
TIL
🍔오늘 할 일
QCC 5회차스파크 완강크롤링 라이브섹션
중간에 추가된 일
중간에 취소된 일
🍟새로 배운 것
크롤링
크롤링에 앞서 항상 사이트명 뒤에 robot.txt를 붙여 위법성을 확인해야한다.
만약 크롤링 하려는 사이트가 유튜브라면
https://www.youtube.com/robots.txt
식으로 하면된다.
수업중에는 자세히 다루지 않아 따로 찾아 정리 해보았다.
User-agent: *
Disallow: /admin/
Disallow: /private/
Allow: /public/
Sitemap: https://example.com/sitemap.xml
Crawl-delay: 10이런 형식을 가지는데
User-agent
- 크롤러를 특정하기 위해 사용
- 예를들어 User-agent: *는 모든 크롤러를 대상
Disallow
- 크롤링이 허용되지 않는 경로
- 비어있으면 모두 허용하는 경우가 된다.
- 예를들어 Disallow: /admin/ 형태면 admin에 대한 크롤링을 허가하지 않는 다는 의미이다.
Allow
- 크롤링이 허용되는 경로이다.
- 위의 disallow와 반대되다보니 allow보단 disallow로 불가능한것 만 출력되는 경우가 많다.
Sitemap
- 웹사이트의 사이트맵 URL을 지정
- 검색 엔진 크롤러에게 해당 사이트의 구조를 알리는 지도 파일의 위치를 제공
- 이 파일은 크롤러가 웹사이트의 모든 페이지를 효율적으로 탐색하고 색인화(Indexing)할 수 있도록 도움
- 예를 들어
User-agent: *
Disallow: /private/
Sitemap: https://example.com/sitemap.xml- 이런 형태라면 크롤러는 /private/ 디렉토리를 제외하고 사이트맵에서 제공된 경로들을 기준으로 사이트를 탐색한다는 의미가 된다.
Crawl-delay
- 선택적으로 사용되는 옵션인데 크롤링 오쳥 간의 지연시간이 설정된다.
- 뒤의 숫자는 초단위의 의미가된다
- 예를들어 Crawl-delay: 10이라면 10초의 딜레이다.
주소 확인 방법
(구글 크롬을 사용하자) 인터넷에 원하는 사이트에 들어가서 F12를 누르면 개발자툴이 열리는데 이때
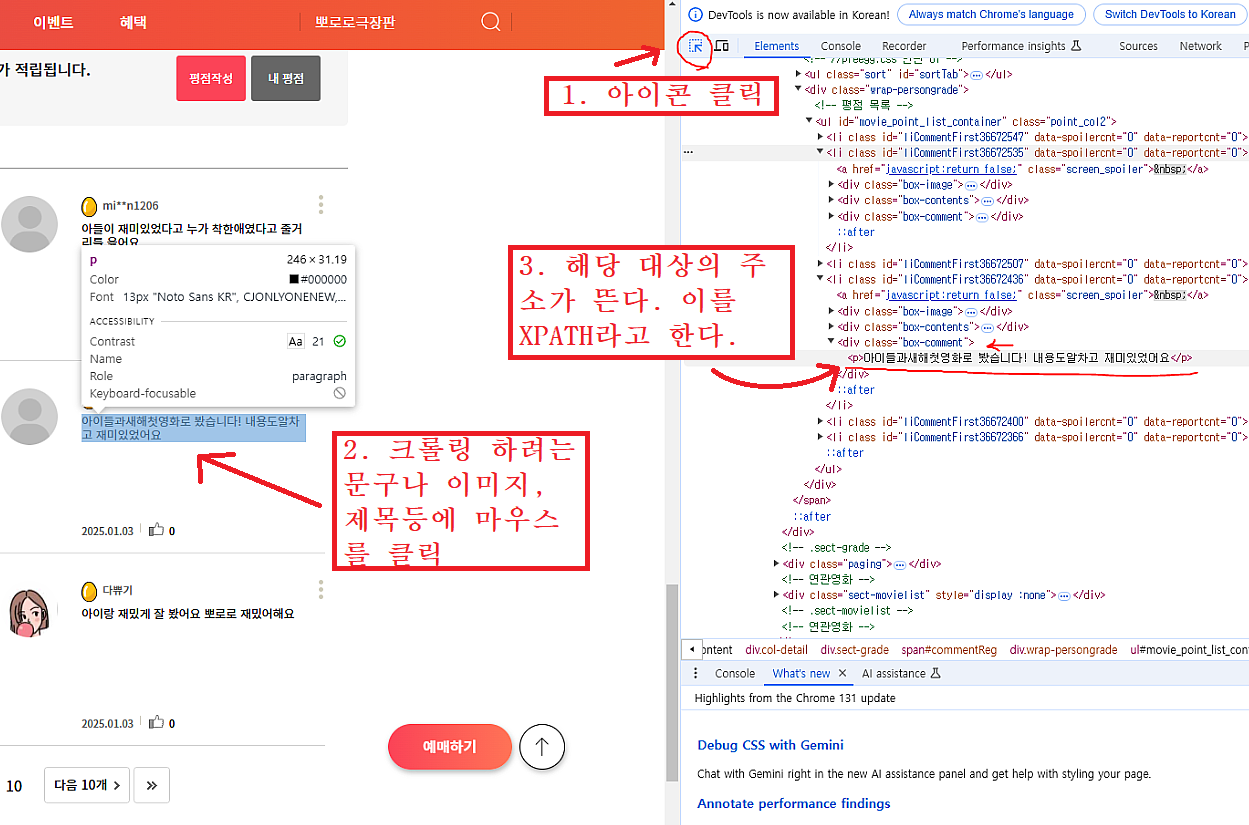
여기서 해당 주소에 마우스 우클릭을 눌러 XPATH를 복사하여 파이선에서 사용할 수 있다.
