
지난 포스트에서는 kafka-console-producer.sh 쉘 스크립트를 사용하여 토픽을 생성하였다. 이번 포스트에서는 kafka-console-cunsumer.sh 쉘 스크립트를 이용해 토픽을 조회해보자.
bin 디렉토리 하위 kafka-console-consumer.sh 라는 이름의 쉘 스크립트가 있다.
kafka-console-consumer.sh는 특정 토픽의 데이터를 조회할 때 사용하는 쉘 스크립트 커맨드 라인 툴이다.
1. 토픽 메시지 value 조회
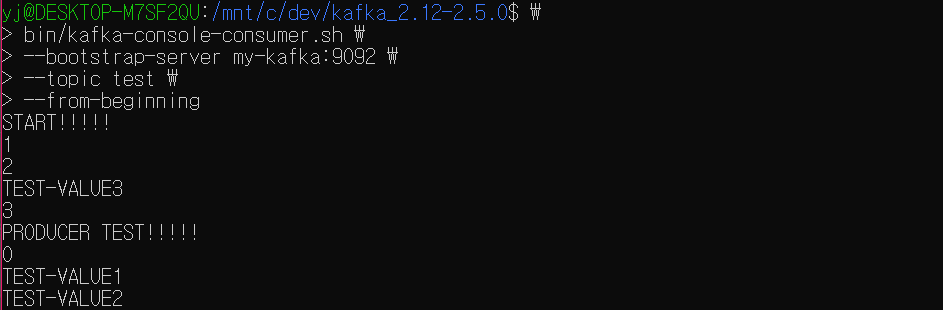
bin/kafka-console-consumer.sh \
--bootstrap-server {브로커} \
--topic {토픽명} \
--from-beginningbin/kafka-console-consumer.sh \
--bootstrap-server my-kafka:9092 \
--topic test \
--from-beginningkafka-console-consumer.sh 명령어 사용 시에는 필수값인 카프카 클러스터 정보와 토픽 이름을 지정해 토픽을 조회할 수 있다.
from-beginning 옵션을 사용하면 토픽에 저장된 가장 처음 데이터부터 출력한다.
2. 토픽 메시지 key-value 조회
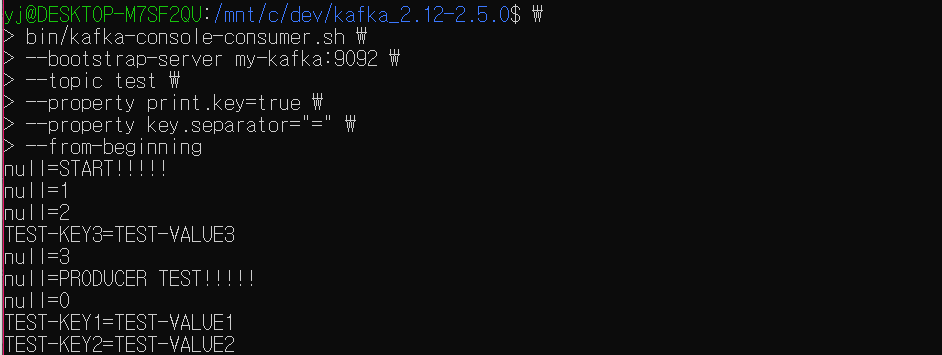
bin/kafka-console-consumer.sh \
--bootstrap-server {브로커} \
--topic {토픽명} \
--property print.key=true \
--property key.separator={구분자}
--from-beginningbin/kafka-console-consumer.sh \
--bootstrap-server my-kafka:9092 \
--topic test \
--property print.key=true \
--property key.separator==
--from-beginning만약 key-value 쌍 형태의 레코드를 확인하고 싶다면 property 옵션을 사용해 추가 옵션을 설정해줘야 한다.
첫번째, print.key=true 설정이 필요하다. 메시지 key를 함께 출력하겠다는 의미이다.
두번째, key.separator={구분자} 설정이 필요하다.
데이터를 key와 value로 구분할 때의 기준이 되는 구분자를 설정하는 것이다.
producer를 통해 key-value 형태로 생성한 데이터의 경우 해당 key와 value가 저장한대로 출력되는 것을 확인할 수 있다. 더불어, key를 따로 설정하지 않은 레코드는 key가 null로 출력되는 것을 확인할 수 있다.
