
스트림이란?
List컬렉션에서 요소를 하나씩 처리하는 for문
List<String> list = ...;
for(int i=0; i<list.size(); i++) {
String item = list.get(i);
//item 처리
}Set에서 요소를 하나씩 처리하기 위해 Iterator 사용
Set<String> set = ...;
Iterator<String> iterator = set.iterator();
while(iterator.hasNext()) {
String item = iterator.next();
//요소 처리
}Java 8부터는 또 다른 방법으로 컬렉션 및 배열의 요소를 반복 처리하기 위해 스트림을 사용하면 다음과 같다.
Stream<String> stream = list.stream();
stream.forEach( item -> //item 처리);List 컬렉션의 Stream() 메소드로 Stream 객체를 얻고, forEach() 메소드로 요소를 어떠게 처리할지를 람다식으로 제공한다.
Stream은 Iterator와 비슷하지만 아래와 같은 차이점을 가지고 있다.
- 내부 반복자이므로 처리 속도가 빠르고 병렬 처리에 효율적이다.
- 람다식으로 다양한 요소 퍼리를 정의할 수 있다.
- 중간 처리와 최종 처리를 수행하도록 파이프 라인을 형성할 수 있다.
내부 반복자
for문과 Iterator
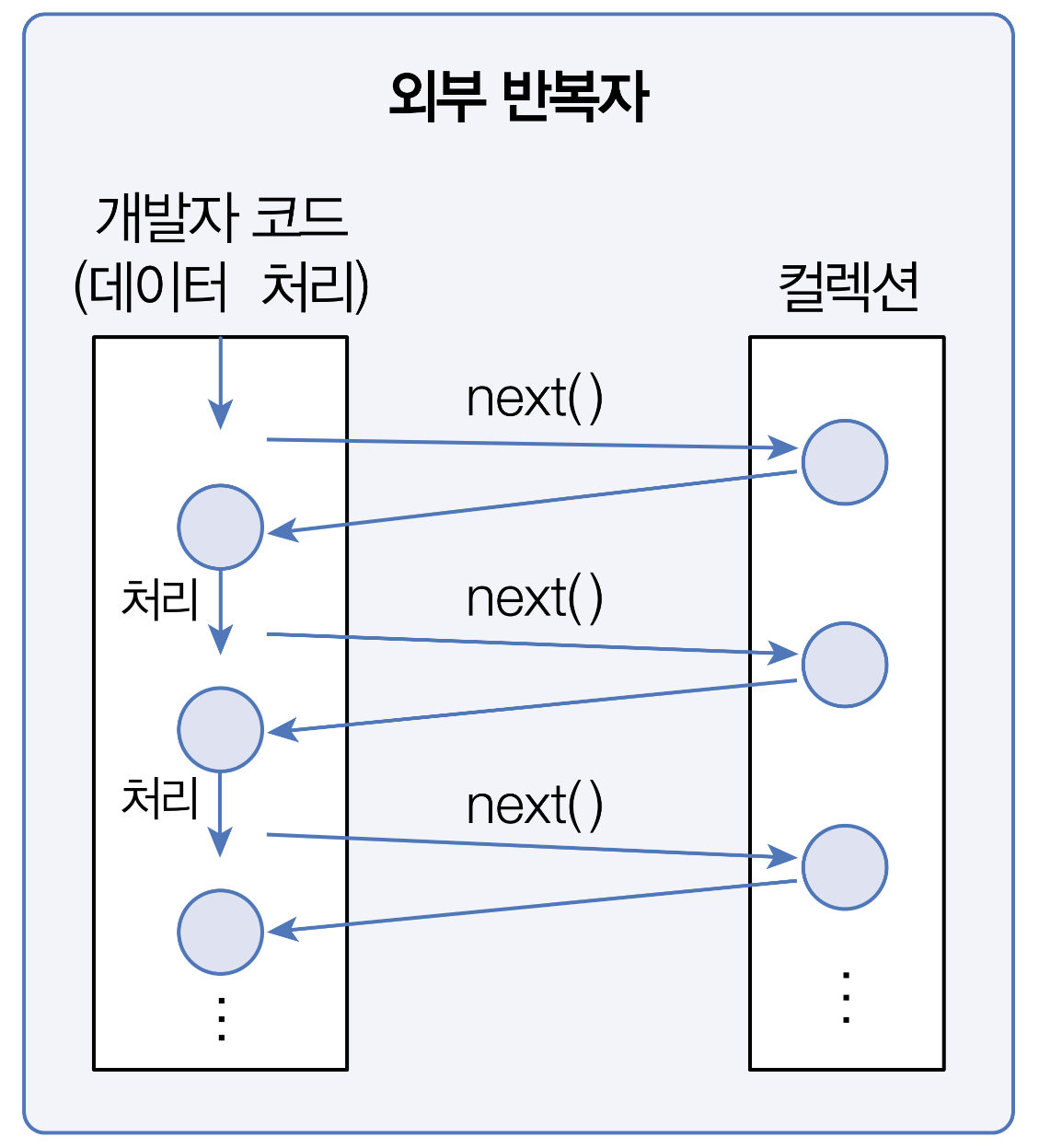
컬렉션의 요소를 컬렉션 바깥쪽으로 반복해서 가져와 처리하는데, 이것을 외부 반복자라고 한다.
Stream
요소 처리 방법을 컬렉션 내부로 주입시켜서 요소를 반복 처리하는데, 이것을 내부 반복자라고 한다.
