Stable Diffusion 에 대해 이해하고, 이미지를 생성하는 것을 수행하는 과정을 작성합니다.
0. 이미지 생성의 역사
이미지 생성 AI는 AutoEncoder에서 시작하여, Variational AutoEncoder(VAE)로 발전했습니다. 이후 Generative Adversarial Network(GAN)의 혁신적인 아이디어가 등장하면서 이미지 생성 품질이 크게 향상되었습니다. 그러나 GAN에도 한계가 있었고, 최근에는 Diffusion 모델이 나오면서 이미지 생성의 품질과 성능이 대폭 증가했습니다. Diffusion 모델은 이전의 방법들보다 더 높은 해상도와 세밀한 디테일을 제공하며, 이미지 생성 AI의 새로운 표준이 되고 있습니다.
자연어에서 Transformer 가 엄청난 혁신을 가져왔다면, Vision에서는 Diffusion 이 혁신을 가져왔습니다.
1. Diffusion

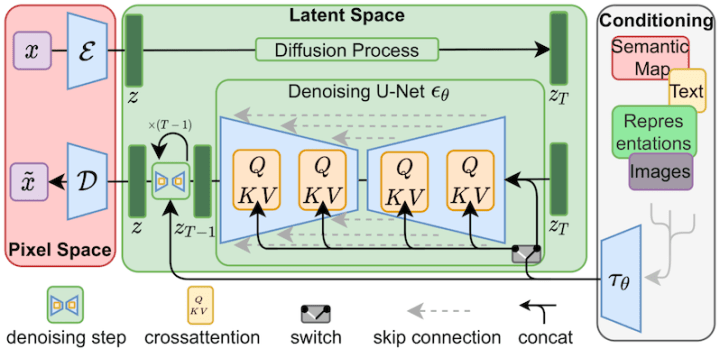
Diffusion 모델은 데이터에 점진적으로 노이즈를 추가한 후, 이를 역전파하여 원래 데이터를 복원하는 과정을 통해 이미지를 생성합니다. 초기 단계에서는 가우시안 노이즈를 점진적으로 추가해 데이터가 노이즈로 변하고, 역방향 과정에서는 이 노이즈를 제거하며 이미지를 생성합니다. 이 모델은 샘플 품질과 다양성 면에서 우수하지만, 생성 속도가 느린 단점이 있습니다. Diffusion 모델은 특히 GAN보다 더 나은 모드 커버리지와 샘플 다양성을 제공합니다.
2. Stable Diffusion
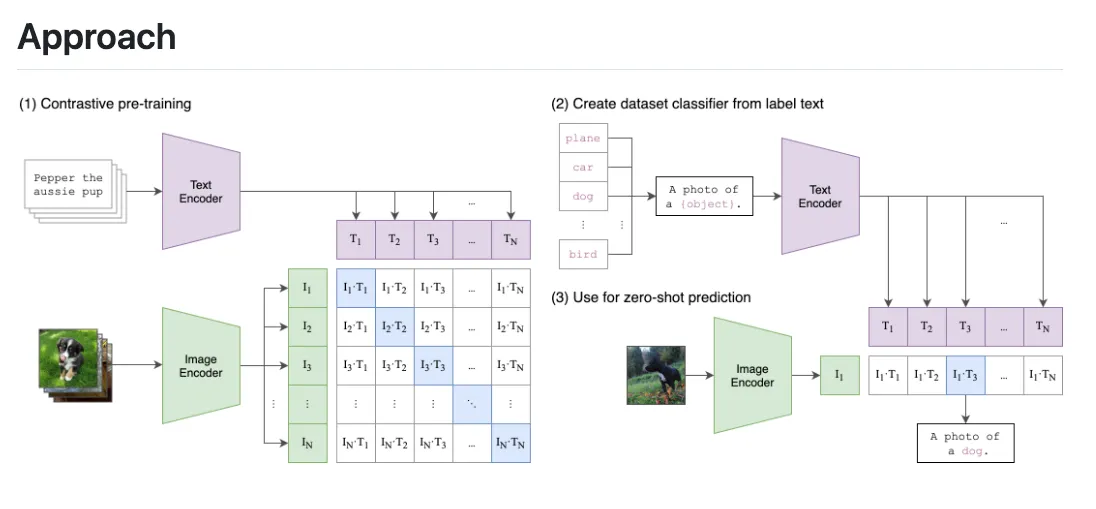
Stable Diffusion은 Diffusion 모델을 기반으로 한 이미지 생성 AI입니다. Diffusion 모델은 노이즈를 점진적으로 제거하면서 고품질 이미지를 생성합니다. CLIP(Contrastive Language-Image Pretraining)은 텍스트와 이미지를 함께 학습하는 모델로, 텍스트 설명에 맞는 이미지를 생성하는 데 중요한 역할을 합니다. Stable Diffusion은 CLIP을 활용해 텍스트-이미지 매칭을 개선하고, 사용자가 원하는 이미지의 정확성을 높입니다. 이를 통해 높은 해상도와 품질의 이미지를 효과적으로 생성할 수 있습니다.