3. 최대 컨슘 메시지 개수만큼 토픽 메시지 조회
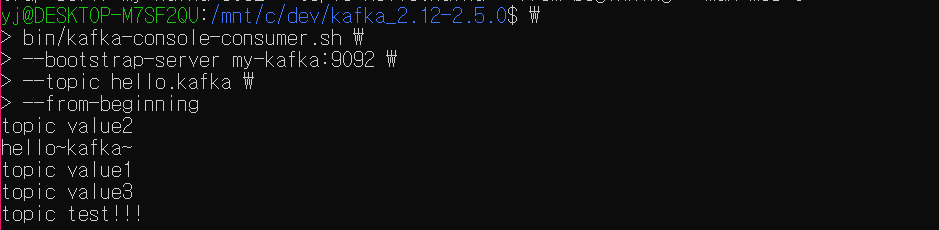
총 5개의 레코드를 가진 hello.kafka 라는 토픽이 있다.
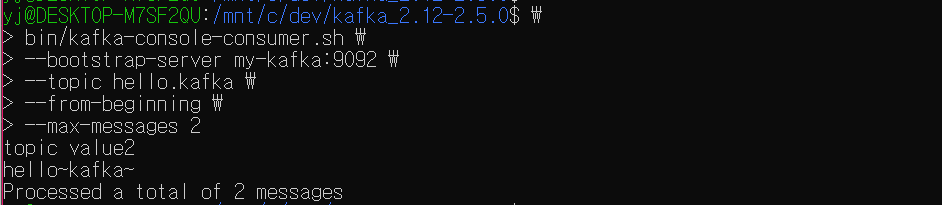
bin/kafka-console-consumer.sh \
--bootstrap-server {브로커} \
--topic {토픽명} \
--from-beginning
--max-messages {최댓값}bin/kafka-console-consumer.sh \
--bootstrap-server my-kafka:9092 \
--topic hello.kafka \
--from-beginning
--max-messages 2hello.kafka 토픽 중 특정 개수의 데이터 만큼만 보고 싶을 경우 max-messages 옵션을 사용한다.
max-messages 옵션을 사용하여 컨슈머가 컨슘할 수 있는 최대 컨슘 메시지 개수를 설정할 수 있다. 최대 맻 개의 메시지를 조회할 것인지에 대한 설정이다.
상용 환경 상에서는 수없이 많은 데이터가 있는데, 메시지 최댓값 설정이 없다면 너무나 많은 데이터가 출력될 것이다. 몇 개의 데이터만 조회하여 보고싶을 경우 이 옵션을 사용한다.
4. 특정 파티션만 토픽 메시지 조회
partiton 옵션을 사용하면 특정 파티션만 컨슘해올 수 있다.
토픽은 하나 이상의 파티션을 가지고 있다.
파티션이 여러개 있는 경우 여러 개의 파티션 중 한 개의 파티션만 특정해 데이터를 가지고 오고 싶을 수 있을 것이다.
이 때 partition 옵션을 통해 파티션 번호를 지정하면, 해당 번호의 파티션에서만 데이터를 가져올 수 있다.
예시를 통해 살펴보자.

여기 파티션이 3개인 토픽이 있다.
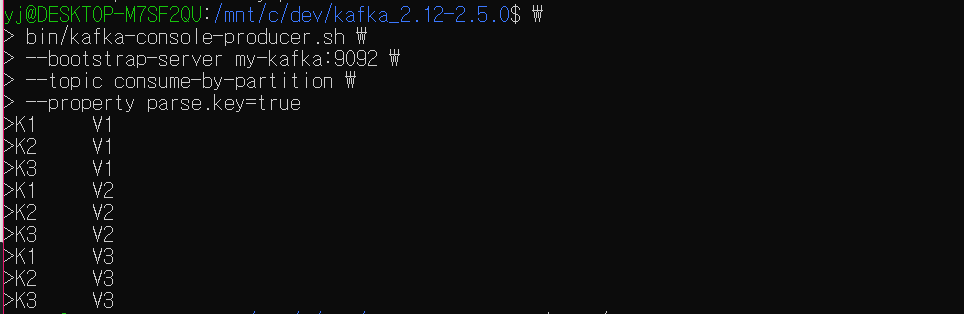
해당 토픽에 key-value 쌍의 레코드를 프로듀싱한다.
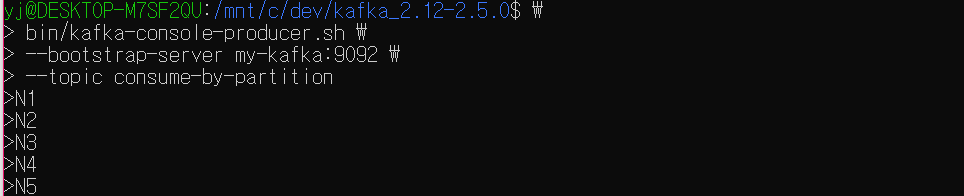
추가로 value만 가진 레코드를 생성한다.

