프록시란 👋
프록시란 '대리', '대신'이라는 뜻을 가지며 무언가를 중간에서 대신 해준다는 의미를 가지고 있다.
즉 코드레벨에서 보자면 프록시 기술은 어떤 원본 객체가 해야할 작업을 대신 해주는 객체를 만드는 것이다.
프록시 기술의 요구사항
그렇다면 이러한 프록시 기술은 어떤 요구사항에서 출발 했을까 🤔
요구사항의 핵심은 부가기능 이다.
프록시 기술은 “원본 코드에 영향을 주지않고 부가기능을 유연하게 추가한다” 라는 요구사항을 충족시켜준다.
프록시 패턴과 데코레이터 패턴의 차이
프록시 패턴에 대해서 얘기하기 전에 프록시 패턴과 데코레이터 패턴의 차이에 대해서 짚고 넘어갈 필요가 있다.
두 패턴은 모두 프록시 기술을 사용한다. 하지만 두 패턴은 프록시 기술을 통해 행하고자 하는 의도가 다르다.
💡 프록시 패턴의 핵심 의도는 접근제어이며 데코레이터 패턴의 핵심 의도는 기능 확장이다.
프록시 패턴
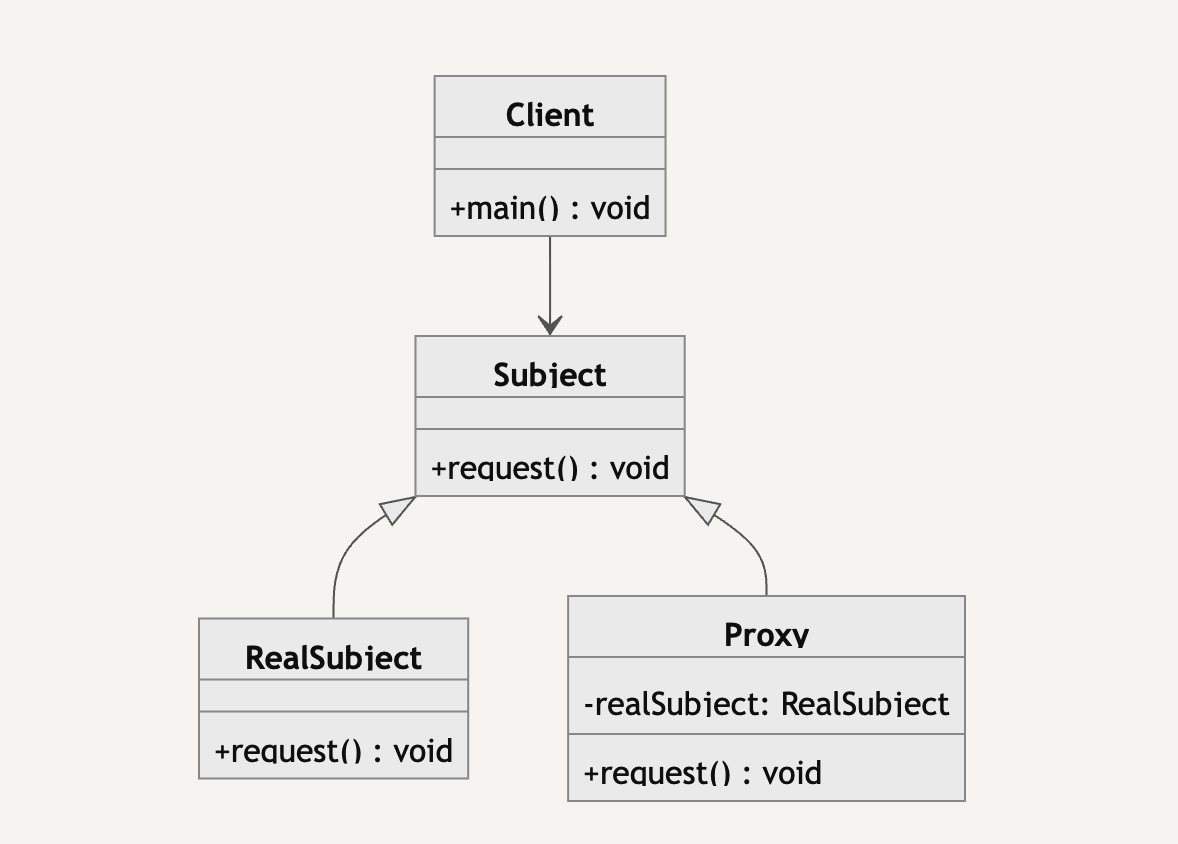
프록시 패턴의 구조는 위와 같으며 3가지 주요 객체가 있다.