3. A1111 (Stable Diffusion WebUI)
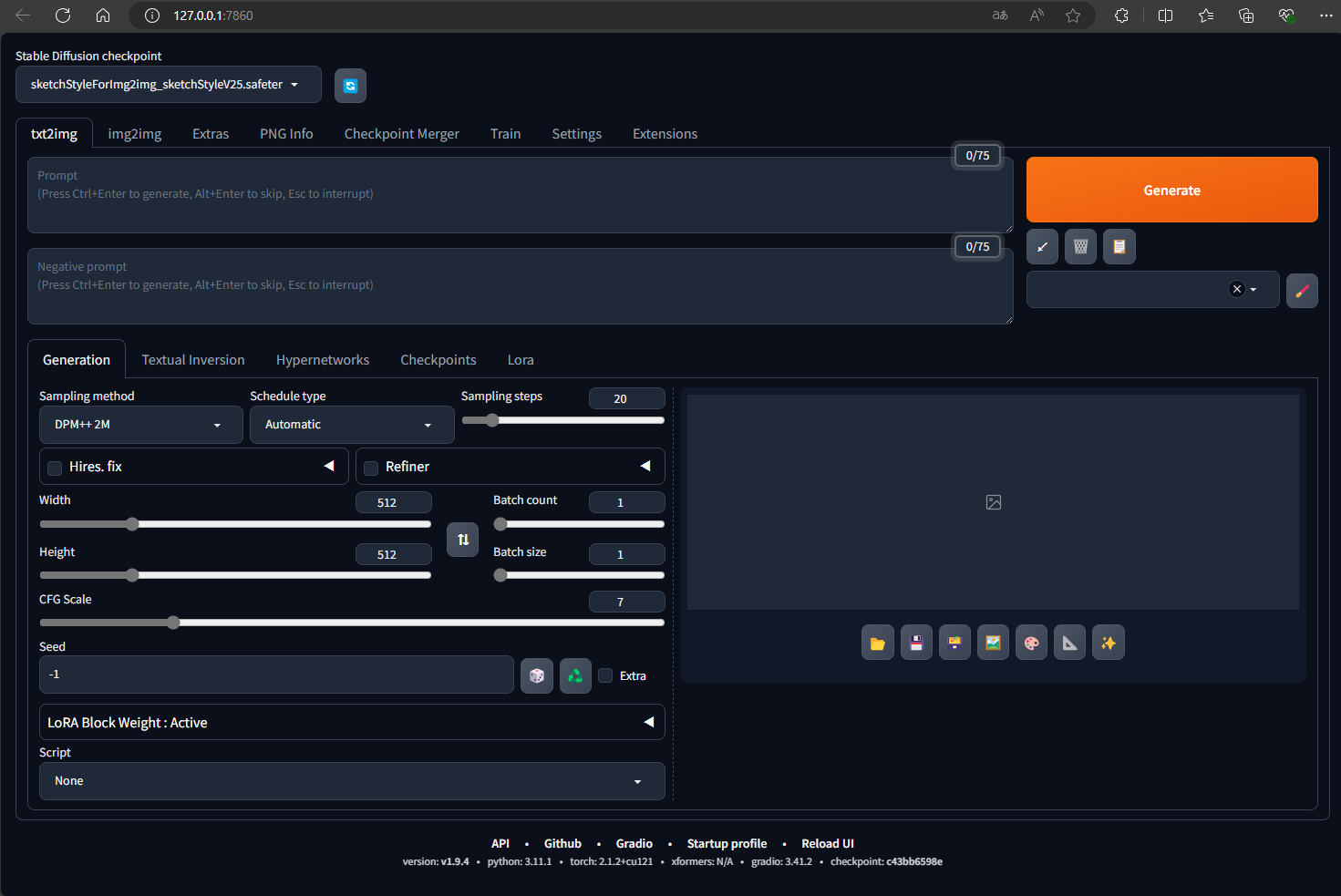
Stable Diffusion WebUI (A1111) 개요 및 설치 방법
Stable Diffusion WebUI (A1111)은 이미지 생성 AI 모델인 Stable Diffusion을 웹 인터페이스로 쉽게 사용할 수 있게 해주는 오픈 소스 프로젝트입니다. 이 UI는 사용자 친화적인 인터페이스를 제공하여, 텍스트 입력으로 이미지를 생성하거나 다양한 이미지 생성 옵션을 조정할 수 있습니다.