bin/kafka-console-consumer.sh \
--bootstrap-server {브로커} \
--topic {토픽명} \
--partition {파티션 번호} \
--from-beginning \
--property print.key=truebin/kafka-console-consumer.sh \
--bootstrap-server my-kafka:9092 \
--topic consume-by-partition \
--partition 0 \
--from-beginning \
--property print.key=true0번 파티션부터 확인한다. 파티션을 특정해서 레코드를 확인할 때는 partition 옵션과 함께 파티션 번호를 지정해주면 된다.
0번 파티션에는 key가 null인 레코드 하나가 저장되어 있다.

1번 파티션에는 K2, K3 key 레코드들과 key가 null인 레코드들이 저장되어 있다.
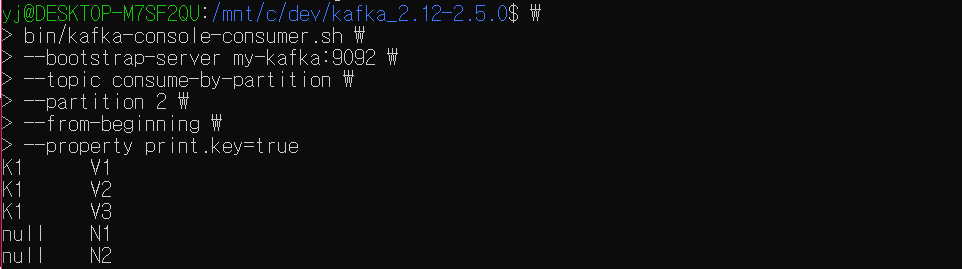
2번 파티션에는 K1 key 레코드들과 key가 null인 레코드들이 저장되어 있다.
이를 통해 이전 포스트에서 알아본 바와 같이
key-value 쌍의 메시지를 프로듀싱한 경우는 같은 파티션에 차례대로 저장되고,
value만을 가지는 메시지를 프로듀싱한 경우에는 라운드로빈 방식으로 파티션에 저장된다는 것을 확인할 수 있다.
5. 컨슈머 그룹 지정
1) 컨슈머 그룹을 지정한 조회
컨슈머 그룹이란 특정 목적을 가진 컨슈머들을 묶음으로 사용하는 것이다.
컨슈머 그룹은 어느 레코드 오프셋까지 읽었는지를 커밋시키기 위한 용도로 활용되고, 컨슈머 그룹이 존재하지 않으면 커밋되지 않는다.
토픽 조회 시 group 옵션을 통해 컨슈머 그룹을 지정하면 어느 레코드까지 읽었는지에 대한 오프셋 정보가 브로커에 저장된다.
bin/kafka-console-consumer.sh \
--bootstrap-server {브로커} \
--topic {토픽명} \
--group {그룹명} \
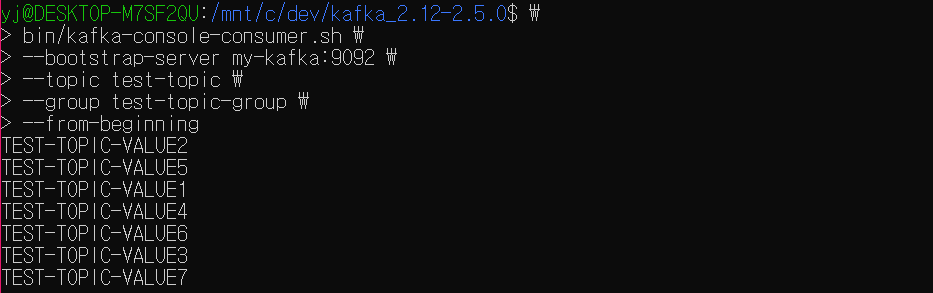
--from-beginningbin/kafka-console-consumer.sh \
--bootstrap-server my-kafka:9092 \
--topic test-topic \
--group test-topic-group \
--from-beginning데이터를 읽을 토픽에 대해 group 옵션을 통해 컨슈머 그룹명을 지정하고 컨슘한다.
컨슈머 그룹을 지정하여 읽고 나면 해당 그룹으로 마지막으로 읽은 메시지의 오프셋을 브로커에 저장(커밋)해두게 되므로, 다음에 읽을 때 부터는 해당 오프셋 다음부터 읽게 된다.
해당 예시에서는 'TEST-TOPIC-VALUE7' 이라는 레코드까지 기억할 것이다.
2) __consume_offsets

컨슈머 그룹이 오프셋을 커밋하고 나면 기존에 존재하지 않던 토픽이 하나 생성된 것을 확인할 수 있는데, 바로 __consume_offsets 라는 토픽이다.
컨슈머 그룹을 사용하게 되면 컨슈머 그룹이 어느 레코드까지 읽었는지에 대한 커밋 오프셋 정보를 바로 이 __consume_offsets 라는 이름의 토픽에 저장하는 것이다.
