CLIP(Contrastive Language-Image Pretraining) 모델을 간단히 설명을 하면, 텍스트와 이미지간의 유사도를 계산하는 모델입니다.
좀 더 구체적으로 설명하자면, 텍스트 인코더를 통해 임베딩된 값과 이미지 인코더를 통해 임베딩 된 값을 대조(contrastive)하여 맵핑되도록 학습을 하고, 이를 통해 텍스트 기반의 이미지 검색 또는 이미지 기반의 특징적인 텍스트 검색을 할 수 있도록 합니다.
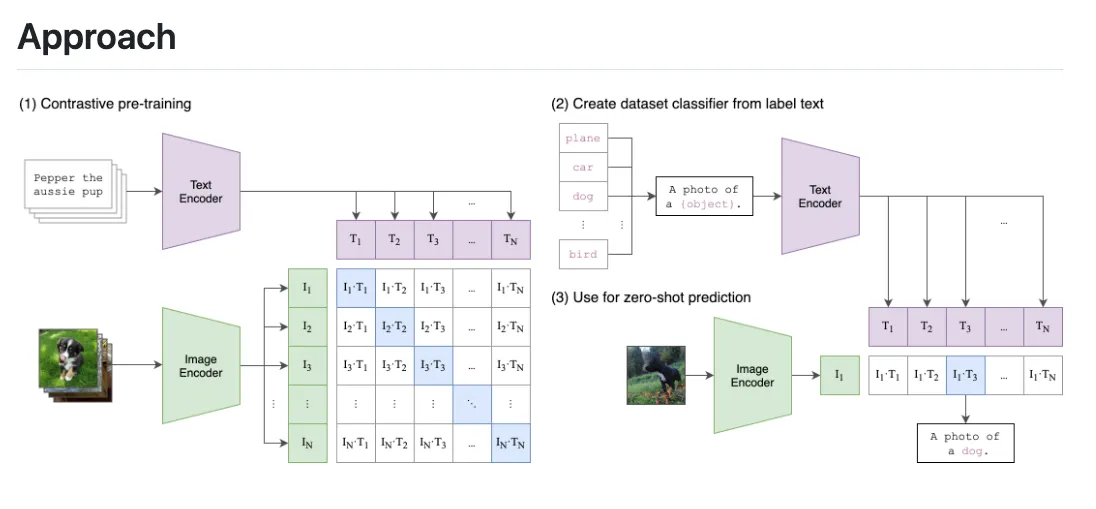
아래 이미지는 CLIP에 대해 잘 묘사해주는 그림인데요,
(1) Contrastive pre-training 이 학습 과정에 대한 설명
(2) Create dataset classifier from label text 는 텍스트 기반의 이미지 검색
(3) Use for zero-shot prediction 은 이미지 기반의 특징적인 텍스트 검색
부분을 설명하고 있다고 보면 되겠습니다.
이제, CLIP 모델 구조를 코드를 뜯어보면서 구체적으로 확인 해보도록 하겠습니다.
1. CLIP 모델 사용해보기
금강산도 식후경이란 말처럼 CLIP모델을 한번 사용해보도록 하겠습니다.
모델은 huggingface에서 clip-vit-base-patch32 모델을 다운로드 하여 사용하였습니다.
코드는 아래의 도넛 이미지와 4개의 텍스트를 input으로 넣고, 이미지와 가장 유사한 텍스트가 무엇인지 찾아보는 실험 입니다.
- 텍스트 : ["a photo of a cat", "a photo of a car", "a photo of a noodle", "a photo of a donut"]

from PIL import Image
from urllib.request import urlopen
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("D:/models/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("D:/models/clip-vit-base-patch32")
url = "https://upload.wikimedia.org/wikipedia/commons/a/a5/Glazed-Donut.jpg"
image = Image.open(urlopen(url))
inputs = processor(text=["a photo of a cat", "a photo of a car", "a photo of a noodle", "a photo of a donut"],
images=[image],
return_tensors="pt",
padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
print(probs)
# tensor([[1.7283e-06, 2.1896e-06, 2.0641e-06, 9.9999e-01]], grad_fn=<SoftmaxBackward0>)각 텍스트 별 유사 확률을 보면 donut이 99.99% 확률로 원하는 결과가 나왔습니다.