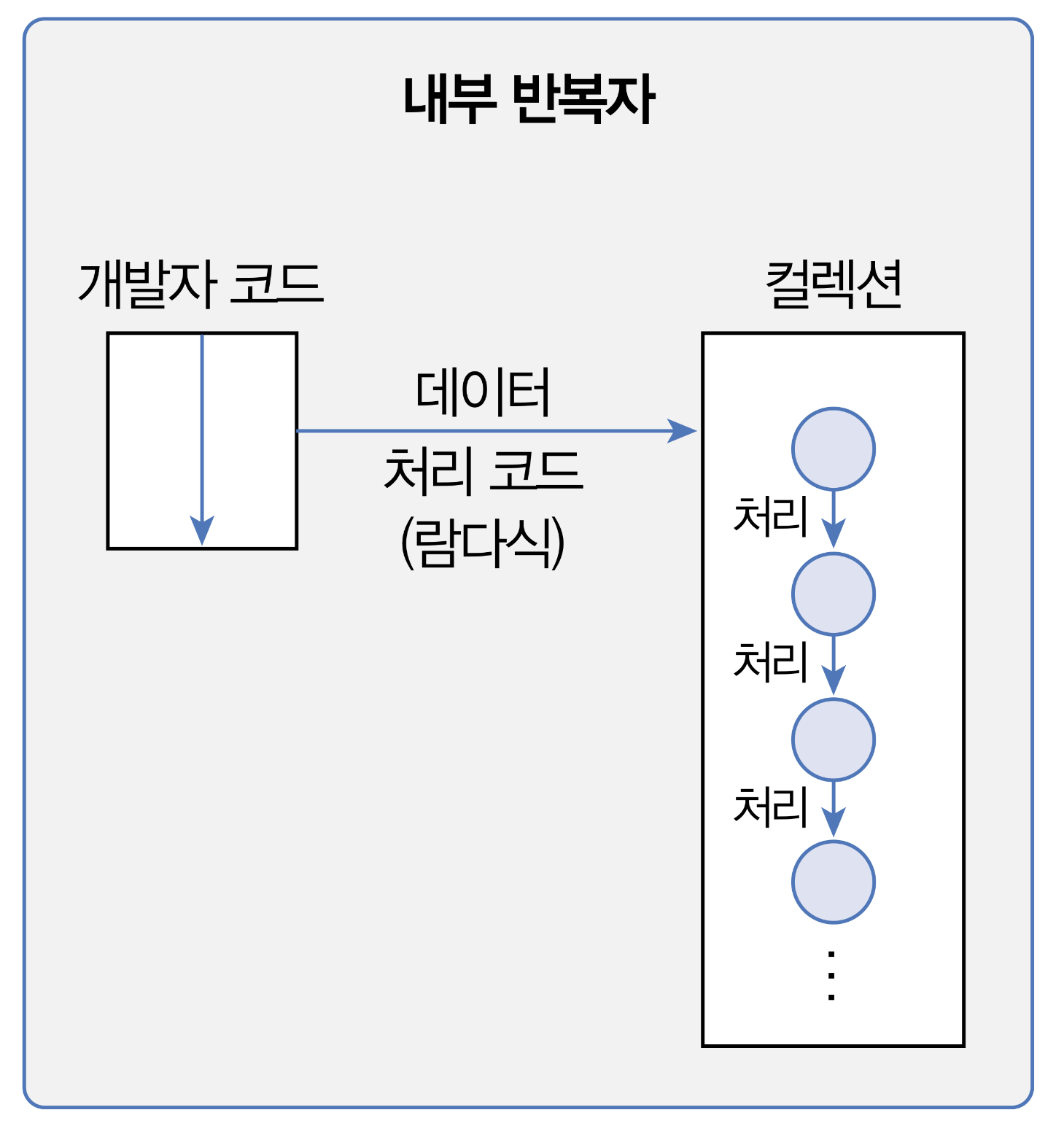
외부 반복자일 경우는 컬렉션의 요소를 외부로 가져오는 코드와 처리하는 코드를 모두 개발자 코드가 가지고 있어야 한다. 반면 내부 반복자일 경우에는 개발자 코드에서 제공한 데이터 처리 코드(람다식)를 가지고 컬렉션 내부에서 요소를 반복 처리한다.
중간 처리와 최종처리
스트림은 하나 이상 연결될 수 있다. 아래 그림을 보면 컬렉션의 오리지널 스트림 뒤에 필터링 중간 스트림이 연결될 수 있고, 그 뒤에 매핑 중간 스트림이 연결될 수 있다. 이것을 스트림 파이프라고 한다.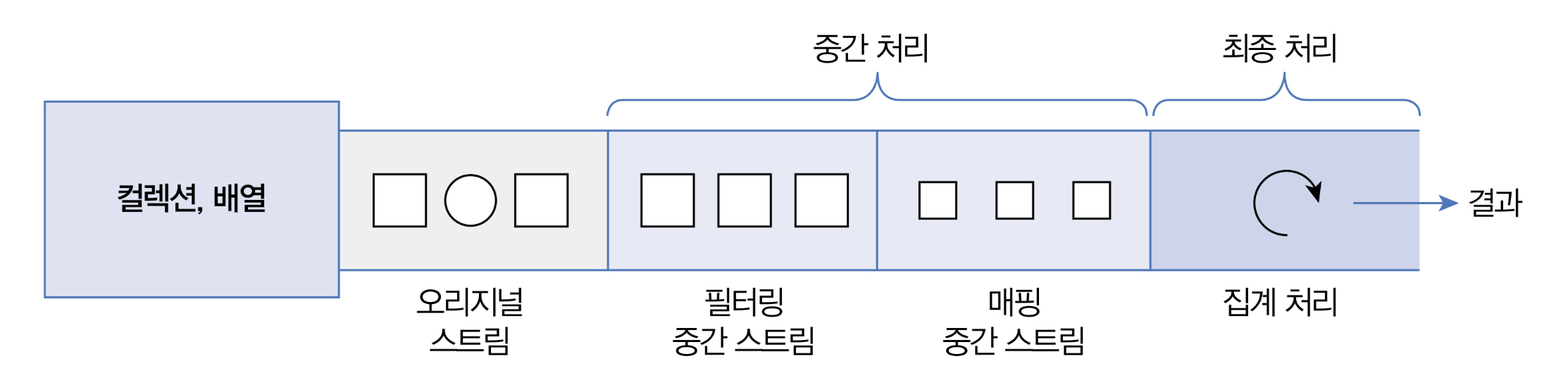
오리지널 스트림과 집계 처리 사이의 중간 스트림들은 최종 처리를 위해 요소를 걸러내거나(필터링), 요소를 변환시키거나(매핑), 정렬하는 작업을 수행한다. 최종 처리는 중간 처리에서 정제된 요소들을 반복하거나, 집계(카운팅, 총합, 평균) 작업을 수행한다.