Subject: 프록시 객체가 모방할 인터페이스(인터페이스를 통한 방법 말고도 프록시 패턴을 가져갈 수 있는데, 현재는 이해를 위해 인터페이스를 예시로 들겠다)RealSubject: 실제 핵심 로직이 담겨있는 객체Proxy: 핵심 객체인 RealSubject 를 가지고 RealSubject 에 대한 접근을 제어하는 대리자 객체
해당 구조에서 Client 는 단순히 Subject 객체만을 이용하지만 Proxy 객체를 통한 접근제어와 RealSubject 를 통한 실제 핵심 로직을 사용할 수 있다.
💡 핵심은 핵심 로직인
RealSubject객체와 접근제어라는 부가기능인Proxy객체가 분리되었다는 것이다.
프록시 패턴 사용법
1. 인터페이스를 통한 프록시
- 프록시 클래스가 Subject 인터페이스를 구현한다. (위그림과 같은 구조)
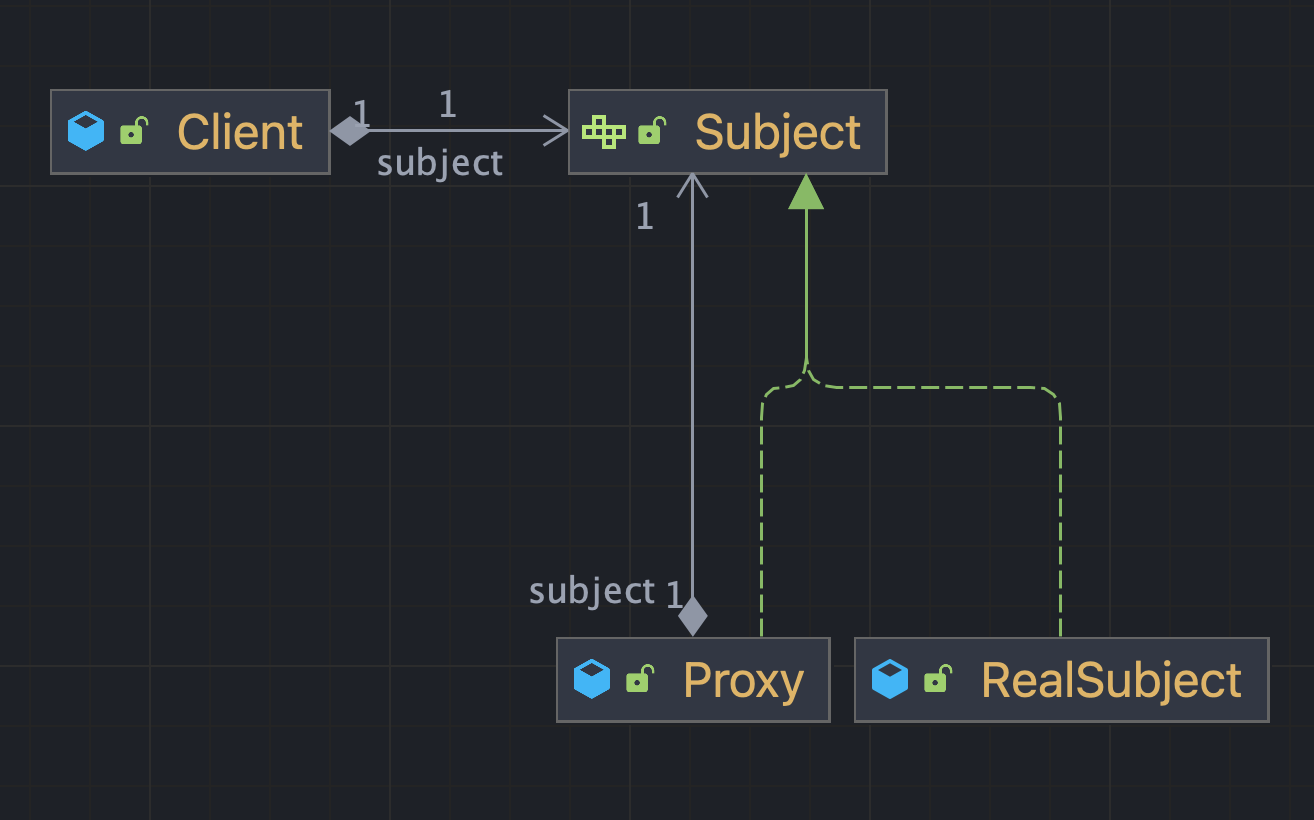
public class Proxy implements Subject {
private final Subject subject;
public Proxy(final Subject subject) {
this.subject = subject;
}
@Override
public void request() {
// 프록시 로직
subject.request();
//프록시 로직
}
}- Proxy 클래스는 Subject 인터페이스를 구현하며 생성자를 통해 실제 로직을 수행할 객체를 주입받는다
- 메소드를 오버라이딩하며 실제 로직 호출 외의 부가적인 프록시 로직을 추가한다
public class Client {
private final Subject subject;
public Client(final Subject subject) {
this.subject = subject;
}
public void doRequest() {
subject.request();
}
//=================================================
public static void main(String[] args) {
Subject subject = new RealSubject();
Client client = new Client(subject);
Client proxyClient = new Client(new Proxy(subject));