1. "a photo of a cat" : 1.7283e-06
2. "a photo of a car" : 2.1896e-06
3. "a photo of a noodle" : 2.0641e-06
4. "a photo of a donut" : 9.9999e-01 => 99.99%
다른 방법으로 이미지를 여러개 input으로 넣고 텍스트와 가장 유사한 이미지를 출력하는 방법도 위와 동일한 방법으로 수행하고 logits_per_text 프로퍼티를 확인하면 된답니다.
이제 본격적으로 모델을 뜯어보도록 하겠습니다.
2. Overall
CLIP모델의 전체 전반적인 구조를 보도록 model 을 print 해보도록 하겠습니다
print(model)
"""
CLIPModel(
(text_model): CLIPTextTransformer(
(embeddings): CLIPTextEmbeddings(
(token_embedding): Embedding(49408, 512)
(position_embedding): Embedding(77, 512)
)
(encoder): CLIPEncoder(
(layers): ModuleList(
(0-11): 12 x CLIPEncoderLayer(
(self_attn): CLIPAttention(
(k_proj): Linear(in_features=512, out_features=512, bias=True)
(v_proj): Linear(in_features=512, out_features=512, bias=True)
(q_proj): Linear(in_features=512, out_features=512, bias=True)
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(layer_norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
)
(layer_norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)
)
(final_layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(vision_model): CLIPVisionTransformer(
(embeddings): CLIPVisionEmbeddings(
(patch_embedding): Conv2d(3, 768, kernel_size=(32, 32), stride=(32, 32), bias=False)
(position_embedding): Embedding(50, 768)
)
(pre_layrnorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(encoder): CLIPEncoder(
(layers): ModuleList(
(0-11): 12 x CLIPEncoderLayer(
(self_attn): CLIPAttention(
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(layer_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
)
(layer_norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(visual_projection): Linear(in_features=768, out_features=512, bias=False)
(text_projection): Linear(in_features=512, out_features=512, bias=False)
)
"""결과를 보면, CLIP 모델은 4개의 하위 모델과 세부 Layer로 이루어져 있다는 것을 확인할 수 있습니다.
1. text_model
- embeddings
- encoder
- final_layer_norm
- vision_model
- embeddings
- pre_layernorm
- encoder
- post_layernorm
- visual_projection
- text_projection
큰 구조를 확인했으니, 이제 각각의 모델에 대해 파악해 보도록 하겠습니다.
3. Text_model
text_model 은 embeddings, encoder, final_layer_norm 의 children으로 구성되어 있고, 각 Layer 별 코드와 실제 데이터를 넣어 중간 결과들을 출력하여 어떤식으로 데이터가 변환되는지 확인해보도록 하겠습니다.
3-1) embeddings
먼저, embedding 부분의 foward() 메서드 부분입니다.
modeling_clip.py (206 Line)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
) -> torch.Tensor:
seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
if inputs_embeds is None:
inputs_embeds = self.token_embedding(input_ids)
position_embeddings = self.position_embedding(position_ids)
embeddings = inputs_embeds + position_embeddings
return embeddingsembedding의 forward() 메서드에 텍스트가 들어가기 전에, 예시인 a photo of a donut 이란 데이터는 preprocessor를 통해 tokenizer 가 이루어 집니다.
processor.tokenizer('a photo of a donut', return_tensors='pt')
# {'input_ids': tensor([[49406, 320, 1125, 539, 320, 18471, 49407]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}다음으로 텍스트(단어)의 순서 정보를 부여하기 위한 position_ids를 가지게 되는데, 0부터 순차적으로 부여된다고 보면 됩니다.
예시의 단어 토큰은 tensor([[49406, 320, 1125, 539, 320, 18471, 49407]]) 이므로, position_ids는 tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8]]) 값을 가지게 됩니다.
그리고, 단어 토큰인 input_ids 와 단어 위치인 posiotion_ids 가 각각의 임베딩 모델로 들어가서 고정된 차원의 정보를 가질 수 있도록 되는데요, shape가 아래처럼 바뀌게 됩니다.
- input_ids [1, 9] -> input_embeds [1, 9, 512]
- position_ids [1, 9] -> position_embeddings [1, 9, 512]
그 후 최종적으로 두 값을 더한 embeddings 값이 return 되도록 구현이 되어있습니다.
embeddings = inputs_embeds + position_embeddings
즉, 'a photo of a donut' 라는 텍스트가 [1, 9, 512] 차원의 텐서로 임베딩 되어 출력이 되는 거죠.
