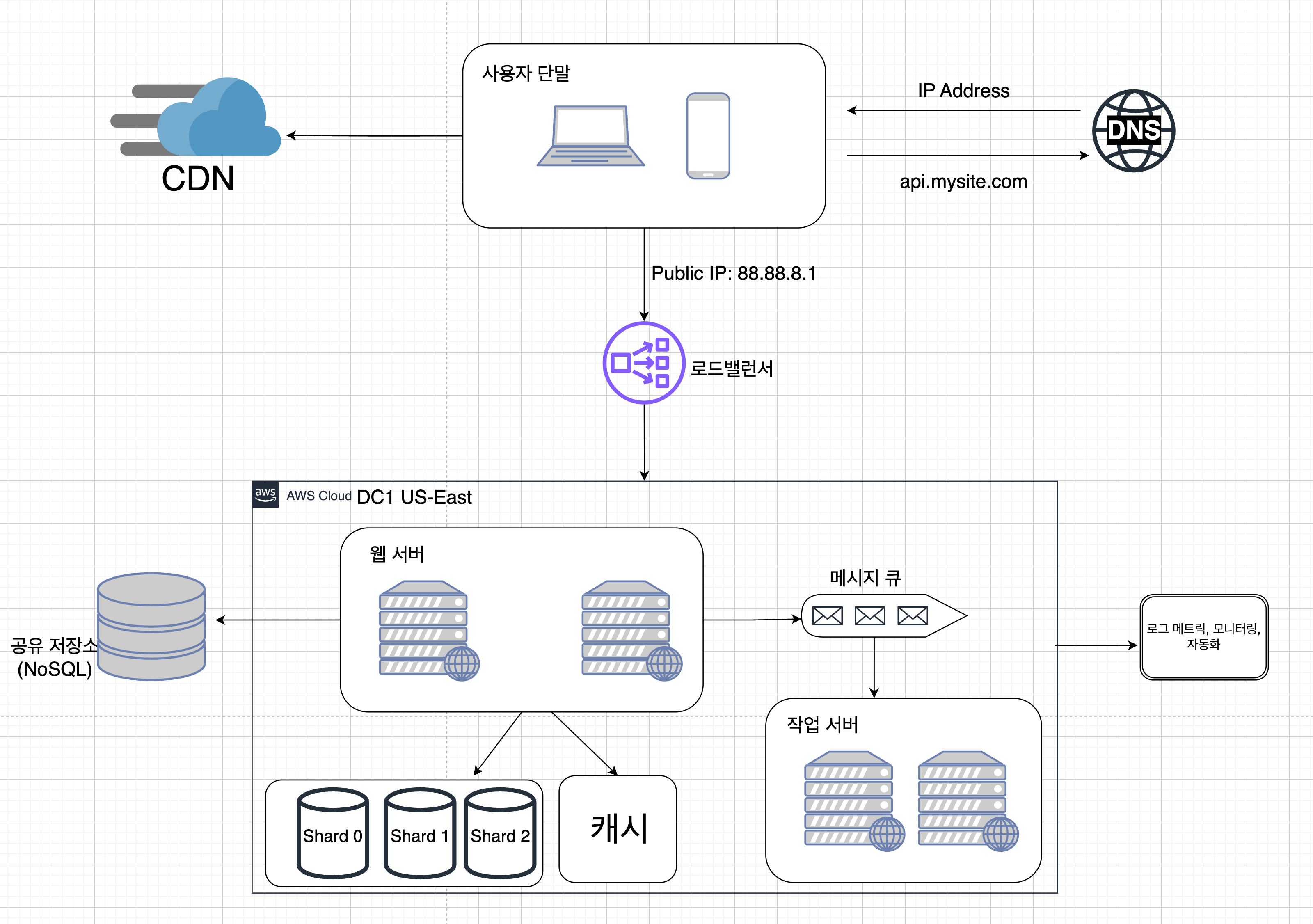
정리
- 웹 계층은 무상태 계층으로
- 모든 계층에 다중화 도입
- 가능한 많은 데이터 캐시
- 여러 데이터 센터 지원
- 정적 콘텐츠는 CDN 사용
- 데이터베이스는 샤딩을 통한 규모 확장
- 각 계층은 독립적 서비스로 분리
- 시스템 모니터링, 및 자동화 도구 활용
본 포스트는 알렉스 쉬 저자의 가상 면접 사례로 배우는 대규모 시스템 설계 기초를 기반으로 스터디하며 정리한 내용들입니다.