client.doRequest();
proxyClient.doRequest();
}
}이렇게 클라이언트는 Subject 라는 인터페이스만 들고있으며, 프록시를 사용할 때에는 원본 객체를 들고있는 프록시 객체를 넣어주면 된다.
사용할 때는 어떤 구현체를 넣더라도 클라이언트 코드는 변하지 않는다.
2. 구체 클래스를 통한 프록시
- 프록시 클래스가 구체 클래스인 Subject 를 상속한다
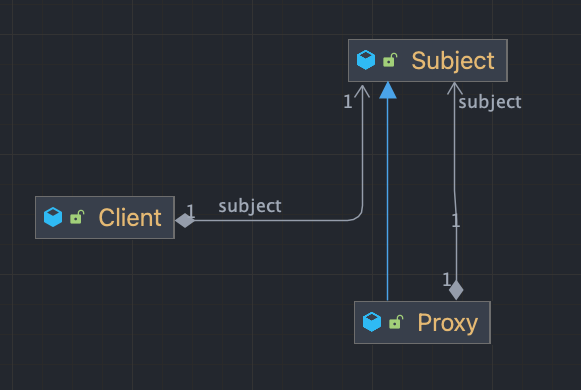
public class Proxy extends Subject {
private final Subject subject;
public Proxy(final Subject subject) {
super(null, null);
this.subject = subject;
}
@Override
public void request() {
//프록시 로직
subject.request();
//프록시 로직
}
}- 프록시 클래스는 Subject 클래스를 상속하며, 실제 로직을 수행할 Subject 클래스를 주입받는다
- Subject 클래스의 메소드를 오버라이딩하며 실제 로직 호출 외에 부가적인 로직을 수행한다
public class Client {
private final Subject subject;
public Client(Subject subject) {
this.subject = subject;
}
public void doRequest() {
subject.request();
}
// =============================================
public static void main(String[] args) {
Subject subject = new Subject(10, "name");
Client client = new Client(subject);
Client proxyClient = new Client(new Proxy(subject));
client.doRequest();
proxyClient.doRequest();
}
}이렇게 클라이언트는 Subject 라는 구체 클래스만 들고있으며, 프록시를 사용할 때에는 원본 객체를 들고있는 프록시 객체를 넣어주면 된다.
사용할 때는 어떤 클래스를 넣더라도 클라이언트 코드는 변하지 않는다.
