Bidirectional Encoder Representations from Transformers
큰 텍스트 코퍼스(위키피디아 같은)를 이용하여 범용목적의 언어 이해 모델을 훈련시키는 것과 그 모델에 관심있는 실제의 자연 언어 처리 태스크(질문, 응답 등)에 적용하는 것이다.
특징
- 엄청난 규모의 언어 모델을 pretrain하였다.
- 어떤 task에도 약간의 fine-tuning만을 통해 손쉽게 적용하여 해결 가능하다.
- 딥 양방향(deeply bidirectional)
- BERT는 Transformer 모델에 기반한다.
- Contextual Word Embedding
- WordPiece 모델 사용
KorQuAD
The Korean Question Answering Dataset, 한국어 질의응답 데이터셋
한국어 MRC(Machine Reading Comprehension, 기계독해)를 위해 LG CNS에서 구축한 대규모 질의응답 데이터셋이다.
- 평가 척도
- EM(Exact Match) : 모델이 정답을 정확히 맞춘 비율
- F1 score : 모델이 낸 답안과 정답이 음절 단위로 겹치는 부분을 고려한 부분점수
- 1-example-latency : 질문당 응답속도
- 버전 1.0 vs 2.0 차이점
- 문서의 길이 : 지문의 길이가 1.0은 한두 문단 정도지만 2.0은 위키백과 한 페이지 분량
- 문서의 구조 : 2.0에는 표와 리스트가 포함되어 있어 html 태그를 이해할 수 있어야 함
- 답변의 길이와 구조 : 1.0에서는 단어나 구 단위였으나, 2.0에서는 표와 리스트를 포함한 긴 영역의 답변 가능
BERT 모델 구조
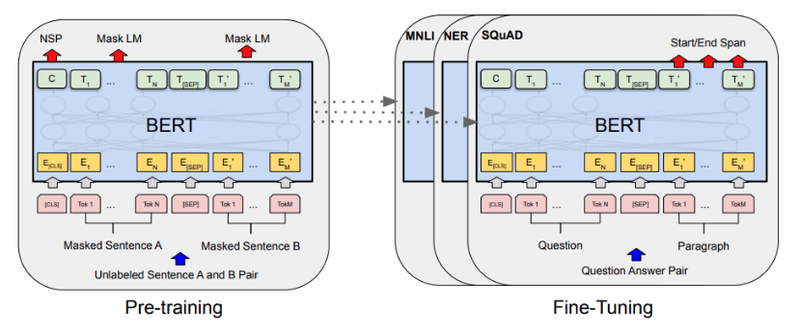
- Transformer 모델 선 이해 필요
- Self-Attention으로 이루어진 Encoder-Decoder구조를 가지고 있어 번역기 모델 형태를 구현하는데 적당했다.
- BERT는 Transformer Encoder 구조만을 활용한다.
- Layer 개수는 12개 이상으로 늘리고 전체적으로 파라미터 크기가 늘어났다.
- decoder를 사용하지 않고 어떻게 BERT는 학습할까? BERT는 두가지 unsupervised task로 pre-train시킨 모델이다.
Mask LM
- BERT에서 pre-train을 위해 사용한 첫번째 task, Mask LM 방식
- 입력 데이터가
나는 <mask> 먹었다일 때 BERT 모델이<mask>가밥을임을 맞출 수 있도록 하는 언어 모델이다. 즉 다음 빈칸에 알맞는 단어는? 이 문제를 엄청나게 풀어보는 언어모델을 구현한 것이다. - 입력데이터의 특정 퍼센트의 랜덤 단어를 왜곡하는 기법으로, 논문에 따르면 80%는 \로 마스킹하고 10%는 다른 단어로 치환하고 10%는 그대로 둔 채로 왜곡한 뒤 Transformer encoding을 거친 후 해당 파트를 예측하는 구성이다.
NSP
- BERT에서 pre-train을 위해 사용한 두번째 task, Next Sentence Prediction
- 입력데이터가
나는 밥을 먹었다. <SEP> 그래서 지금 배가 부르다.가 주어졌을 때<SEP>를 경계로 좌우 두 문장이 순서대로 이어지는 문장이 맞는지를 맞추는 문제.
BERT input
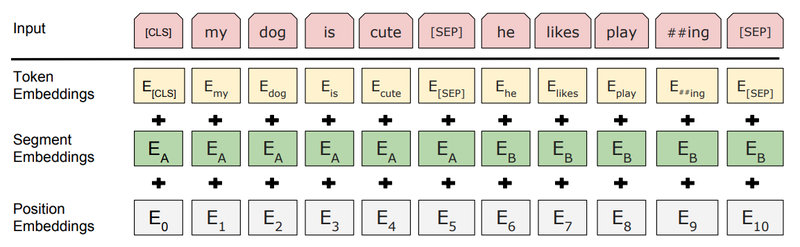
Token Embedding
- BERT는 텍스트의 tokenizer로 Word Piece model이라는 subword tokenizer를 사용
- 문자(char) 단위로 임베딩하는 것이 기본이지만, 자주 등장하는 긴 길이의 subword도 하나의 단위로 만들어 준다. 자주 등장하지 않는 단어는 다시 subword 단위로 쪼갠다.
- 이것은 자주 등장하지 않는 단어가 OOV(Out-of-vocabulary) 처리되는 것을 방지해준다. 그래서 최종적으로 Word Piece모델의 각 임베딩이 입력된다.
Segment Embedding
- 각 단어가 어느 문장에 포함되는지 그 역할을 규정하는 것
- QA 문제처럼 이 단어가 Question 문장에 속하는지, Context 문장에 속하는지 구분이 필요한 경우에 이 임베딩은 매우 유용하게 사용
- 각각의 Sentence는 실제로는 수 개의 sentence로 이루어져 있을 수 있다(eg. QA task의 경우 [Question, Paragraph]에서 Paragraph가 여러개의 문장). 그래서 두 개의 문장을 구분하기 위해, 첫째로는 [SEP] token 사용, 둘째로는 Segment embedding을 사용하여 앞의 문장에는 sentence A embedding, 뒤의 문장에는 sentence B embedding을 더해준다.(모두 고정된 값)
Position Embedding
- 기존의 Transformer에서 사용되던 position embedding과 동일
code
참고 사이트
BERT 알아보기
BERT 논문정리
MRC가 뭐예요?
인공지능(AI) 언어모델 ‘BERT(버트)'는 무엇인가

한 줄 소개가 자연스러워지는 그날까지