레코드는 기본적으로 해시값에 의해 자동으로 파티션에 분배된다.
그러나 운영하다보면 특정 데이터의 레코드를 특정 파티션으로 전송해야 하는 경우가 있다.
저번 포스팅과 같이 레코드를 생성할 때 레코드에 파티션 번호를 파라미터로 지정해주는 방법이 있다.
이렇게 각각의 레코드에 직접 파티션 번호를 지정하는 방식이 아닌, Partitioner 인터페이스를 사용하여 사용자 정의 파티셔너를 만들어 해결할 수도 있다.
1. 프로듀서 개발
ProducerWithCustomPartitioner 전체코드
package org.example;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class ProducerWithCustomPartitioner {
private final static String TOPIC_NAME = "topic-with-custom-partitioner";
private final static String BOOTSTRAP_SERVERS = "127.0.0.1:9092";
public static void main(String[] args) {
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// property에 파티셔너 클래스를 커스텀 파티셔너 클래스로 지정
// -> 프로듀서 인스턴스가 시작될 때 해당 커스텀 파티셔너의 로직을 참고해서 실행됨
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);
KafkaProducer<String, String> producer = new KafkaProducer<>(configs);
ProducerRecord<String, String> record1 = new ProducerRecord<>(TOPIC_NAME, "KEY1-PTN0", "VAL1");
ProducerRecord<String, String> record2 = new ProducerRecord<>(TOPIC_NAME, "KEY2", "VAL2");
ProducerRecord<String, String> record3 = new ProducerRecord<>(TOPIC_NAME, "KEY2", "VAL3-PTN0");
ProducerRecord<String, String> record4 = new ProducerRecord<>(TOPIC_NAME, "VAL4");
producer.send(record1);
producer.send(record2);
producer.send(record3);
producer.send(record4);
producer.flush();
producer.close();
}
}CustomPartitioner 전체코드
package org.example;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.InvalidRecordException;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.utils.Utils;
import java.util.List;
import java.util.Map;
/**
* Partitioner 인터페이스를 구현한 커스텀 파티셔너 클래스
* return 파티션 번호
*/
public class CustomPartitioner implements Partitioner {
@Override
public int partition(
String topic,
Object key,
byte[] keyBytes,
Object value,
byte[] valueBytes,
Cluster cluster) {
// 키가 없을 경우 예외 던지기
if(keyBytes == null)
throw new InvalidRecordException("Need Msg Key!");
// 레코드의 키 또는 값이 PTN0을 포함하는 경우 0 리턴
if(((String)key).contains("PTN0") || ((String)value).contains("PTN0"))
return 0;
// 나머지는 해시값으로 변환한 파티션 번호 리턴
// -> 동일한 메시지 키는 동일한 파티션으로 분배
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}1) CustomPartitioner 구현
CustomPartitioner.java
/**
* Partitioner 인터페이스를 구현한 커스텀 파티셔너 클래스
* return 파티션 번호
*/
public class CustomPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}사용자 지정 파티셔너를 만들기 위해 Partitioner 인터페이스를 구현해준다.
Partitioner 인터페이스는 partition(), close(), configure() 추상메소드를 가지는데,
그 중에서도 partition()을 이용해 프로듀서가 레코드를 토픽의 어느 파티션으로 전송하게 할 지에 대한 로직을 정의해줄 수 있다.
CustomPartitioner.java
@Override
public int partition(
String topic,
Object key,
byte[] keyBytes,
Object value,
byte[] valueBytes,
Cluster cluster) {
// 키가 없을 경우 예외 던지기
if(keyBytes == null)
throw new InvalidRecordException("Need Msg Key!");
// 레코드의 키 또는 값이 PTN0을 포함하는 경우 0 리턴
if(((String)key).contains("PTN0") || ((String)value).contains("PTN0"))
return 0;
// 나머지는 해시값으로 변환한 파티션 번호 리턴
// -> 동일한 메시지 키는 동일한 파티션으로 분배
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}이제 partition() 메소드를 구현해보자.
이 메소드는 리턴값으로 int형 파티션 번호를 리턴한다.
이 리턴값에 의해 레코드들이 각각의 파티션 번호로 분배되는 것이다.
먼저 키가 없을 경우에는 예외를 던지고,
레코드의 키 또는 값에 PTN0을 포함하는 경우에는 0번 파티션을 리턴할 것이다.
나머지 경우에는 해시값으로 변환한 파티션 번호를 리턴하도록 구현하였다.
2) 레코드 프로듀싱
ProducerWithCustomPartitioner.java
Properties configs = new Properties();
configs.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
configs.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
configs.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// property에 파티셔너 클래스를 커스텀 파티셔너 클래스로 지정
// -> 프로듀서 인스턴스가 시작될 때 해당 커스텀 파티셔너의 로직을 참고해서 실행됨
configs.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, CustomPartitioner.class);이제 만들어준 커스텀 파티셔너를 적용하여 레코드를 보내볼 것이다.
프로듀서 인스턴스가 생성될 때 커스텀 파티셔너 클래스의 로직을 참고시키기 위해
property의 파티셔너 클래스 설정으로 생성한 커스텀 파티셔너 클래스를 지정해준다.
ProducerWithCustomPartitioner.java
ProducerRecord<String, String> record1 = new ProducerRecord<>(TOPIC_NAME, "KEY1-PTN0", "VAL1");
ProducerRecord<String, String> record2 = new ProducerRecord<>(TOPIC_NAME, "KEY2", "VAL2");
ProducerRecord<String, String> record3 = new ProducerRecord<>(TOPIC_NAME, "KEY2", "VAL3-PTN0");
ProducerRecord<String, String> record4 = new ProducerRecord<>(TOPIC_NAME, "VAL4");다음의 결과를 예상하고 레코드를 생성한다.