프록시 패턴의 장점
- 핵심 로직과 부가기능의 분리를 통한 원본코드의 변경없는 유연한 확장
- SOLID 의 개방폐쇄원칙(OCP)을 만족한다
- SOLID 의 단일책임원칙(SRP)을 만족한다
- 다형성의 활용을 통한 변경없는 클라이언트 코드
프록시 패턴의 단점
- 코드의 복잡성
- 프록시 클래스를 만들기 위해 특정 인터페이스를 구현하거나 구체 클래스를 상속하며 실제 객체와의 동기화를 구현해야하기 때문에 코드가 복잡해질 수 있다
- 한 부가기능에 대해서 다른 클래스에 적용한다고 한다면 하나의 프록시 클래스가 아닌 여러개의 프록시 클래스를 추가하고 관리해야한다
이러한 프록시 패턴의 단점에 대한 보완에 대해서는 아래에서 다루겠다 🫡
프록시 패턴의 종류와 예시
- 프록시 패턴이 활용되는 종류와 각 종류별 예시에 대해서 다뤄보겠다
- 프록시 패턴에 사용되는 프록시는 원격 프록시, 가상 프록시, 보호 프록시, 캐시 프록시처럼 여러가지가 있지만 해당 포스팅에서는 우리가 자주 접할 수 있는 가상프록시, 캐시 프록시에 대해서 다뤄보겠다.
1. 가상 프록시
- 가상 프록시는 실제 객체의 생성 또는 초기화를 지연시키는 데 사용된다. 비용이 많이 드는 객체나 대용량 데이터를 로드해야 할 때 유용하다.
예시 상황
- Book 객체는 Image(인터페이스) 라는 객체를 필드로 가진다.
- Image 인터페이스의 구현체인 RealImage 를 로드할 때 많은 시간이 걸린다.
public class Book {
private final String title;
private final String authorName;
private final Image image;
public Book(String title, String authorName, Image image) {
this.title = title;
this.authorName = authorName;
this.image = image;
}
public String getTitle() {
return title;
}
public String getAuthorName() {
return authorName;
}
public String getImageResource() {
return image.getImageResource();
}
}public interface Image {
String getImageResource();
}public class RealImage implements Image {
private final String imageResource;
public RealImage() {
System.out.println("RealImage 로드(굉장한 로딩시간)");
this.imageResource = "imageResource";
}
public String getImageResource() {
return imageResource;
}
}프록시 적용 전
public class NoProxyApp {
public static void main(String[] args) {
Book noProxyBook = new Book("title", "name", new RealImage());
System.out.println("다른 로직 수행");
System.out.println(noProxyBook.getTitle());
}
}해당 로직에서는 Image 에 대한 조회가 이루어지지 않는다.
하지만 해당 코드를 실행하면 아래처럼 실제로 RealImage 를 로드하며 불필요한 리소스가 생긴다

프록시 적용 후
public class ProxyImage implements Image {
// 실제로 수행되는 객체
private Image subject;
public ProxyImage() {
System.out.println("가상 프록시 객체 생성");
}
public String getImageResource() {
if (subject == null) {
subject = new RealImage();
}
return subject.getImageResource();
}
}위 코드는 프록시 객체에 실제 RealImage 객체가지고 있다가 실제로 Image 에 대한 호출이 생길때 RealImage 로드하는 프록시 객체다
public class ProxyApp {
public static void main(String[] args) {
Book proxyBook = new Book("title", "name", new ProxyImage());
System.out.println("다른 로직 수행");
System.out.println(proxyBook.getTitle());
}
}위의 ProxyImage 를 적용해서 사용하면 아래와 같이 Image 에 대한 정보를 호출하지 않으면 RealImage 에 대한 로드가 일어나지 않는다

만약 getTitle()을 출력하는 코드 이후에 getImageResource()메소드를 호출하면 호출 시점에 RealImage 를 로드하는 것을 볼 수 있다.

이렇게 가상 프록시를 이용하면 지연로딩을 통해 자원을 효율적으로 사용할 수 있다
실제로 JPA 의 지연로딩 또한 이러한 가상 프록시를 이용해서 구현돼 있다
2. 캐싱 프록시
- 캐싱 프록시는 객체에 대한 요청을 처리할 대 결과를 캐시에 저장하여 이후에 동일한 요청이 들어왔을 때 캐시된 결과를 반환하는 프록시로 동일한 요청에 대해 성능 향상에 도움을 준다
예시 상황
- Storage 인터페이스를 구현한는 MemoryStorage 가 있다.