아래 그림은 Student 객체를 요소로 가지는 컬렉션에서 Student 스트림을 얻고, 중간 처리를 통해 score 스트림으로 변환한 후 최종 집계 처리로 score 평균을 구하는 과정을 나타낸 것이다.
//Student 클래스 Stream<Student> studentStream = list.stream(); //Score 스트림 IntStream scoreStream = studentStream.mapToInt ( student -> student.getScore() ); //평균 계산 double avg = scroeStream.average().getAsDouble();//메소드 체이닝 패턴 사용 double avg = list.stram() .mapToInt(student -> student.getScore()) .average() .getAsDouble();
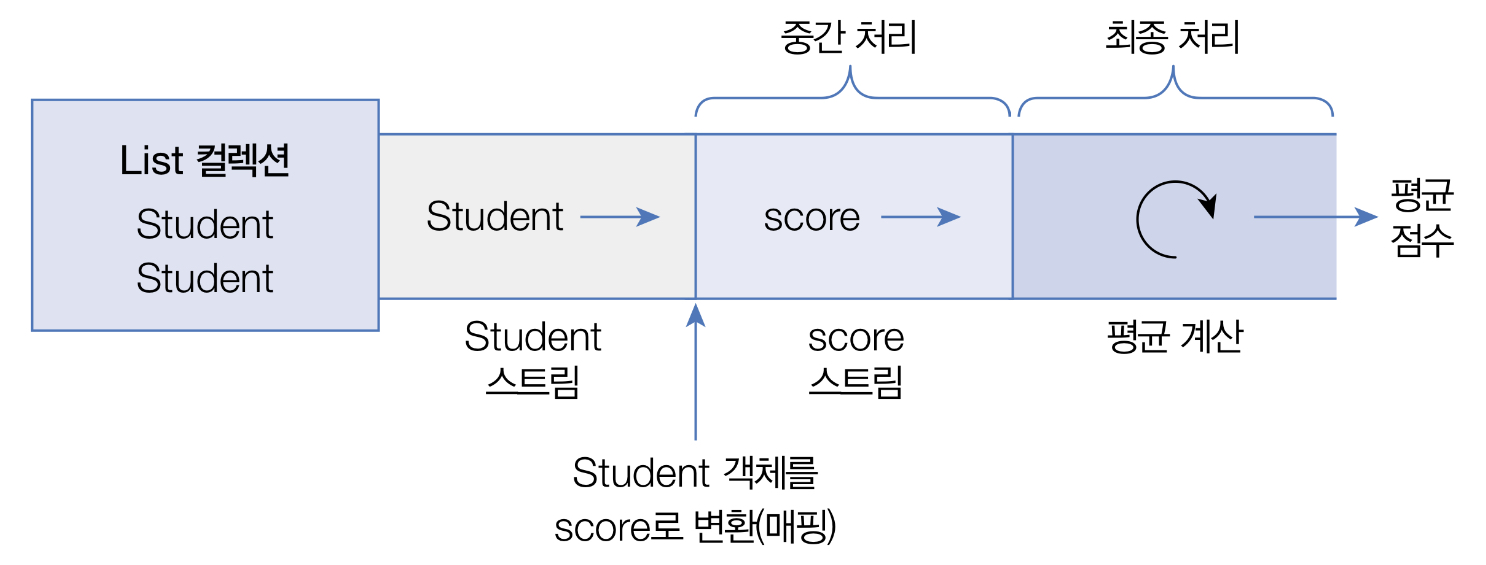
스트림 파이프라인으로 구성할 때 주의할 점은 파이프라인의 맨 끝에는 반드시 최종 처리 부분이 있어야한다. 최종 처리가 없다면 오리지널 및 중간 처리 스트림은 동작하지 않는다.