Stable Diffusion WebUI (A1111)의 주요 메뉴와 기능은 다음과 같습니다:
-
txt2img:
- 텍스트 프롬프트를 입력하여 이미지를 생성합니다. 다양한 파라미터를 조정해 생성되는 이미지의 스타일과 품질을 제어할 수 있습니다.
-
img2img:
- 기존 이미지를 입력하여 이를 바탕으로 변형된 이미지를 생성합니다. 원본 이미지의 노이즈 제거나 스타일 변환 등에 사용됩니다.
-
Extras:
- 이미지 업스케일링, 필터 적용 등 추가 기능을 제공합니다.
-
PNG Info:
- PNG 파일의 메타데이터를 확인하고 편집할 수 있습니다. 이미지 생성에 사용된 프롬프트와 설정 정보를 보여줍니다.
-
Checkpoint Merger:
- 여러 모델 체크포인트를 병합하여 새로운 모델을 생성할 수 있습니다.
-
Settings:
- 웹 UI의 다양한 설정을 조정할 수 있는 메뉴입니다. 사용자 환경에 맞게 최적화할 수 있습니다.
설치 방법
- 필수 요건: Python 3.8+, Git, GPU (CUDA 지원)
- GitHub 리포지토리 클론:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git - 디렉토리 이동 및 의존성 설치:
cd stable-diffusion-webui pip install -r requirements.txt - 모델 다운로드: Stable Diffusion 모델 파일(.ckpt)을 다운로드하여
models/Stable-diffusion폴더에 저장 - 웹 UI 실행:
webui-user.bat - 웹 브라우저에서 접근:
http://127.0.0.1:7860접속
이 단계를 따라하면 로컬 환경에서 Stable Diffusion WebUI를 사용할 수 있습니다.
4. Prompt
Stable Diffusion WebUI (A1111)에서는 다양한 프롬프트 기술을 활용해 이미지를 세밀하게 제어할 수 있습니다. 아래는 주요 프롬프트 기술과 예시입니다:
-
단어에 가중치 부여:
- 형식:
((word))또는(word:1.2) - 예시:
((sunset)),(sunset:1.2)
- 형식:
-
LoRA 가중치 적용:
- 형식:
<lora:weight:0.3> - 예시:
<lora:artstyle:0.3>
- 형식:
-
네거티브 프롬프트: 특정 요소를 배제하고 싶을 때 사용합니다.
- 형식:
negative_prompt: {word} - 예시:
negative_prompt: blurry
- 형식:
-
스타일 강조: 스타일의 강도를 조절합니다.
- 형식:
[style:weight] - 예시:
[watercolor:0.8]
- 형식:
-
콤마로 구분된 멀티 프롬프트: 여러 프롬프트를 조합합니다.
- 형식:
word1, word2 - 예시:
sunset, beach, waves
- 형식:
-
컬러 강조:
- 형식:
{color} - 예시:
{blue},{red}
- 형식:
예시 프롬프트
- 복합 사용 예시:
"((sunset)), beach, <lora:artstyle:0.3>, negative_prompt: blurry, [watercolor:0.8]"
이와 같은 프롬프트 기술을 조합하여 다양한 이미지 생성 요구를 충족시킬 수 있습니다.
