컨슈머 애플리케이션을 개발해보자.
1. 의존성 추가
프로듀서 애플리케이션과 동일하게 build.gradle 디펜던시 추가가 필요하다.
dependencies {
implementation 'org.apache.kafka:kafka-clients:2.5.0'
implementation 'org.slf4j:slf4j-simple:1.7.30'
}
아파치 카프카를 배포할 때 사용하는 공식 라이브러리인 kafka-clients와 로그를 남기기 위한 slf4j 디펜던시를 추가한다.
2. 컨슈머 개발
이제 컨슈머를 개발해보자.
ConsumerTest.java 전체코드
package org.example.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class ConsumerTest {
/**
* 1. 전역 설정
*/
private final static Logger logger = LoggerFactory.getLogger(ConsumerTest.class);
private final static String TOPIC_NAME = "consumer-by-app";
private final static String BOOTSTRAP_SERVERS = "127.0.0.1:9092";
private final static String GROUP_ID = "test_group";
public static void main(String[] args) {
/**
* 2. 옵션에 대한 Properties 설정
*
* - 필수옵션
* 1) 서버
* 2) 메시지 키 역직렬화 옵션
* 3) 메시지 값 역직렬화 옵션
*
* - 선택옵션
* 1) 그룹아이디
* (선택옵션이지만 subscribe() 사용 시 필수로 필요)
*/
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
/**
* 3. 카프카 컨슈머 인스턴스 생성
* 미리 정의한 property를 바탕으로
* 지정한 서버와 통신하여
* 지정한 타입으로 메시지 키와 값을 역직렬화하는
* 카프카 컨슈머 인스턴스 생성
*/
// KafkaConsumer<키 역직렬화 타입, 값 역직렬화 타입> 인스턴스명 = new KafkaConsumer<>(프로퍼티 변수);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);
/**
* 4. subscribe() : 1개 이상의 토픽 구독
*/
consumer.subscribe(Arrays.asList(TOPIC_NAME));
// 컨슈머 애플리케이션은 계속 데이터를 읽어야 하므로 무한루프가 원칙
while (true) {
/**
* 5. poll() : 지정한 시간 단위로 데이터를 가져와서 ConsumerRecords 리턴
*
* ConsumerRecords: 레코드들의 묶음
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
// ConsumerRecords를 ConsumerRecord로 하나씩 꺼내서 처리
for (ConsumerRecord<String, String> record : records) {
logger.info("record : {}", record);
}
}
}
}1) 전역 설정
private final static Logger logger = LoggerFactory.getLogger(ConsumerTest.class);
private final static String TOPIC_NAME = "consumer-by-app";
private final static String BOOTSTRAP_SERVERS = "127.0.0.1:9092";
private final static String GROUP_ID = "test_group";먼저 전역 상수 설정을 해준다.
토픽명과 부트스트랩 서버 설정, 컨슈머 그룹 아이디를 설정한다.
2) Properties
/**
* 2. 옵션에 대한 Properties 설정
*
* - 필수옵션
* 1) 서버
* 2) 메시지 키 역직렬화 옵션
* 3) 메시지 값 역직렬화 옵션
*
* - 선택옵션
* 1) 그룹아이디
* (선택옵션이지만 subscribe() 사용 시 필수로 필요)
*/
Properties configs = new Properties();
configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
configs.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);코드 상에서는 가장 먼저 Properties를 생성한다.
필수 옵션인 서버, 메시지 키 역직렬화 옵션, 메시지 값 직렬화 옵션에 이어 선택 옵션인 그룹아이디 옵션을 추가한다.
3) KafkaConsumer
/**
* 3. 카프카 컨슈머 인스턴스 생성
* 미리 정의한 property를 바탕으로
* 지정한 서버와 통신하여
* 지정한 타입으로 메시지 키와 값을 역직렬화하는
* 카프카 컨슈머 인스턴스 생성
*/
// KafkaConsumer<키 역직렬화 타입, 값 역직렬화 타입> 인스턴스명 = new KafkaConsumer<>(프로퍼티 변수);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(configs);다음으로는 properties 변수를 파라미터로 넣어준 카프카컨슈머 인스턴스를 생성해준다.
