-
일반 Join
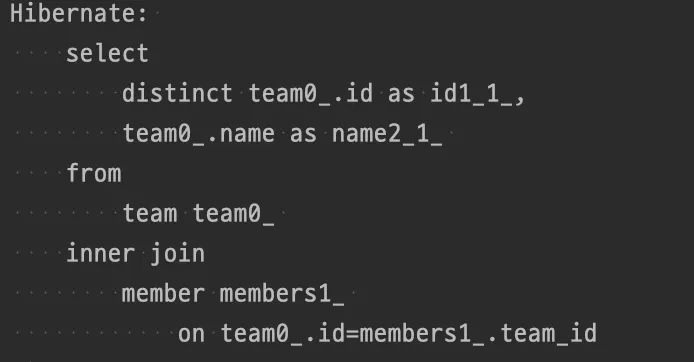
- Fetch Join과 달리 연관 Entity에 Join을 걸어도 실제 쿼리에서 SELECT 하는 Entity는오직 JPQL에서 조회하는 주체가 되는 Entity만 조회하여 영속화
- 조회의 주체가 되는 Entity만 SELECT 해서 영속화하기 때문에 데이터는 필요하지 않지만 연관 Entity가 검색조건에는 필요한 경우에 주로 사용됨
-
Fetch Join
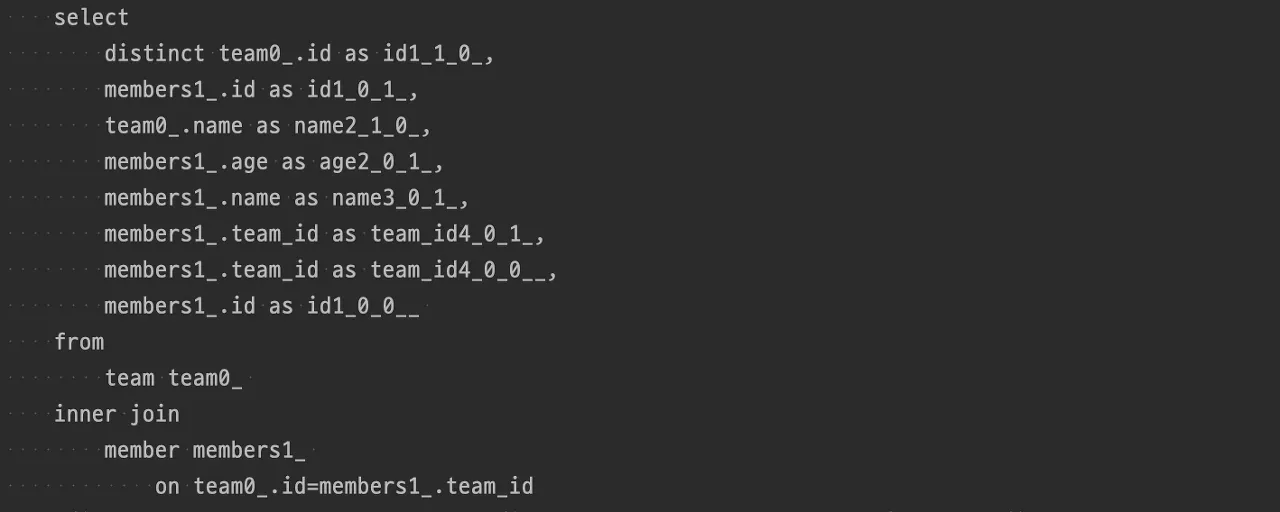
- 조회의 주체가 되는 Entity 이외에 Fetch Join이 걸린 연관 Entity도 함께 SELECT 하여 모두 영속화
- Fetch Join이 걸린 Entity 모두 영속화하기 때문에 FetchType이 Lazy인 Entity를 참조하더라도 이미 영속성 컨텍스트에 들어있기 때문에 따로 쿼리가 실행되지 않은 채로 N+1문제가 해결됨
- fetchType이 Lazy로 설정되어있어도 fetchJoin이 우선순위를 가지기 때문에 한번의 조회로 연관된 엔티티를 같이 조회한다.
Fetch Join의 문제
-
페이징 처리가 안 된다.
- 엔터티와 DB row의 차이를 이해해야 한다고 한다.
- 팀 5팀만 뽑고 싶어서 limit 쿼리로 작성하려고 했는데 실제로 쿼리에는 limit가 생략된다.
- 그렇게 모든 팀에 대한 정보가 나오고 페이징 처리를 백엔드 서버의 메모리에서 하게 된다.
⇒ ManyToOne일 때 페이징 처리, BatchSize 어노테이션 활용
-
조건절 사용 시 데이터 무결성이 깨질 수 있다.
값이 보장되지 않는다면 조인 이전의 필터링인 On 조건이 사용이 불가, Where는 조인 이후의 필터링이기 때문에 원하는 결과가 나오지 않을 수 있고 Limit 문도 이슈가 생길 수 있는 것이다.<aside> 💡 - ex) Select t from Team t join fetch t.member m on m.name=:memberName (memeber 컬렉션이 전부 조회되지 않기 때문에 실행 불가능 한 것을 이해) - ex) Select t from Team t join fetch t.member m on t.name=:teamName (Team을 기준으로 조건을 주었기 때문에 member Collection에는 영향이 없어 문제가 없지 않을까? 라고 생각합니다) - **> 적어주신 쿼리의 의도는 사실 다음과 같은 쿼리입니다. 조인과는 무관하게 Team 자체의 데이터를 필터링 하는 것이기 때문에 on에 사용하는 것은 의도에 맞지 않습니다. 따라서 다음과 같이 where를 사용하는 것이 맞습니다.** </aside> -
여러 엔터티를 동시에 영속성 컨텍스트에 넣기 때문에 2차 캐시 사용 시 캐싱 전략이 꼬여 예상치 못한 Hit/ Miss 상황이 발생해 데이터 정합성에 문제가 생길 수 있다.
-
별칭 부여가 안 된다.
JPA 표준 스펙에는 fetch join 대상에 별칭이 없습니다. 그런데 하이버네이트는 허용. 그 말은 결국 fetch join 대상에 별칭을 사용은 할 수 있지만 문제들이 발생할 수 있으니 주의해서 사용
-
XXXToMany 관계가 2개 이상이면 fetch join 사용 불가
-
OneToMany 상황에서 데이터 중복이 발생한다. ⇒ 부모 엔터티가 자식 개수만큼 중복된다. 여튼 이 상황을 해결하기 위해 메모리에서 부모 엔터티의 중복을 제거한다. ⇒ Distinct를 써서 조회하면 된다고 하긴 함.
이걸 카테시안 곱이라고 하는데 내가 아는 카테시안 곱이랑 다르다.
1차 캐시와 2차 캐시
네트워크를 통해 DB에 접근하는 시간 비용은 애플리케이션 서버에서 내부 메모리에 접근하는 비용보다 훨씬 비싸다.
따라서 조회한 데이터를 메모리에 캐시해서 DB접근횟수를 줄이는 것이 효율적이다.
영속성 컨텍스트 내부에는 엔티티를 보관하는 저장소가 있는데 이것을 1차 캐시라 한다.
그러나 일반적 웹 애플리케이션 환경은 트랜잭션을 시작하고 종료할 때까지만 1차 캐시가 유효하다.
따라서 애플리케이션 전체로 보면 DB접근 횟수를 획기적으로 줄이지는 못한다.
하이버네이트를 포함한 대부분의 JPA구현체들은 애플리케이션 범위의 캐시를 지원하는데, 이것을 공유캐시, 또는 2차캐시라 한다.