리소스로부터 스트림 얻기
java.util.stream 패키지에는 스트림 인터페이스들이 있다. BaseStream 인터페이스를 부모로 한 자식 인터페이스들은 아래와 같은 상속 관계를 이루고 있다.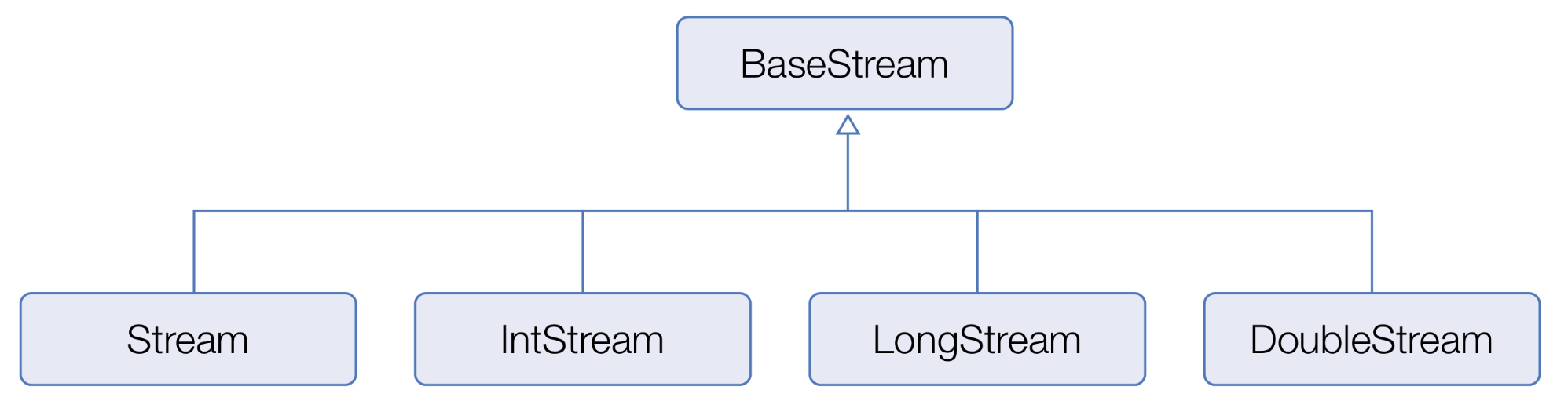
BaseStream에는 모든 스트림에서 사용할 수 있는 공통 메소드들이 정의되어 있다. Stream은 객체 요소를 처리하는 스트림이고 ,IntStream, DoubleStream, LongStream은 각각 기본 타입인 int, double, long 요소를 처리하는 스트림이다.
이 스트림 인터페이스들의 구현 객체는 다양한 리소스로부터 얻을 수 있다.
스트림 얻는 방법은 컬렉션으로 스트림 얻기, 배열로부터 스트림 얻기, 숫자 범위로부터 스트림 얻기, 파일로부터 스트림 얻기 방식이 있다.
요소 걸러내기 (필터링)
필터링은 요소를 걸러내는 중간 처리 기능이다. 필터링 메소드에는 다음과 같이 distinct()와 filter()가 있다.
import java.util.ArrayList;
import java.util.List;
public class FilteringExample {
public static void main(String[] args) {
//List 컬렉션 생성
List<String> list = new ArrayList<>();
list.add("홍길동"); list.add("신용권");
list.add("김자바"); list.add("신용권"); list.add("신민철");
//중복 요소 제거
list.stream()
.distinct()
.forEach(n -> System.out.println(n));
System.out.println();
//신으로 시작하는 요소만 필터링
list.stream()
.filter(n -> n.startsWith("신"))
.forEach(n -> System.out.println(n));
System.out.println();
//중복 요소를 먼저 제거하고, 신으로 시작하는 요소만 필터링
list.stream()
.distinct()
.filter(n -> n.startsWith("신"))
.forEach(n -> System.out.println(n));
}
}홍길동
신용권
김자바
신민철
신용권
신용권
신민철
신용권
신민철요소 변환(매핑)
매핑은 스트림의 요소를 다른 요소로 변환하는 중간 처리 기능이다. 매핑 메소드는 mapXxx(), asDoubleStream(), asLongStream(), boxed(), flatMapXxx()
요소를 다른 요소로 변환
mapXx() 메소드는 요소를 다른 요소로 변환한 새로운 스트림을 리턴한다. 아래 그림처럼 원래 스트림의 A 요소는 C 요소로 , B 요소는 D 요소로 변환해서, C, D 요소를 가지는 새로운 스트림이 생성된다.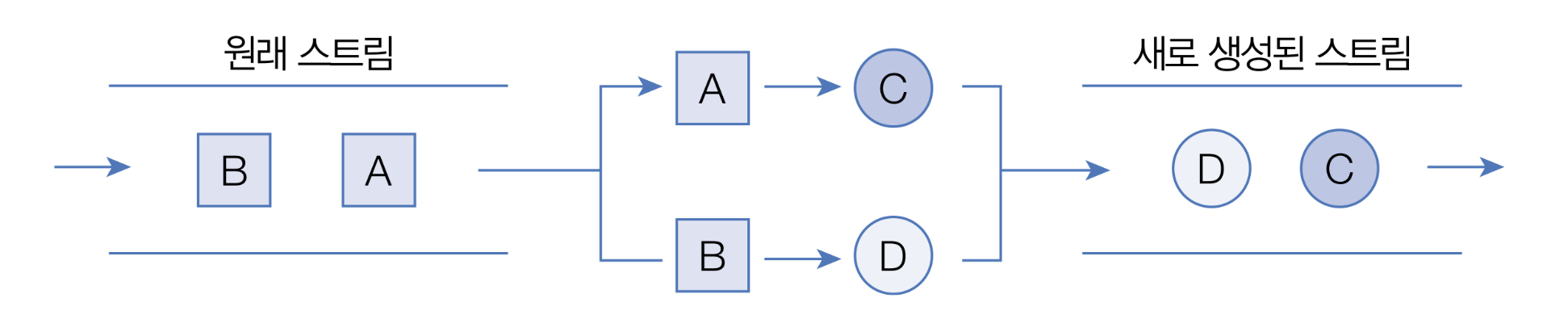
요소를 복수 개의 요소로 변환
flatMapXxx() 메소드는 하나의 요소를 복수 개의 요소들로 변환한 새로운 스트림을 리턴한다. 아래 그림처럼 원래 스트림의 A 요소를 A1, A2요소로 변환하고 B 요소를 B1, B2로 변환하면 A1, A2, B1, B2 요소를 가지는 새로운 스트림이 생성된다.

요소 정렬
정렬은 요소를 오름차순 또는 내림차순으로 정렬하는 중간 처리 기능이다.
