
🍔 오늘 할 일
데이터 계속 받기EDA- 머신러닝 돌입
중간에 추가된 일
대용량이라 샘플링해야 돌아간다는 결론 = 적정 샘플링 찾기
중간에 취소된 일
🍟 프로젝트
데이터 수집 완료😎
모든 데이터를 수집하였다. 최종적으로 31기가의 데이터 분량이 모였다.(...)
그래도 데이터를 많이 모았으니 분석은 수월하겠지? 라고 생각하던 내가 오전에 있었다...
데이터가 너~~~무많아😱
본격적으로 1만개씩 모은 데이터를 모두 모아 합치..려했는데 데이터가 너무많아 메모리가 터져버려 VS가 꺼진다.🎊 어쩔수 없이 30일 단위로 끊어서 총 90일로 3묶음으로 만들었다.(그 와중에 1개 만들때 마다 vs를 껏다키지 않으면 다음 작업이 메모리 부족으로 터졌다..🎊)
그래도 분석하려면 적어도 신규 유저가 접었다는 기준인 30일이 넘는 데이터가 한번에 분석가능 해야 했기에 90일치 데이터를 모으기위해 조금이라도 안쓰일거 같은 컬럼을 쳐내고 쳐내서 다이어트 시켜 겨우 합쳤다.(그리고 터졌다🎊....)
EDA
그래도 데이터가 많아서 그런지 우리가 예측한 대로 통계데이터가 나왔다.
우리는 커뮤니티의 평가와 스팀구매 게시판의 리뷰를 보고 ' 이 게임은 초보자가 게임을 하기 힘든 게임이라 떠나는 신규 유입이 많다' 라는 전제로 시작한 작업인데
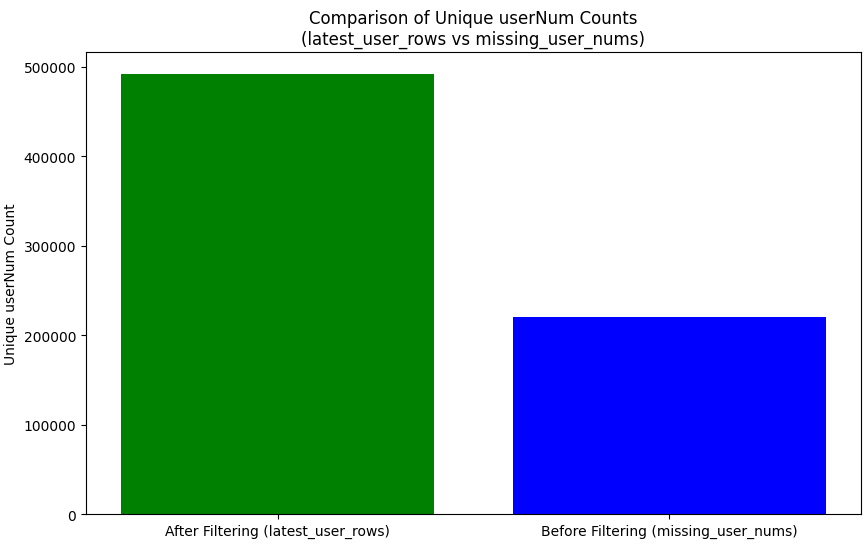
전체 유저중에 30일 이상 게임기록이 없는 사람이 절반에 해당할 정도로 상당히 많다.(보편적으로 게임회사는 30일간 미접속이면 접었다고 판정한다.)