5. LoRA
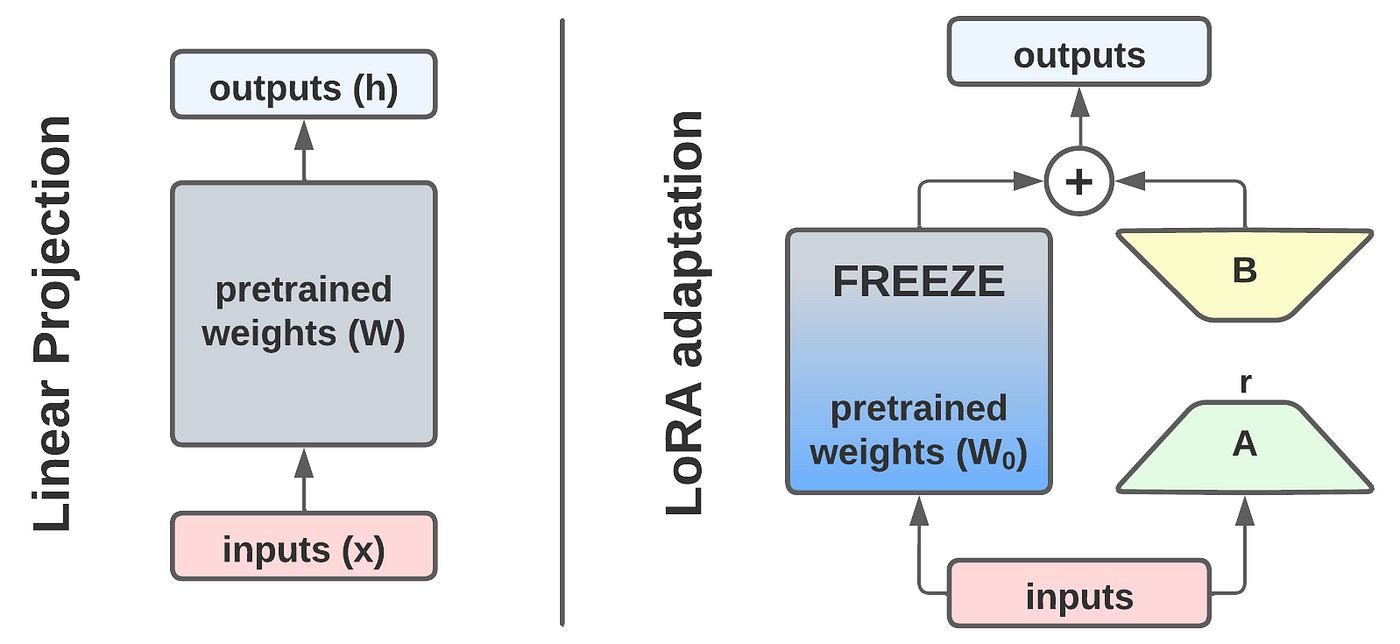
LoRA(Low-Rank Adaptation)는 대규모 모델을 최소한의 계산 자원으로 미세 조정하는 기술입니다. 사전 훈련된 모델의 특정 레이어를 수정하여 전체 모델을 처음부터 다시 훈련할 필요 없이 효율적인 적응을 가능하게 합니다. 이 방법은 모델을 특정 스타일이나 작업에 적응시키는 데 특히 유용합니다.
(crossattention Layer의 기존 weights에 LoRA Weghits를 합산하여 동작합니다.)
LoRA의 장점:
1. 효율성: 적은 수의 파라미터에 집중하여 전통적인 미세 조정에 비해 계산 부담과 메모리 사용량을 크게 줄입니다.
2. 유연성: 다양한 모델과 스타일에 적용할 수 있어 매우 다양한 응용이 가능합니다.
3. 성능: 계산 요구 사항이 줄어듦에도 불구하고, LoRA는 생성된 이미지의 높은 성능과 품질을 유지합니다.
Stable Diffusion에서의 LoRA 사용법:
Stable Diffusion에서는 LoRA를 적용하여 출력 스타일을 향상시키거나 수정할 수 있습니다. 모델의 일부 파라미터만 조정하여 새로운 시각적 스타일이나 효과를 통합할 수 있습니다. 이는 AI로 생성된 이미지를 개인화하거나 다양화하려는 예술가와 개발자에게 강력한 도구가 됩니다.
응용 예시:
- 예술적 스타일 변환: 생성된 이미지에 특정 예술적 스타일을 적용
- 특수 효과: 색상 강화나 텍스처 오버레이 같은 독특한 시각 효과 추가
- 맞춤형 캐릭터 생성: 게임이나 애니메이션을 위한 일관된 캐릭터 디자인 생성
LoRA 시작하기:
LoRA를 사용하려면 일반적으로 다음 단계를 따릅니다:
1. 사전 훈련된 모델 선택: 적응시키고자 하는 기본 모델을 선택합니다. (Checkpoint 모델)
2. 대상 레이어 식별: 수정할 모델의 레이어를 결정합니다.
3. LoRA로 훈련: 작은 데이터셋을 사용해 원하는 스타일이나 효과로 선택한 레이어를 훈련합니다.
4. 통합 및 생성: 적응된 모델을 사용하여 새로운 스타일이나 효과가 반영된 이미지를 생성합니다.