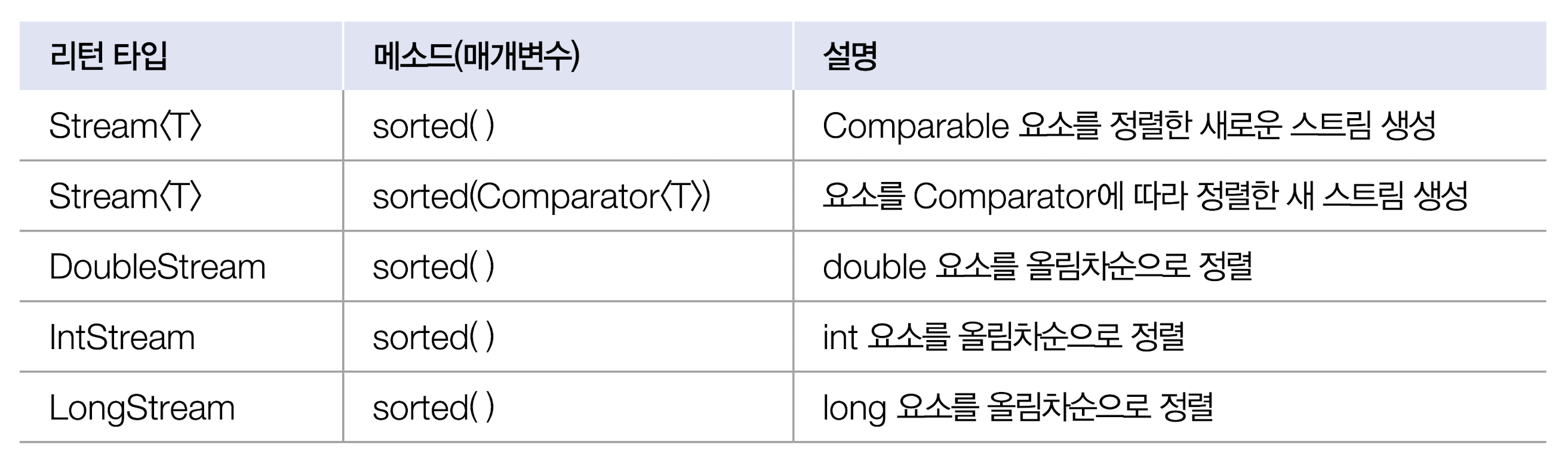
(표를 만드는 것보다 사진으로 올리는게 더 잘 읽히는 듯...)
Comparable 구현 객체의 정렬
스트림의 요소가 객체일 경우 객체가 Comparable을 구현하고 있어야만 sorted() 메소드를 사용하여 정렬할 수 있다. 그렇지 않다면 ClassCastException이 발생한다.
Comparator를 이용한 정렬
요소 객체가 Comparable을 구현하고 있지 않다면, 비교자를 제공하면 요소를 정렬시킬 수 있다. 비교자는 Comparator 인터페이스를 구현할 객체를 말하는데. 아래와 같이 간단하게 람다식으로도 작성할 수 있다.
sorted((o1,o2) -> { ... })요소를 하나씩 처리(루핑)
루핑은 스트림에서 요소를 하나씩 반복해서 가져와 처리하는 것을 말한다. 루핑 메소드에는 peek()과 forEach()가 있다.
peek()과 forEach()는 동일하게 요소를 루핑하지만 peek()은 중간 처리 메소드이고, forEach()는 최종 처리 메소드이다. 따라서 peek()은 최종 처리가 뒤에 붙지 않으면 동작하지 않는다.
매개타입인 Consumer는 함수형 인터페이스.
모든 Consumer는 매개값을 처리하는 accept() 메소드를 가지고 있다.
//Consumer<? super T>를 람다식으로 표현
T -> { ... }
or
T -> 실행문; //하나의 실행문만 있을 경우 중괄호 생략import java.util.Arrays;
public class LoopingExample {
public static void main(String[] args) {
int[] intArr = { 1, 2, 3, 4, 5 };
//잘못 작성한 경우
Arrays.stream(intArr)
.filter(a -> (a%2) ==0)
.peek(n -> System.out.println(n)); //최종 처리가 없으므로 동작하지 않음
//중간 처리 메소드 peek()을 이용해서 반복 처리
int total = Arrays.stream(intArr)
.filter(a -> (a%2)==0)
.peek(n -> System.out.println(n))
.sum();//최종처리
System.out.println("총합 : " + total + "\n");
//최종 처리 메소드 forEach()를 이용해서 반복 처리
Arrays.stream(intArr)
.filter(a -> (a%2)==0)
.forEach(n -> System.out.println(n));
}
}2
4
총합 : 6
2
4요소 조건 만족 여부(매칭)
매칭은 요소들이 특정 조건에 만족하는지 여부를 조사하는 최종 처리 기능이다.
모두 만족하는지 여부는 all 하나라도 만족하는지는 any, 모두 만족하지 않는 여부는 none을 접두사로 붙인다 ex) allMatch()
요소 기본 집계
집계는 최종 처리 기능으로 요소들을 처리해서 카운팅, 합계, 평균값, 최댓값, 최솟값등과 같이 하나의 값으로 산출하는 것을 말한다. 즉 대량의 데이터를 가공해서 하나의 값으로 축소하는 리덕션이라고 볼 수 있다.
스트림이 제공하는 기본 집계

집계 메소드가 리턴하는 OptionalXXX는 Optional, OptionalDouble, OptionalInt, OptionalLong 클래스를 말한다. 이들은 최종값을 저장하는 객체로 get(), getAsDouble(), getAsInt(), getAsLong()을 호출하면 최종값을 얻을 수 있다.
Optional 클래스
OptionalXXX 클래스는 단순히 집계값만 저장하는 것이 아니라, 집계값이 존재하지 않을 경우 디폴트 값을 설정하거나 집계값을 처리하는 Consumer를 등록할 수 있다.
