
TIL
🍔오늘 할 일
프로젝트 발표 보조- 프로젝트 회고 및 복습 : 아직 모두 하지 못함.
중간에 추가된 일
프로젝트 피드백
중간에 취소된 일
🍟새로 알게된 내용
프로젝트 피드백
shape value VS feature importance
- 두 방식 모두 변수가 끼친 영향에 대해 분석 할 수있는 기법이지만, feature importance 변수의 영향이 음의 방향인지 양의 방향인지 구분 할 수없고, 변수 개별로 불수가 없다.
스벅조 피드백의 F-1스코어 외에 다른지표들
- 클래스가 임밸런스하다 = 데이터 클래스 분포가 불균형하다.
할때 사용된다.
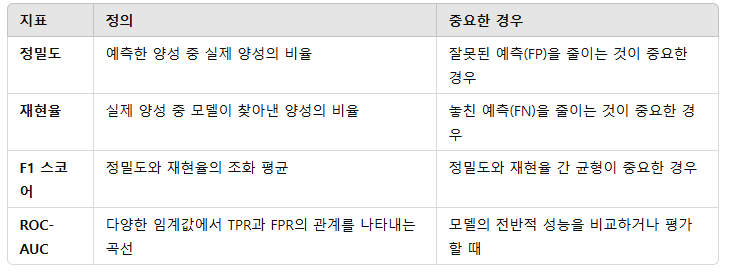
Precision(정밀도) - 예측한 양성중 실제 양성 비율, 잘못된 양성 예측을 얼마나 줄였는가?(양성으로 예측한 환자에게 불피요한 치료를 최소화 해야할 때)
Recall(재현율) -실제로 양성인 사람이 예측한 양성 비율, 즉 놓친 양성을 얼마나 줄였는가?(암환를 놓치는 일을 줄이는게 중요할 때)
ROC-AUC - 모델의 분류 성능을 시각화하는 그래프입니다.
그리드 서치란?
- 하이퍼 파라미터에 들어갈 적절한 값을 찾아내는 방법이다
다만 컴퓨터 사양의 문제가 있어 찾는데 오랜 시간이 걸린다.
-보완법-
랜덤 서치를 사용한다.(그럼 그리드는 안써도되나..? 왜쓰지?=> 뭔가 찝찝할때 사용)
튜터님께 들어보니 컴퓨터 성능이 애매하면 머신러닝이든 딥러닝이든 랜덤서치를 사용하자. 특히 딥러닝은 반드시 랜덤서치를 써야한다.
PPT자료를 그대로 포트폴리오로 낼 때 주의점
- 제출시 발표용이아니라 문서로 넘김을 의식하고 텍스트가 PPT보다 더 많이 필요하다.(PPT에서 말로 설명한 중요한 부분을 첨부)
가격과 관련된 이상치 처리엔 주의!
- 결제 금액에 대해선 이상치가 늘 다른 관점으로 볼 필요가 있다.
매달 결제 평균 30만원일 때, 매달 2~3억결제하는 분이 과연 이상치인가?
DBSCAN
- 밀도 기반 군집, 일반적으로 k-means에서 k값을 정해 군집한 것과 다르게 밀도자체를 보는 방식. K값 설정고민이 없는 점, 원모양이아닌 불특정 형태의 군집도 찾을 수 있다.
※ k-means: 군집을 시킬 범위
입실론을 통해 포함시킬 밀도 정도를 선택 할 수 있다.
또한 이때 k-거리 라는 개념이 나오는데 K-Means와는 아무관련없는 지표이다.
데이터 페인(DataPane)
- 데이터 시각화와 대화형 대시보드 제작을 간소화하는 Python 기반의 오픈소스 라이브러리
import datapane as dp
import pandas as pd
# 샘플 데이터프레임 생성
df = pd.DataFrame({
'Year': [2020, 2021, 2022],
'Sales': [100, 150, 200]
})
# 대시보드 생성 및 시각화
report = dp.Report(
dp.Table(df), # 데이터프레임 테이블
dp.Plot(df.plot(x='Year', y='Sales', kind='line')) # 플롯 추가
)
# 대시보드 저장
report.save("dashboard.html")차원축소는 2~3정도까지 내려오는게 좋다
🥤계획 및 회고
프로젝트의 마지막인 발표날이다. 조원분인 수현님께서 발표하시기로 하셨지만, 그 보조를 위한 준비를 진행하였다. (크게 도움된건지는 모르겠다.) 장정 4시간의 프로젝트 발표와 피드백으로 느낀점과 알아간점이 많아 알찬 발표시간이었다. 이제 오늘 저녁부터 수요일까지 머신러닝 개인과제 해결을 해야한다. 또한 내일부턴 새로운 조가 편성될텐데 어떤분들과 만날까? 기대된다.😄
내일 계획
- 머신러닝 프로젝트 회고 및 복습 계속하기
- 머신러닝 개인과제 완료
- 새로운 팀과의 적응

데이터 분석가를 꿈꾸고 있습니다.