프로젝트 도중 팀원이 refresh token을 구현하고 싶다고 해서 이 기회에 알아봐야할 필요성을 느꼈다.
redis가 인메모리 DB인 것은 예전부터 익히 알던 사실이다.
💡Redis ( Remote Dictionary Server )
오픈소스로 key-value 기반의 인-메모리 데이터 저장소이다. 따라서 key-value 기반이라 쿼리를 날릴 필요 없이 결과를 바로 가져올 수 있고 디스크에 데이터를 쓰는 구조가 아니라 메모리에서 데이터를 처리하기 때문에 속도가 매우 빠르다. (DB를 조회하는 것보다 빠르다.)
Look aside cache(조회 로직)을 보면, 클라이언트가 웹서버에 요청을 하면 웹서버는 먼저 Cache에서 데이터 존재 유무를 확인하다. 이때 Cache에 데이터가 있으면 바로 꺼내주고, 없다면 DB를 확인해서 Cache에 먼저 자장한 후에 클라이언트에게 데이터를 돌려준다.
Write Back(저장 로직)을 보면 클라이언트가 웹서버에 요청을 하면, 웹서버는 DB에 바로 저장을 하는 것이 아니라 Cache에 결과를 쓰고 바로 클라이언트에게 결과 값을 리턴해 준다. 그 후에 Cache 서버에 있는 데이터들을 Worker(워커) 서버들이 데이터를 가져와서 작업을 수행하고 DB에 작성한다. 이렇게 되면 DB는 순차적으로 Transaction을 처리할 수 있게 된다. 정리하면, 데이터를 캐시에 먼저 전부 저장해 둔 후에 특정 시점마다 캐시의 데이터를 DB에 insert 하는 방식이다. insert를 1개씩 500번 하는 것보다 500개를 한 번에 insert 하는 빠르고 성능이 좋다는 것을 알 수 있을 것이다.
캐시 서버는 속도를 위해서 주로 메모리를 사용하기 때문에 서버에 장애가 나면, 메모리가 날아가서 데이터 손실이 발생할 수 있다. 그래서 replication(복제 서버)을 구성하거나 disk를 사용해서 고가용성을 확보하기도 하지만, 비용적 문제가 크게 발생하거나 속도가 어느 정도 낮아질 수 있다는 문제점이 생긴다. 아래에서부터는 Cache 서버로 널리 사용되고 있는 redis에 대해서 알아보자.
Redis 구조
아래와 같이 다양한 데이터 구조를 지원하기 때문에 캐시 데이터 저장, 인증 토큰 저장 등 다양하게 사용 가능하다.
- Strings : 기본적인 key-value 매핑 구조
- [method] opsForValue : String을 Serializable/Deserialize 해주는 interface
- Lists : Array 형식의 데이터 구조(처음과 끝의 데이터 변경은 빠르지만 중간 데이터 수정은 어렵다.)
- [method] opsForList : List을 Serializable/Deserialize 해주는 interface
- Sets : 순서가 없는 Stings 데이터 집합으로 중복 데이터는 제거된다.
- [method] opsForSet : Set을 Serializable/Deserialize 해주는 interface
- Sorted Sets : Sets와 같은 구조지만, Score를 통해 순서를 정할 수 있다.
- [method] opsForZSet : ZSet을 Serializable/Deserialize 해주는 interface
- Hashes : Strings 구조를 여러 개 포함한 object를 저장하기 좋다.
- [method] opsForHash : Hash을 Serializable/Deserialize 해주는 interface
Redis는 Single threaded로 한 번에 하나의 명령어만 실행 가능하다. 따라서 느리다고 생각할 수 있지만, Get/Set명령어를 초당 10만 개 정도 처리할 정도로 빠르다. 그러나 전체 key를 불어오는 것과 같이 처리시간이 긴 명령어를 실행하면 그 뒤에 Get/Set 명령어들은 타임아웃이 나서 요청 실패할 수도 있다.
Redis 서버의 메모리는 maxmemory 값으로 설정 가능하다. 설정한 메모리가 다 차면 max memory policy에 따라서 추가 메모리 확보가 진행된다. 관련 내용은 maxmemory-policy 설정에 대해 공부를 더 해보면 된다.
Spring boot에서 사용하려면 의존성 추가, yml 작성, RedisConfig로 RedisTemplate 생성 ⇒ opsForValue 일반적인 키 밸류 구조의 명령어를 사용할 객체를 요청 ⇒ get, set 메소드로 저장 및 호출
다른 자료형을 쓰고 싶을 때는?
redisTemplate.opsForHash(); // 해시
redisTemplate.opsForList(); // 리스트
redisTemplate.opsForSet(); // 집합
redisTemplate.opsForZSet(); // 정렬된 집합
Redis 용어
- AOF - Append Only File
- 모든 쓰기 명령에 대한 로그를 남기고 저장한다.