컬렉션의 요소는 동적으로 추가되는 경우가 많다. 만약 컬렉션에 요소가 존재하지 않으면 집계 값을 산출할 수없으므로 NoSuchElementException 예외가 발생한다. 하지만 위의 표에 언급되어 있는 메소드를 사용하면 예외 발생을 막을 수 있다.
1) isPresent() 메소드가 true를 리턴할 때만 집계값만 얻는다.
OptionalDouble optional = stream
.average();
if(optional.isPresent()) {
System.out.println("평균: " + optional.getAsDouble());
} else {
System.out.println("평균 : 0.0");
}2) orElse() 메소드로 집계값이 없을 경우를 대비해서 디폴트 값을 정해놓는다.
double avg = stream
.average();
.orElse();
System.out.println("평균 : " + avg);3) ifPresent() 메소드로 집계값이 있을 경우에만 작동하는 Consumer 람다식을 제공한다.
stream
.average()
.ifPresent(a -> System.out.println("평균 : " + a)); 요소 커스텀 집계
스트림은 기본 집계 메소드인 sum(), average(), max(), min()을 제공하지만, 다양한 집계 결과물을 만들 수 있도록 reduce() 메소드도 제공한다.
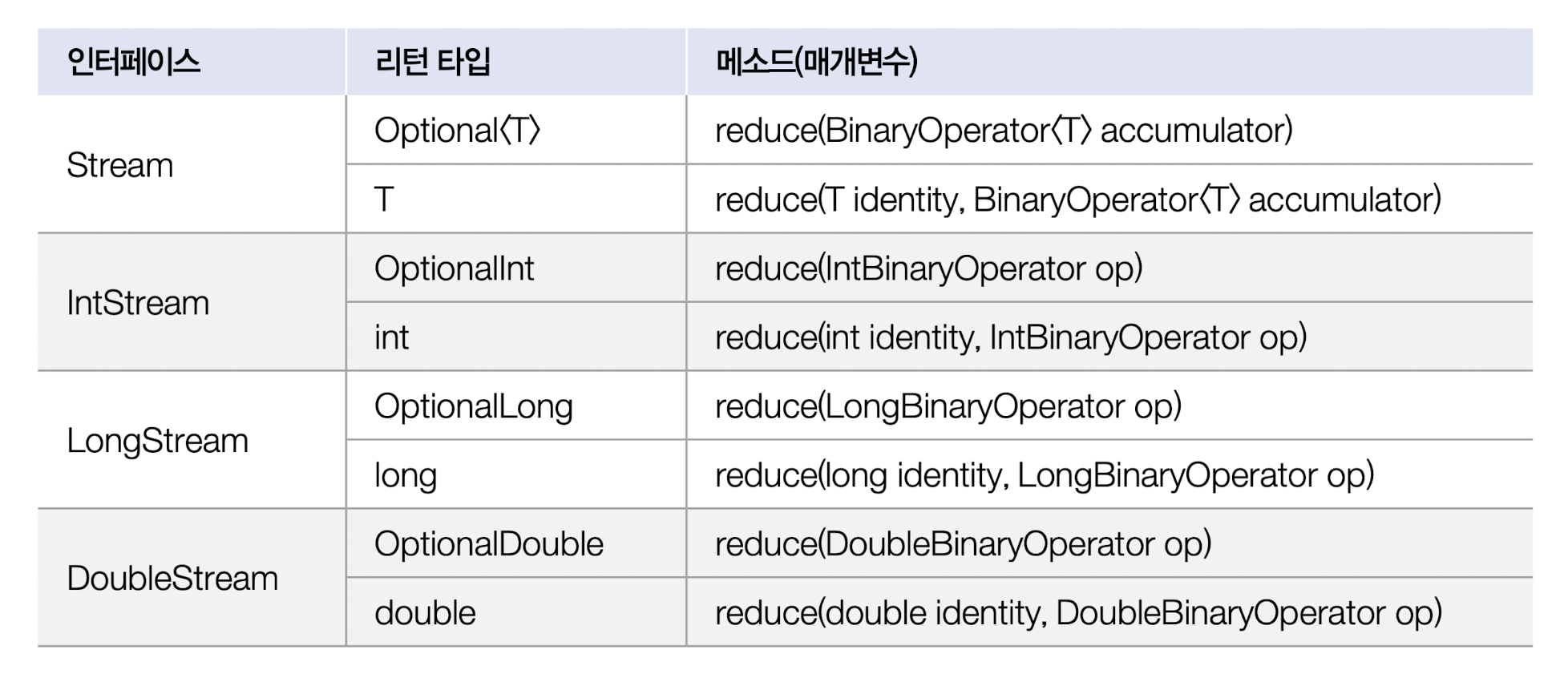
매개값인 BinaryOperator는 함수형 인터페이스이다. BinaryOperator는 두 개의 매개값을 받아 하나의 값을 리턴하는 apply() 메소드를 가지고 있고 아래와 같이 람다식을 작성할 수 있다.
(a, b) -> { ... return 값; }
or
(a, b) -> 값 //return 문만 있을 경우 중괄호와 return 키워드 생략 가능reduce()는 스트림에 요소가 없을 경우 예외가 발생하지만, identity 매개값이 주어지면 이 값을 디폴트 값으로 리턴한다.
int sum = stream
.reduce((a, b) -> a+b)
.getAsInt();
//요소가 없다면 NoSuchElementException 발생 int sum = stream
.reduce(0, (a, b) -> a+b);
//default 값으로 0을 리턴요소 수집
스트림은 요소들을 필터링 또는 매핑한 후 요소들을 수집하는 최종 처리 메소드인 collect()를 제공한다. 이 메소드를 이용하면 필요한 요소만 컬렉션에 담을 수 있고, 요소들을 그룹핑한 후에 집계할 수도 있다.