3-2) encoder
다음으로 encoder 부분의 forward() 메서드 부분입니다.
modeling_clip.py (577 line)
def forward(
self,
inputs_embeds,
attention_mask: Optional[torch.Tensor] = None,
causal_attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutput]:
r"""
Args:
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Causal mask for the text model. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
hidden_states = inputs_embeds
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
encoder_layer.__call__,
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)encoder 부분은 training을 통해 가중치 수정이 가능하게 되어 있습니다.
큰 맥락은 for문으로 encoder_layer를 반복하면서 embedding된 값과 attention_mask를 통해 출력을 받고, Return 하는 구조로 되어 있습니다.
여기서 encoder_layer는 아래와 같이 MSA(Masked Self-Attention) 구조인 CLIPEncoderLayer 를 12번 반복하는 (0-11): 12 x CLIPEncoderLayer 구조로 되어 있습니다.
(encoder): CLIPEncoder(
(layers): ModuleList(
(0-11): 12 x CLIPEncoderLayer(
(self_attn): CLIPAttention(
(k_proj): Linear(in_features=512, out_features=512, bias=True)
(v_proj): Linear(in_features=512, out_features=512, bias=True)
(q_proj): Linear(in_features=512, out_features=512, bias=True)
(out_proj): Linear(in_features=512, out_features=512, bias=True)
)
(layer_norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=512, out_features=2048, bias=True)
(fc2): Linear(in_features=2048, out_features=512, bias=True)
)
(layer_norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)즉, 3-1에서 만들어진 embedding 출력과 attention_mask를 CIPEncoderLayer 12개로 이루어진 모델의 input 넣어 encoding된 값을 출력하게 됩니다.
예시의 encoder 결과는 Tensor(1, 9, 512) 형태로 출력되도록 되어있습니다.
3-3) final_layer_norm
text_model 의 마지막은 final_layer_norm 으로 pytorch의 fintional 메소드를 이용한 간단한 Layer 입니다.
normalization.py (195 line)
def forward(self, input: Tensor) -> Tensor:
return F.layer_norm(
input, self.normalized_shape, self.weight, self.bias, self.eps)Layer normalization에 대한 설명은 생략하도록 합니다.
4. Visual_model
visual_model 은 embeddings, pre_layernorm, encoder, post_layernorm 의 하위 children 으로 구성되어 있습니다.
먼저, preprocessor를 통해 입력된 Pillow Image의 변환과정에 대해 확인을 했습니다. (image_processing_clip.py 해석)
- do_convert_rgb : 이미지를 rgb로 변환
- to_numpy_array : 이미지를 numpy array로 변환
- do_resize : H, W 중 짧은 축을 224로 resize, 예시의 경우 (224, 342) size로 됨.
- do_center_crop : 이미지 센터 부분 (224, 224) 크기를 Crop
# center_crop 코드 발췌
# In case size is odd, (image_shape[0] + size[0]) // 2 won't give the proper result.
top = (orig_height - crop_height) // 2
bottom = top + crop_height
# In case size is odd, (image_shape[1] + size[1]) // 2 won't give the proper result.
left = (orig_width - crop_width) // 2
right = left + crop_width- do_rescale : 이미지값에 1/255 값을 곱함. 즉 0-1 로 변환
- do_normalize : mean=[0.48145466, 0.4578275, 0.40821073], std=[0.26862954, 0.26130258, 0.27577711] 로 Normalization
# normalization 코드 발췌
if input_data_format == ChannelDimension.LAST:
image = (image - mean) / std
else:
image = ((image.T - mean) / std).T- to_channel_dimension_format : channel first 형태로 차원 변경
- dictionary : "pixel_values" key에 최종 변환된 image tensor를 value로 dictionary 생성
위와같이 preprocessing 된 이미지(3, 224, 224 Tensor)를 visual_model 의 Input으로 넣게 되며, 각 구성요소별로 어떻게 처리가 되는 지 살펴보도록 하겠습니다.