- 서버가 재시작 할 시 write/update 를 순차적으로 재실행, 데이터를 복구한다.
- COW - Copy On Write
- redis가 데이터를 쓰기위해 사용하는 메커니즘
- RSS - Resident Set Size
- 데이터를 포함한, redis가 실제로 사용하고 있는 메모리.
- 해당 값은 실제로 사용하고 있는 메모리 값보다 클 수 있다.
Redis 데이터의 영속성 (Redis Persistence)
Redis 데이터의 영속성 (Redis Persistence) Redis는 In-memory DB 임에도 불구하고, 메모리 데이터를 disk에 저장할 수 있는 특징이 있다. 그래서 서버가 꺼진 후 restart되더라도, disk에 저장해놓은 데이타를 다시 읽어서 메모리에 로딩하기 때문에 데이타 유실되지 않는다. 이런 Persistent(영속성) 기능은 휘발성 메모리 DB를 데이터 스토어로서 활용한다는 장점이 있지만 이 기능 때문에 장애의 주 원인이 되기도 한다. 그러므로 이 기능을 잘 알아보고 사용하는게 중요하다. redis에서는 데이타를 저장하는 방법이 RDB (snapshotting) 방식과 AOF (Append only file) 두 가지가 있다. RDB 방식은 특정한 각격마다 메모리에 있는 레디스 데이터 전체를 디스크에 쓰는 것이다. (백업에 용이) AOF 방식은 명령이 실행될때 마다 데이터를 파일에 기록하여 데이터의 손실이 거의 없다. 이 두가지에 대해 상세히 알아보고 차이점과 활용법을 알아보자.
- RDB 방식은 특정한 각격마다 메모리에 있는 레디스 데이터 전체를 디스크에 쓰는 것이다. (백업에 용이)
- AOF 방식은 명령이 실행될때 마다 데이터를 파일에 기록하여 데이터의 손실이 거의 없다.
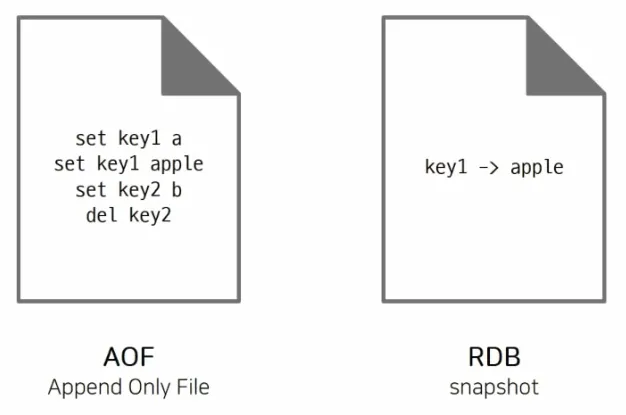
RDB (snapshotting) 방식
인메모리 데이터를 주기적으로 파일에 저장하는데, Redis 프로세스가 장애로 인해 종료되더라도 해당 파일을 읽어들이면 이전의 상태를 동일하게 복구할 수 있다.
우리가 직접 세팅하지 않더라도 Redis는 자동으로 .rdb 라는 확장자의 파일에 인메모리 데이터를 저장하도록 디폴트 설정
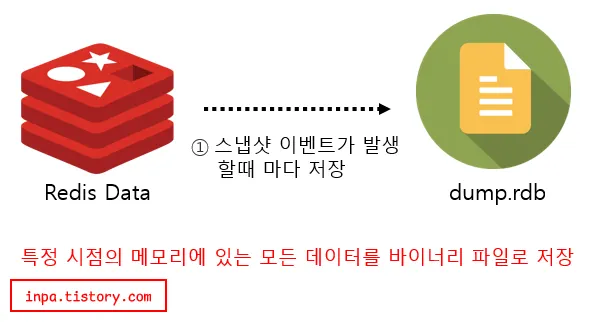
RDB(snapthot)는 순간적으로메모리에 있는 내용을 스냅샷을 떠서 DISK에 옮겨 담는 방식이다. 스냅샷을 뜬다는 말은 특정 시점의 메모리에 있는 데이터를 바이너리 파일로 저장하는 뜻이다.
RDB 방식은 메모리의 snapshot을 그대로 저장하기 때문에 서버를 재구동 할 때 snapshot을 다시 읽으면 되므로 속도가 빠른 장점이 있다.그러나, snapshot을 추출하는데 시간이 오래걸리고 도중에 서버가 꺼지면 이후의 데이터를 모두 사라진다는 단점이 있다.