필터링한 요소 수집, 요소 그룹핑이 있다.
요소 병렬 처리
요소 병렬 처리란 멀티 코어 CPU 환경에서 전체 요소를 분할해서 각각의 코어가 병렬적으로 처리하는 것을 말한다. 요소 병렬 처리의 목적은 작업 처리 시간을 줄이기에 있다. 자바는 요소 병렬 처리를 위해 병렬 스트림을 제공한다.
동시성과 병렬성
멀티 스레드는 동시성 또는 병렬성으로 실행되기 때문에 이들 용어에 대해 정확히 이해하는 것이 좋다. 동시성은 멀티 작업을 위해 멀티 스레드가 하나의 코어에서 번갈아 가며 실행하는 것을 말하고, 병렬성은 멀티 작업을 위해 멀티 코어를 각각 이용해서 병렬로 실행하는 것을 말한다.
동시성은 한 시점에 하나의 작업만 실행한다. 번갈아 작업을 실행하는 것이 워낙 빠르다보니 동시에 처리되는 것처럼 보일 뿐이다. 병렬성은 데이터 병렬성과 작업 병렬성으로 구현한 것이다.
데이터 병렬성
데이터 병렬성은 전체 데이터를 분할해서 서브 데이터셋으로 만들고 이 서브 데이터세들을 병렬처리해서 작업을 빨리 끝내는 것을 말하며 자바 병렬 스트림은 데이터 병렬성을 구현한 것이다.
작업 병렬성
작업 병렬성은 서로 다른 작업을 병렬처리하는 것을 말한다. 작업 병렬성의 대표적인 예는 서버 프로그램이다. 서버는 각각의 클라이언트에서 요청한 내용을 개별 스레드에서 병렬로 처리한다.
포크조인 프레임워크
자바 병렬 스트림은 요소들을 병렬 처리하기 위해 포크조인 프레임워크를 사용한다. 포크조인 프레임워크는 포크 단계에서 전체 요소들을 서브 요소셋으로 분할하고, 각각의 서브 요소셋을 멀티 코어에서 병렬로 처리한다. 조인 단계에서는 서브 결과를 결합해서 최종 결과를 만들어낸다.