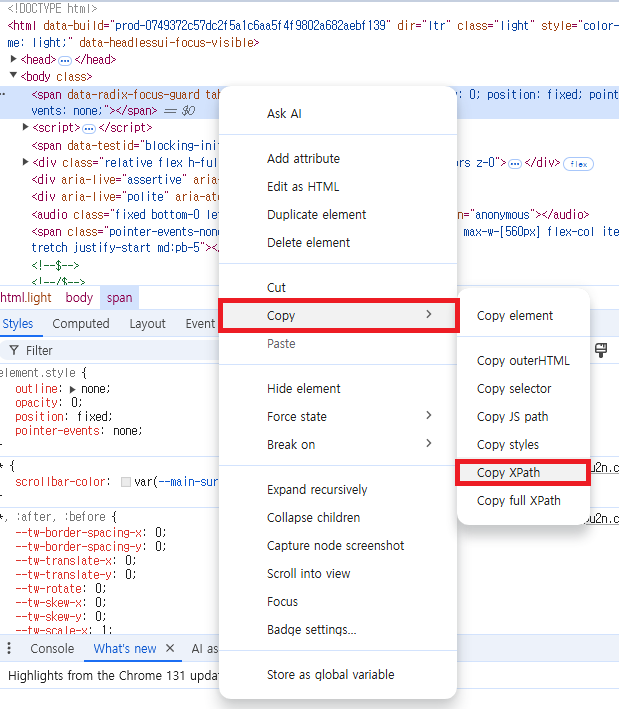
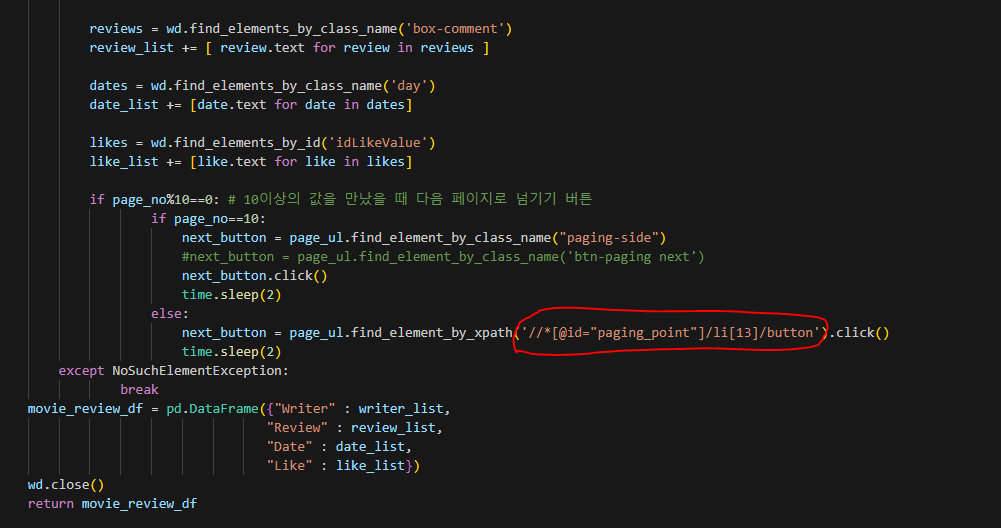
(XPATH주소가 사용된 모습)
본격적으로 크롤링 코드를 사용하여 파이선으로 데이터를 가져와 사용하는 방법은 별도의 문서로 만들어 진행하여 프로젝트에 이용할 예정이라 크롤링 내용은 여기서 일단 끊고 다음에 작성하겠다.(코드에 대한 해석이 많이 들어가 페이지가 길어질꺼 같다. 추후 TIL을 수정하여 링크를 달아두려 한다)😎
🥤계획 및 회고
크롤링 방법도 알았겠다.. 본격적으로 최종데이터에 사용할 유저 코멘트를 모아보려했는데, 대다수 사이트가 허가하지않아 곤란한 상황이다. 수집가능한 게임을 고를건지.. 고른게임의 코멘트를 수동수집할건지 고민해봐야할 것 같다.
내일 계획
- 최종 프로젝트용 게임데이터 탐방

데이터 분석가를 꿈꾸고 있습니다.