- 키에 PTN0을 포함하는 레코드 -> 0번 파티션
- 키, 값 모두에 PTN0을 포함하지 않는 레코드 -> 해시값에 의한 파티션
- 값에 PTN0을 포함하는 레코드 -> 0번 파티션
- 키를 지정하지 않은 레코드 -> 레코드 생성되지 않음
2. 결과 확인
어플리케이션을 기동하고, 카프카 설정에 대한 로그를 확인한다.
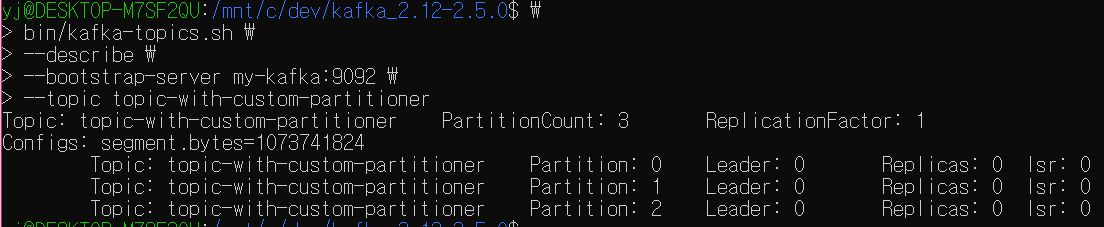
토픽이 잘 생성되었는지 확인한다.
토픽 생성 시 0~2번 까지 총 3개의 파티션이 생성되어 있다.
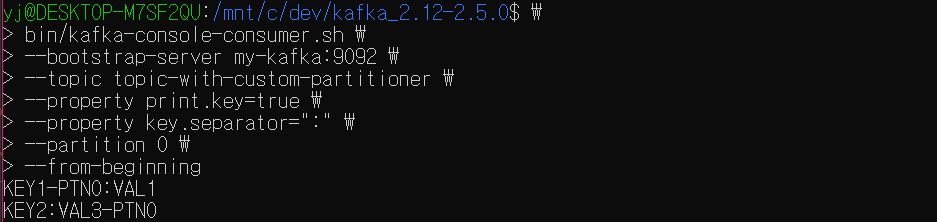
0번 파티션을 확인한다.
CustomPartitioner의 partition 메소드에 정의된대로 키에 PTN0을 포함하거나, 값에 PTN0을 포함하는 레코드들이 0번 파티션에 들어왔다.
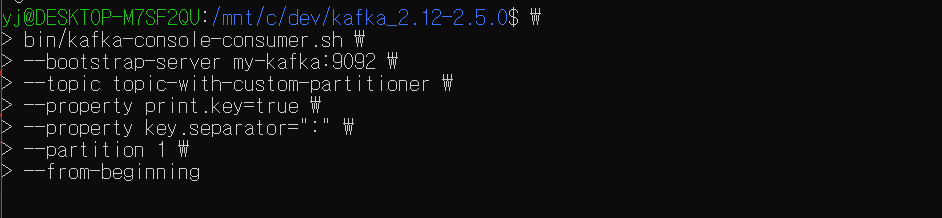
1번 파티션에는 아무 레코드도 생성되지 않았다.
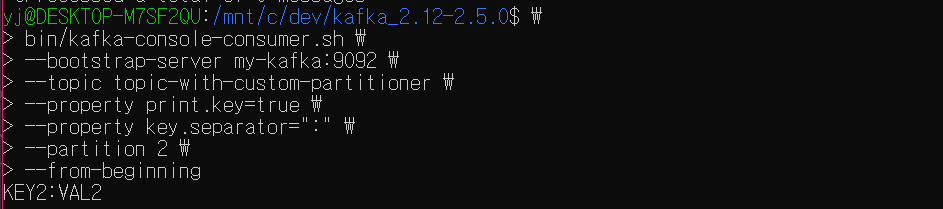
2번 파티션을 확인한다.
우리는 키가 KEY2인 레코드를 2개 생성했었다.
원래대로라면 같은 키를 가진 레코드는 같은 해시값을 가지므로 같은 파티션에 저장되어야 하지만, 커스텀 파티셔너 클래스로 로직을 수정해주었다.
그 중 하나의 레코드는 해시값에 의해 2번 파티션으로 분배되었고,
값이 PTN0을 포함하는 레코드는 해시값에 의한 분배 원칙을 따르는 것이 아니라 지정해준대로 0번 파티션으로 분배된 것이다.
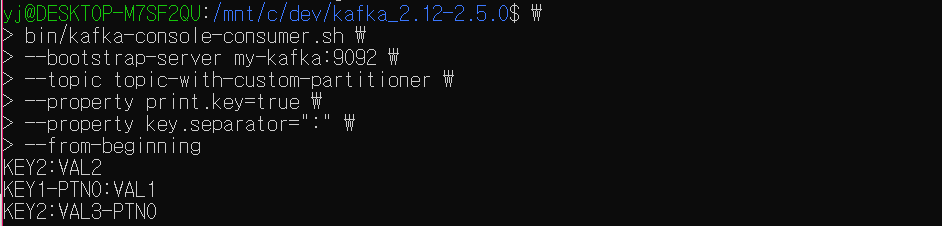
파티션을 지정하지 않고 토픽의 전체 레코드를 조회해봐도 키를 지정해주지 않은 VAL4 레코드는 어디에도 보이지 않는다.
이는 키가 없을 경우 예외를 던져서 레코드를 전송하지 않았기 때문이다.