- MemoryStorage 는 조회를 할 때 한번 조회할 때마다 2초라는 시간이 걸린다
public interface Storage {
String getDataById(final long id);
}public class MemoryStorage implements Storage {
private final Map<Long, String> storage;
public MemoryStorage() {
storage = new HashMap<>();
storage.put(1L, "dataA");
storage.put(2L, "dataB");
storage.put(3L, "dataC");
}
@Override
public String getDataById(long id) {
System.out.println("조회 시작...");
sleep(2000);
return storage.get(id);
}
private static void sleep(final int millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}Memory Storage 에서 데이터를 조회하면 조회할 때마다 2초라는 시간이 걸리는 무자비한 성능을 보여준다.
public class CachingApp {
public static void main(String[] args) {
measureTime(() -> {
System.out.println("캐싱없는 스토리지");
Storage storage = new MemoryStorage();
System.out.println(storage.getDataById(1L));
System.out.println(storage.getDataById(1L));
System.out.println(storage.getDataById(1L));
});
}
// 시간을 입력된 로직의 수행시간을 측정하는 메소드
private static void measureTime(final Runnable runnable) {
Instant before = Instant.now();
runnable.run();
Instant after = Instant.now();
Duration duration = Duration.between(before, after);
System.out.println("소요시간 : " + duration.getSeconds());
}
}실제로 실행해보면

이처럼 3번 조회에 6초라는 무지막지한 시간이 걸리는 것을 볼 수 있다.
프록시 적용 후
public class CachingStorage implements Storage {
private final Map<Long, String> cache;
private final Storage subject;
public CachingStorage(final Storage subject) {
this.cache = new HashMap<>();
this.subject = subject;
}
@Override
public String getDataById(long id) {
if (cache.containsKey(id)) {
return cache.get(id);
}
String data = subject.getDataById(id);
cache.put(id, data);
return data;
}
}해당 프록시 클래스는 내부에 캐시 저장소를 들고있으며 실제 데이터를 호출하는 subject 를 가지고 있다.
조회 하려는 id 에 대한 데이터가 캐시 저장소에 있으면 실제 저장소를 호출하지 않고 캐시 데이터를 내보내며 없을 경우에는 실제 조회를 하고 캐시 스토리지에 저장한다
public static void main(String[] args) {
measureTime(() -> {
System.out.println("캐싱 스토리지");
Storage storage = new CachingStorage(new MemoryStorage());
System.out.println(storage.getDataById(1L));
System.out.println(storage.getDataById(1L));
System.out.println(storage.getDataById(1L));
});
}실제로 실행해보면
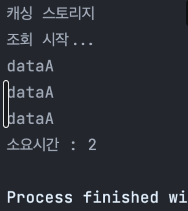
첫 조회에 소요되는 2초를 제외하고는 캐시 데이터를 사용하여 2초라는 시간이 걸리는 것을 볼 수 있다.
이렇게 캐싱 프록시를 통해서 쉽게 성능을 향상 시킬 수 있으며,
수동, 시간 기반, 이벤트 기반 등 다양한 방법으로 캐싱 데이터를 업데이트하며 사용할 수 있다.
실제로 스프링의@Cacheable어노테이션도 캐싱 프록시를 통해 구현되었다.
프록시 패턴의 단점 극복
앞에 프록시 패턴의 단점에 대해서 코드의 복잡성을 언급했다
프록시 클래스를 생성하고 관리하는데 있어서 코드가 복잡해질 수 있는데, 생성에서의 복잡성을 해결하기 위해서 자바에서는 동적 프록시(Dynamic Proxy)기술을 제공하며 외부 기술인 CGLIB 를 통해서도 해결할 수 있다.
또한 이 두 기술을 더 편하게 사용할 수 있도록 스프링은 프록시 팩토리(Proxy Factory) 라는 기술을 지원한다.
그리고 생성과 관리의 복잡성까지 한번에 해결할 수 있도록 스프링에서는 Spring AOP의 다양한 기술을 제공한다.
이에 대해서는 추후에 포스팅 해보도록 하겠다 🫡