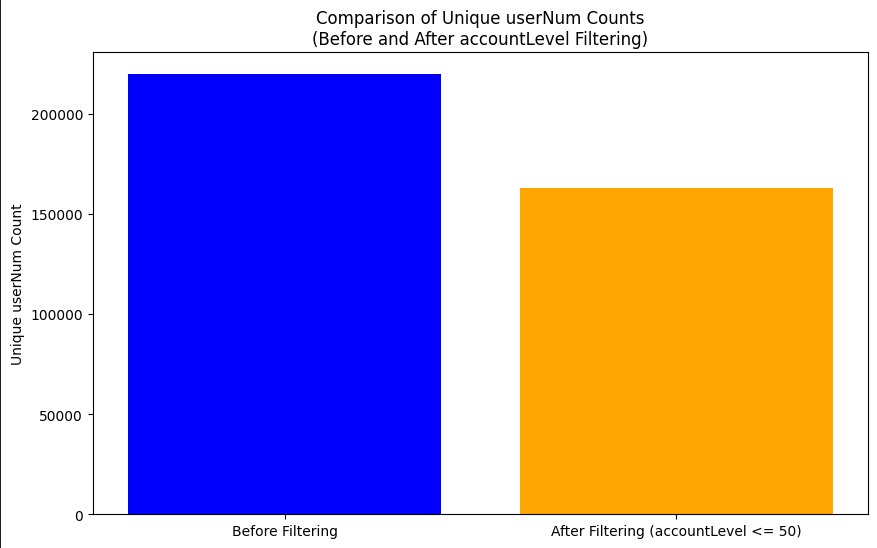
이 접은 사람들 중에 상당수가 레벨 50도안되는 뉴비에 해당한다(75프로 정도)
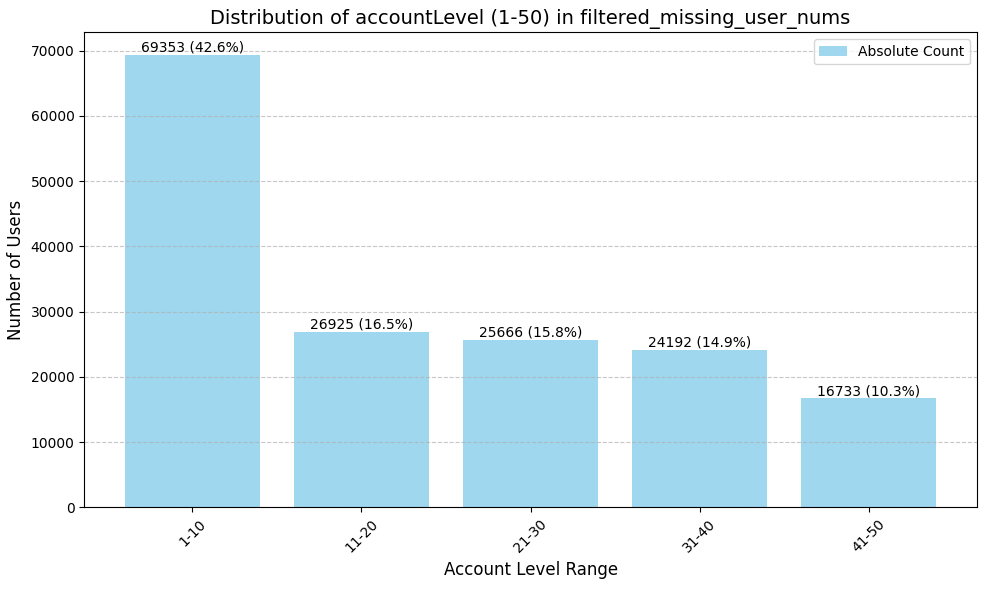
그리고 그 뉴비중에 상당수가 10랩 전에 접고 있음을 알 수 있었다.
우리가 문제시 삼았던 튜토리얼 미흡, 부족한 연습게임(AI전), 심각한 정보의 불균형이 영향을 주고 있다고 생각한다.
머신러닝
90일 전체 그룹에 90일중에 30일 이내 플레이 기록이 없는 생존자 그룹을 제외한 그룹을 '잔존1'
반대의 경우를 '잔존0'으로잡고 어떠한 컬럼이 잔존에 영향을 주는지 이진분석에 들어갔다.
일단 데이터가 커서;; 통째로 하니 터진다🎊😥
그래서 랜덤샘플링으로 진행하였고 제법 그럴듯한 결과가 나왔으나 클래스 비율이
맞지않아 balanced_accuracy가 낮게 나와 이를 보안하기위해 데이터가 많다 보니 언더 샘플링으로 진행하였고, 계선은 되었으나 나머지 값이 떨어졌다.
그래서 SMOTE를 이용해 오버샘플링을 해보려한다. 다만 데이터가 증가하는 경우다보니 랜덤샘플링 수치를 조정하며 메모리가 터지지않고 돌아가는 최적의 샘플수를 찾고있다.
🥤 계획 및 회고
설날전날이지만 이제 최종발표까지 2주남았다. 쉴시간은 없고 머신러닝을 계속할 예정이다.
내일 계획
- 머신러닝하기