4) subscribe()
/**
* 4. subscribe() : 1개 이상의 토픽 구독
*/
consumer.subscribe(Arrays.asList(TOPIC_NAME));카프카컨슈머의 subscribe() 메소드에 1개 이상의 토픽명을 파라미터로 하여 토픽을 구독해준다.
5) poll()
// 컨슈머 애플리케이션은 계속 데이터를 읽어야 하므로 무한루프가 원칙
while (true) {
/**
* 5. poll() : 지정한 시간 단위로 데이터를 가져와서 ConsumerRecords 리턴
*
* ConsumerRecords: 레코드들의 묶음
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
// ConsumerRecords를 ConsumerRecord로 하나씩 꺼내서 처리
for (ConsumerRecord<String, String> record : records) {
logger.info("record : {}", record);
}
}카프카컨슈머의 poll() 메소드를 통해 레코드를 컨슘한다.
이 때 얼마만큼의 시간 단위로 가져올 지의 duration을 파라미터로 설정해준다.
poll()메소드는 ConsumerRecords를 리턴하는데, 이는 레코드들의 묶음이다.
반복문을 돌며 하나씩 ConsumerRecord로 꺼내서 처리할 수 있다.
3. 결과 확인
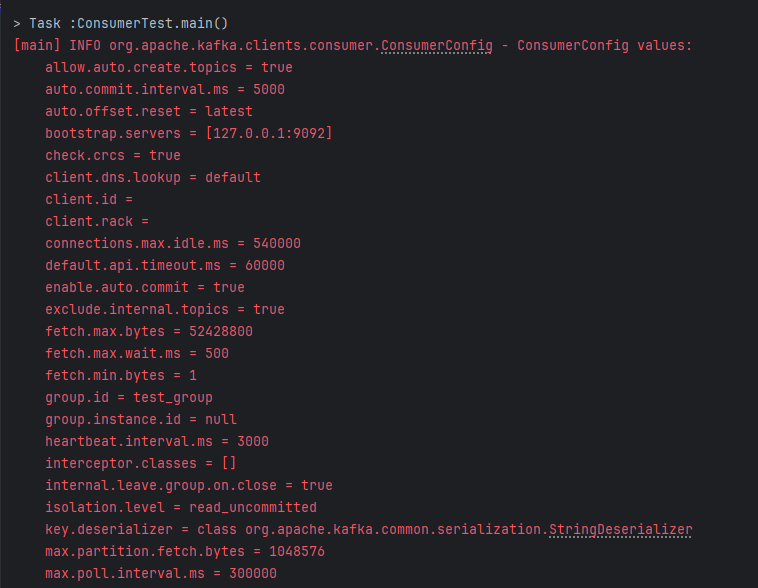
실행 시 다음과 같은 카프카 설정을 로그로 확인할 수 있다.

컨슈머가 읽어올 수 있도록 직접 토픽에 데이터를 넣어준다.
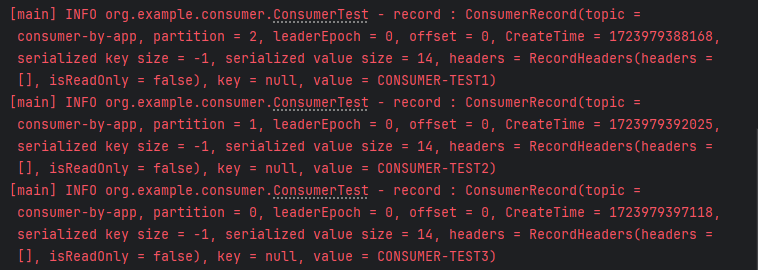
로그로 찍어준 레코드 정보를 확인할 수 있다.