RDB 저장 방식
SAVE와 BGSAVE 두 가지가 있다.
- SAVE는 순간적으로 redis의 동작을 정지시키고 그 snapshot를 디스크에 저장.(blocking 방식)
- BGSAVE는 백그라운드 SAVE 라는 의미로 별도의 자식 프로세스를 띄운 후, 명령어 수행 당시의 snapshot을 disk에 저장하고, redis는 동작을 멈추지 않게 된다. (non-blocking 방식)
SAVE 동작순서
- Main process가 데이터를 새 RDB temp 파일에 쓴다.
- 쓰기가 끝나면 기존 파일을 지우고, 새 파일로 교체한다.
BGSAVE 동작 순서
-
Child process를 fork() 한다.
-
Child process는 데이터를 새 RDB temp 파일에 쓴다.
-
쓰기가 끝나면 기존 파일을 지우고, 이름을 변경한다.
BGSAVE 방식은 fork를 하기 때문에 메모리를 거의 두 배 가량 사용하므로 이에 주의해야 한다.
AOF (Append Only File) 방식
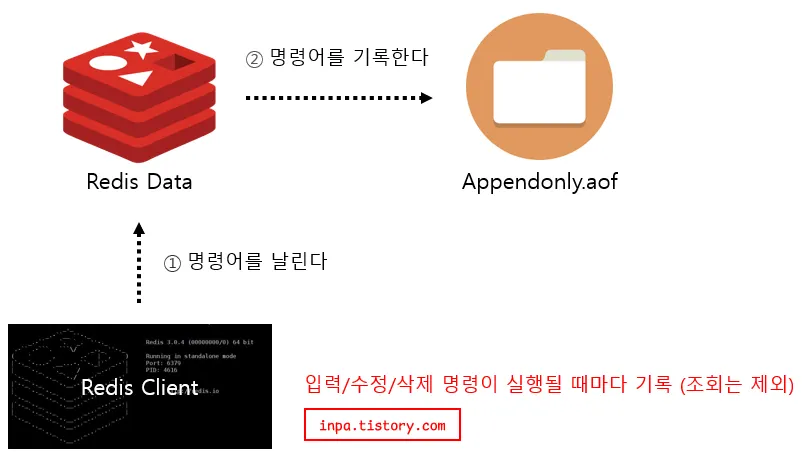
AOF(Append On File) 방식은 redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태이다.
default로 appendonly.aof 파일에 기록되며, 조회를 제외한 입력/수정/삭제 명령이 실행될 때 마다 기록된다
그리고 서버가 재시작될 때, log에 기록된 write/update 연산을 재 실행하는 형태로 데이터를 복구하는 방식이다.
즉, 다음과 같은 순서로 데이터가 저장된다.
- 클라이언트가 Redis 에 업데이트 관련 명령을 요청한다.
- Redis 는 해당 명령을 AOF에 저장한다.
- 파일쓰기가 완료되면 실제로 해당 명령을 수행해서 Redis 메모리에 내용을 변경한다.
이처럼, operation이 발생할때 마다 매번 기록하기 때문, RDB 방식과는 달리 특정 시점이 아니라 항상 현재 시점까지의 로그를 기록할 수 있으며, 기본적으로 non-blocking 으로 동작 된다.
AOF는 log 파일에 대해서만 append하기 때문에 log write 속도가 빠르고 어떤 시점에 서버가 다운되더라도 데이터가 사라지지 않는 장점이 있다.
RDB는 바이너리 파일이라서 수정이 불가능했지만, AOF 로그 파일은 text 파일이므로 편집이 가능하다.
- 클라이언트가 Redis 에 업데이트 관련 명령을 요청한다.
- Redis 는 해당 명령을 AOF에 저장한다.
- 파일쓰기가 완료되면 실제로 해당 명령을 수행해서 Redis 메모리에 내용을 변경한다.
모든 write/update 연산을 log파일에 남기기 때문에 log 데이터 양이 굉장히 크고, 복구 시 저장된 모든 write/update연산을 다시 실행하기 때문에 재시작 속도가 느린 단점 ⇒ 예를 들어 set 명령이 key는 같고 값을 다른 조건에서 여러번 수행되었다고 하면, 메모리에는 마지막 수행된 값만 남아있지만, AOF에는 수행된 모든 기록이 남아있기 때문
rewrite를 수행하면 이전 기록은 모두 사라지고 최종 데이터만 기록
참고 : https://inpa.tistory.com/entry/REDIS-📚-데이터-영구-저장하는-방법-데이터의-영속성#aofappend_only_file방식