4-1) embeddings
embedding 부분의 forward() 메서드 부분입니다.
modeling.py (181 Line)
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
batch_size = pixel_values.shape[0]
target_dtype = self.patch_embedding.weight.dtype
patch_embeds = self.patch_embedding(pixel_values.to(dtype=target_dtype)) # shape = [*, width, grid, grid]
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
class_embeds = self.class_embedding.expand(batch_size, 1, -1)
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
embeddings = embeddings + self.position_embedding(self.position_ids)
return embeddingsembedding 부분은 patch_embedding 과 position_embedding 으로 되어 있습니다.
patch_embedding은 입력된 이미지를 conv2d(3, 768, kernel_size=(32,32), stride=(32,32), bias=False) 의 컨볼루션을 통해 입력되는 (3, 224, 224) 차원의 이미지를 7*7 크기의 Patch 로 768개 필터(output)을 가지도록 하여 Shape가 (1, 768, 7, 7) Tensor로 임베딩하고,
.flatten(2).transpose(1, 2) 를 통해 ViT 모델에 들어갈 수 있도록 shape를 (1, 49, 768)형태로 변환을 시켜줍니다.
그 후 (1, 1, 768) 차원의 class_embedding concat 이후, 이미지 위치 정보인 position_embedding값을 더해서 return 하게 됩니다.
출력 shape는 (1, 50, 768) 이 됩니다.
4-2) pre_layernorm
위의 3-3에서 언급한 Layer Normalization과 동일합니다.
4-3) encoder
encoder 부분의 forward() 메서드 부분입니다.
modeling_clip.py (577 Line)
def forward(
self,
inputs_embeds,
attention_mask: Optional[torch.Tensor] = None,
causal_attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutput]:
r"""
Args:
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Causal mask for the text model. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
hidden_states = inputs_embeds
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
encoder_layer.__call__,
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)3-2의 text_model 의 encoder와 매우 흡사한 구조로 되어 있습니다.
vision_model의 encoder_layer는 아래와 같은 구조이며, text_model과 동일하게 12번 반복하게 되어 있습니다.
(encoder): CLIPEncoder(
(layers): ModuleList(
(0-11): 12 x CLIPEncoderLayer(
(self_attn): CLIPAttention(
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(layer_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): CLIPMLP(
(activation_fn): QuickGELUActivation()
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
)
(layer_norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)text_model 의 encoder와 차이점은 input_feature의 dim (512 vs 768)과 fc(fully-connected) Layer의 hidden layer의 dim (2048 vs 3072) 이 차이가 있네요.
encoder 출력은 (1, 50, 768) 이고, pooler_output = last_hidden_state[:, 0, :]을 통해 class_embedding 부분인 (1, 768) 형태의 값을 이후에 사용하고 있습니다.
자세한 설명은 3-2의 text_model의 encoder로 대체합니다.
4-4) post_layernorm
위의 3-3에서 언급한 Layer Normalization과 동일합니다.
5. Projection
Projection 은 visual_projcection 과 text_projection 으로 구성되어 있고, 이미지와 텍스트를 같은 공간에 사영(projection) 하여 contrastive 하게 비교하기 위함입니다.
5-1) visual_projection
visual_projection 의 입력은 visual_model의 output에서도 class_embedding 부분인 last_hidden_state[:, 0, :] 을 취합니다.
projection 은 FC Layer로 아래와 같이 이루어져 있습니다.
# in_features=768, out_features=512, bias=False)
def forward(self, input: Tensor) -> Tensor:
return F.linear(input, self.weight, self.bias)5-2) text_projection
text_projection 의 입력은 text_model의 output에서 pooled_output 을 취합니다.
pooled_output은 아래 수식으로 되어있고 (1, 512) 형태의 Tensor 입니다.
pooled_output = last_hidden_state[
torch.arange(last_hidden_state.shape[0], device=last_hidden_state.device),
input_ids.to(dtype=torch.int, device=last_hidden_state.device).argmax(dim=-1),
]projection 은 FC Layer로 5-1) visual_projection에서 in_features=512 부분만 다르고 나머지는 동일 합니다.
6. 후처리
후처리는 2 Step으로 진행되며, normalized features 와 cosine similarity 가 수행됩니다. 코드는 아래와 같습니다
modeling_clip.py (1132 Line)
# normalized features
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_text = torch.matmul(text_embeds, image_embeds.t().to(text_embeds.device)) * logit_scale.to(
text_embeds.device
)
logits_per_image = logits_per_text.t()Conclusion
정리를 하면서 부족한 부분들이 많이 있었습니다. 공부할게 또 생겼군요..
openai 에서 만든 CLIP모델을 뜯어보면서 많은 것들을 배우게 되었고, 점점 modal의 경계가 깨지는 것 같습니다.
다음번엔 CLIP을 응용해서 활용하는 것에 대해 블로깅을 해보도록 하겠습니다.