예를 들어 쿼드 코어 CPU에서 병렬 스트림으로 요소들을 처리할 경우 먼저 포크 단계에서 스트림의 전체 요소들을 4개의 서브 요소셋으로 분할한다. 그리고 각가의 서브 요소셋을 개별 코어에서 처리하고, 조인단계에서는 3번의 결홥 과정을 거쳐 최종결과를 산출한다.
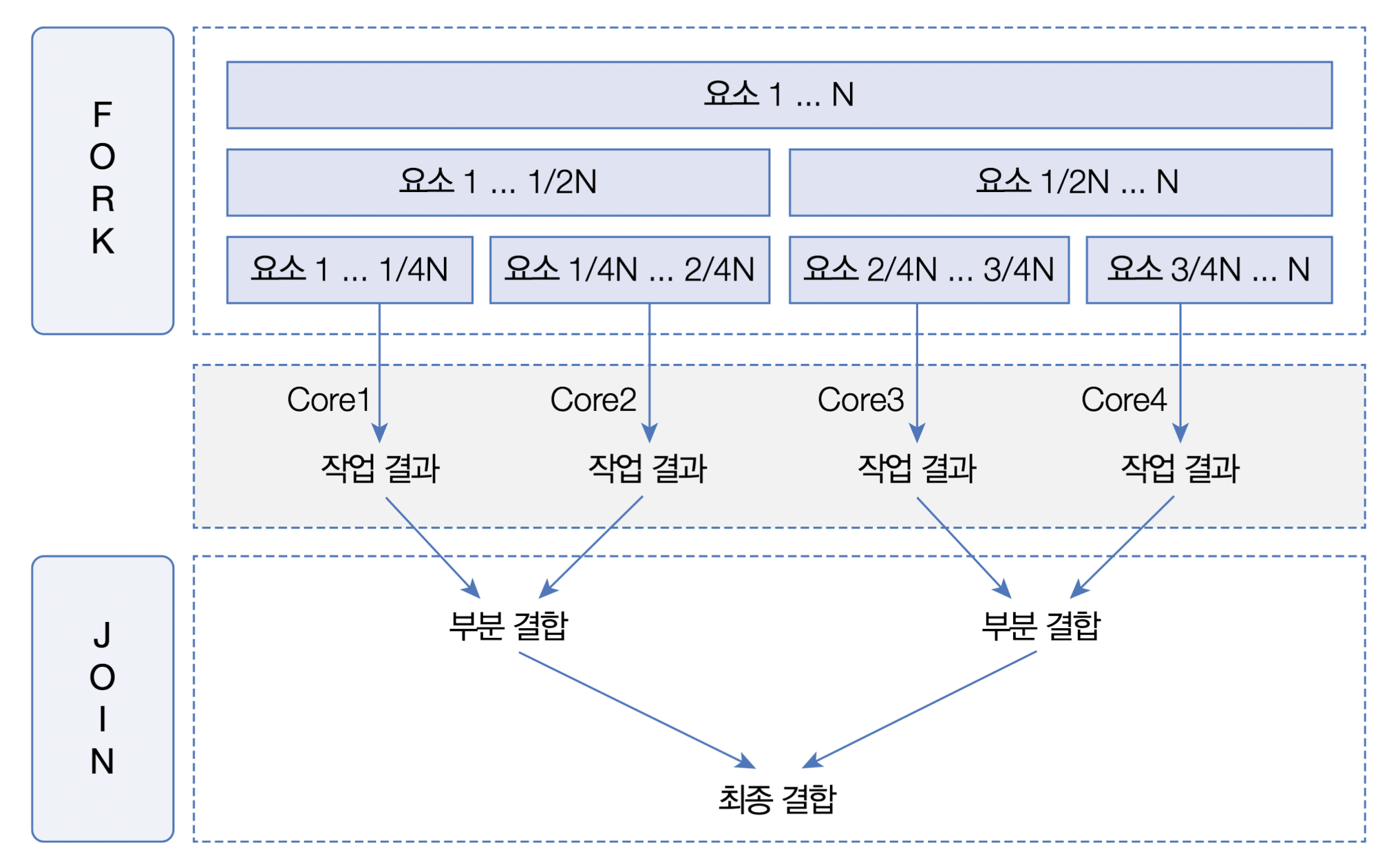
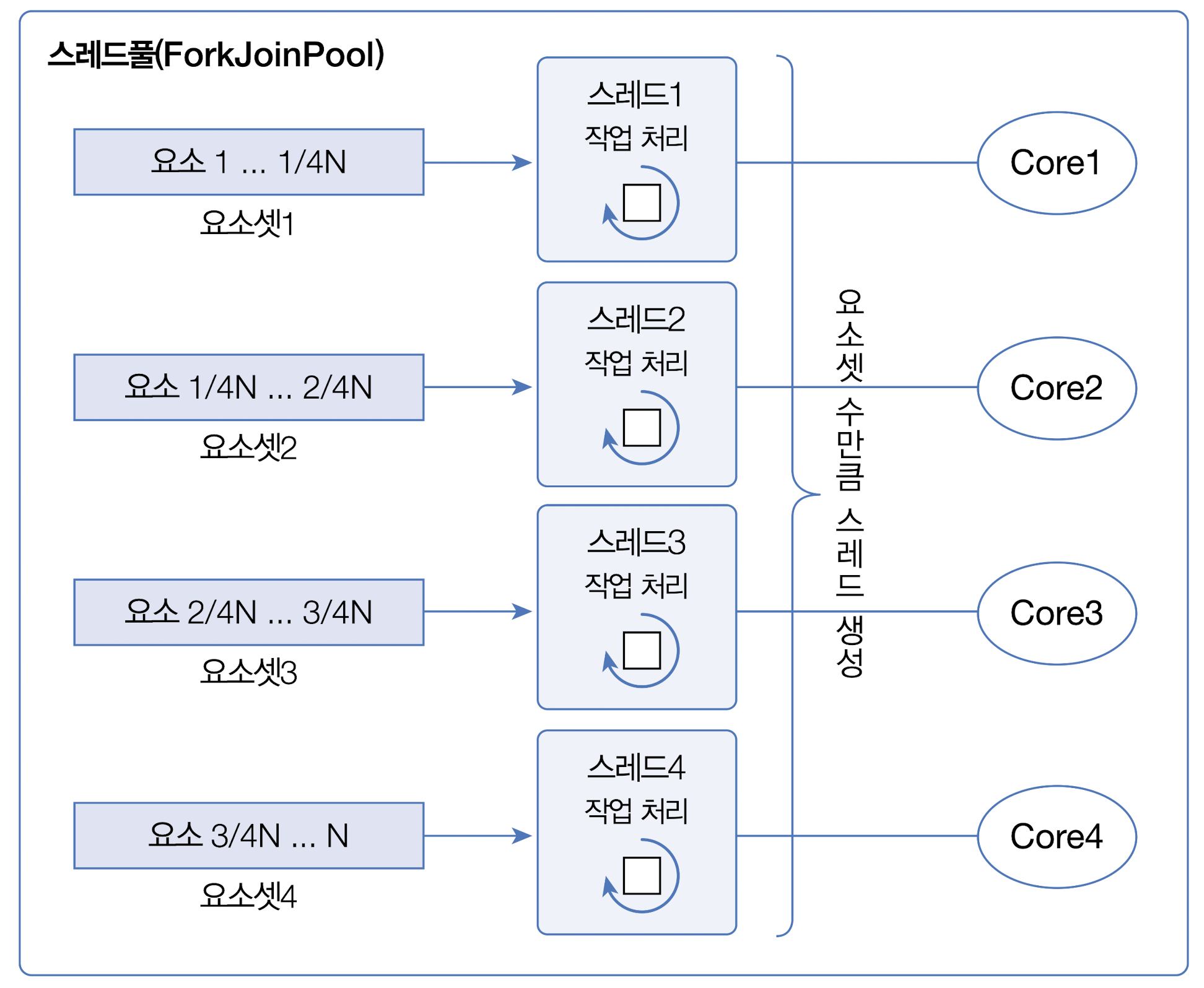
병렬 처리 스트림은 포크 단계에서 요소를 순서대로 분할하지 않으며 포크조인 프레임 워크는 병렬 처리를 위해 스레드풀을 사용한다. 각각의 코어에서 서브 요소셋을 처리하는 것은 작업 스레드가 해야 하므로 스레드 관리가 필요하다. 포크조인 프레임워크는 ExecutorService의 구현 객체인 ForkJoinPool을 사용해서 작업 스레드를 관리한다.
확인문제
1. 4번
2. 2번
3. 4번
4. 3번
5.
.filter(a -> a.toLowerCase().contains("java"))
.forEach(a -> System.out.println(a));6.
.mapToInt(Member::getAge)
.average()
.getAsDouble();7.
.filter(m -> m.getJob().equals("개발자"))
.collect(Collectors.toList());8.
.collect(Collectors.groupingBy(m -> m.getJob()));
groupingMap.get("개발자").stream()
.forEach(m -> System.out.println(m));
groupingMap.get("디자이너").stream()
.forEach(m -> System.out.println(m));