6. CIVITAI
CivitAI는 이미지 생성 모델과 관련된 커뮤니티 중심의 플랫폼으로, 다양한 특징과 장점을 제공합니다. 아래에 CivitAI의 주요 특징과 장점을 정리하여 블로그 작성에 도움이 되도록 하겠습니다.
CivitAI의 특징
-
모델 공유와 평가:
- CivitAI는 사용자가 자신이 개발한 이미지 생성 모델을 업로드하고 공유할 수 있는 플랫폼입니다. 커뮤니티의 다른 사용자들이 모델을 다운로드하고 테스트한 후, 평가와 피드백을 제공할 수 있습니다. 이를 통해 모델 개발자들은 자신의 모델을 개선할 수 있는 귀중한 인사이트를 얻을 수 있습니다.
-
다양한 모델 카탈로그:
- 플랫폼에는 다양한 종류의 이미지 생성 모델이 카탈로그 형태로 정리되어 있습니다. 사용자들은 특정 스타일, 주제, 또는 응용 분야에 맞는 모델을 쉽게 찾을 수 있습니다. 검색 기능과 태그 시스템을 통해 원하는 모델을 빠르게 찾을 수 있습니다.
-
사용자 친화적 인터페이스:
- CivitAI는 직관적이고 사용하기 쉬운 인터페이스를 제공하여, 초보자부터 전문가까지 누구나 쉽게 접근할 수 있습니다. 모델 업로드, 다운로드, 평가 등의 모든 과정이 간편하게 이루어질 수 있도록 설계되었습니다.
CivitAI의 장점
-
커뮤니티 중심의 발전:
- CivitAI는 사용자들 간의 활발한 상호작용을 촉진합니다. 모델 개발자들은 커뮤니티의 피드백을 통해 모델을 지속적으로 개선할 수 있으며, 사용자들은 최신 기술과 트렌드를 빠르게 접할 수 있습니다. 이로 인해 플랫폼 전체가 지속적으로 성장하고 발전할 수 있습니다.
-
오픈 소스와 협업:
- 많은 모델들이 오픈 소스로 제공되어 누구나 자유롭게 수정하고 개선할 수 있습니다. 이는 협업과 공동 발전을 장려하며, 더 나은 품질의 모델이 지속적으로 탄생할 수 있도록 합니다.
-
지식 공유와 학습 기회:
- 플랫폼에는 모델 개발과 관련된 다양한 튜토리얼, 가이드, 그리고 사례 연구가 제공됩니다. 이를 통해 사용자들은 새로운 기술을 배우고 자신의 스킬을 향상시킬 수 있는 기회를 얻게 됩니다.
-
다양한 응용 분야:
- CivitAI에는 예술, 디자인, 광고, 게임 개발 등 다양한 응용 분야에 활용될 수 있는 모델들이 포함되어 있습니다. 사용자들은 자신이 속한 분야에 맞는 모델을 쉽게 찾고 활용할 수 있습니다.
7. 이미지 생성
- 기본 이미지 생성
- 모델 : chilloutmix_v10
- prompt
best quality, ultra high res, (photorealistic:1.4) , oversized jacket, white shirt, 1girl, 20 years old, cute, (ponytail:1.2)- negative prompt
paintings, sketches, (worst quality:2) , (low quality:2) , (normal quality:2) , lowres, normal quality, ((monochrome) ), ((grayscale) ), skin spots, acnes, skin blemishes, age spot, glans, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worstquality, low quality, normal quality, jpegartifacts, signature, watermark, username, blurry, bad feet, cropped, poorly drawn hands, poorly drawn face, mutation, deformed, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, extra fingers, fewer digits, extra limbs, extra arms, extra legs, malformed limbs, fused fingers, too many fingers, long neck, cross-eyed, mutated hands, polar lowres, bad body, bad proportions, gross proportions, text, error, missing fingers, missing arms, missing legs, extra digit- sampling method : DPM++ SDE Karras
- sampling steps : 30
- CFG Scale : 7
- seed : 2141532

- LORA 적용
- prompt 가장 뒤에 lora 추가
best quality, ultra high res, (photorealistic:1.4) , oversized jacket, white shirt, 1girl, 20 years old, cute, (ponytail:1.2), <lora:koreanDollLikeness_v20:0.8>, <lora:taiwanDollLikeness_v20:0.3>
