쿼츠 스케줄러를 알아보자.
0. 쿼츠 스케줄러
쿼츠 스케줄러(Quartz Scheduler)는 자바 기반 스케쥴링 라이브러리이다.
특정 시간에 반복 실행해야 하는 작업(배치 작업, 정기적 데이터 처리 등)을 효율적으로 관리하는 데 사용한다.
스프링과 연동하여 정해진 주기에 맞춰 작업을 실행하는 배치 시스템을 구축할 때 많이 활용된다.
쿼츠의 핵심 개념은 Job, Trigger, Scheduler로 구성된다.
1) Job (작업)
Job 인터페이스를 구현하여 실행할 작업(비즈니스 로직)을 정의하는 클래스이다.
import org.quartz.Job;
import org.quartz.JobExecutionContext;
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext context) {
System.out.println("Quartz Job 실행 중...");
}
}2) Trigger (트리거)
Job이 실행될 시점을 정의한다. SimpleTrigger 또는 CronTrigger를 사용할 수 있다.
import org.quartz.CronScheduleBuilder;
import org.quartz.Trigger;
import org.quartz.TriggerBuilder;
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("myTrigger", "group1")
.withSchedule(CronScheduleBuilder.cronSchedule("0 0/1 * * * ?")) // 매 분 실행
.build();3) Scheduler (스케줄러)
Job과 Trigger를 등록하고 실행을 관리하는 역할을 한다.
import org.quartz.Scheduler;
import org.quartz.SchedulerFactory;
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.start();
scheduler.scheduleJob(job, trigger);
scheduler.shutdown();1. 의존성 추가
먼저 쿼츠 스케줄러 라이브러리를 사용하기 위해 build.gradle 파일에 쿼츠 스케줄러를 추가해준다.
build.gradle
implementation 'org.springframework.boot:spring-boot-starter-quartz'2. 설정파일 추가
쿼츠는 매우 유연한 설정이 가능한 애플리케이션이다. 쿼츠를 설정하는 가장 좋은 방법은 quartz.properties 파일을 작성하는 것이다.
이렇게 작성한 quartz.properties 파일은 애플리케이션 클래스패스에 가져다 놓으면 된다.
쿼츠는 quartz.properties 라고 불리는 설정파일을 사용한다.
이 파일은 필수는 아니다.
쿼츠는 기본적인 설정이 없는 경우 기본값(Default settings)을 사용하여 실행된다.
그러나, 기본 구성 외 추가적인 커스텀 설정을 적용하거나 데이터베이스 저장 방식으로 Quartz를 사용할 때는 quartz.properties 파일이 필요하며, 클래스패스 경로에 위치해있어야 한다.
기본적은 설정은 다음과 같다.
org.quartz.scheduler.instanceName = MyScheduler
org.quartz.threadPool.threadCount = 3
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStoreorg.quartz.scheduler.instanceName: 스케줄러 이름org.quartz.threadPool.threadCount: 스레드 풀의 스레드 개수. 동시에 돌 수 있는 최대 Job 개수 설정org.quartz.jobStore.class: 쿼츠가 Job과 Trigger 데이터를 어디에 저장할지에 대한 설정.
1) org.quartz.jobStore.class
쿼츠는 데이터를 저장하는 방식으로 메모리(RAM) 저장방식과 데이터베이스(DB) 저장방식을 제공한다.
이에 대한 설정이 바로 org.quartz.jobStore.class이다.
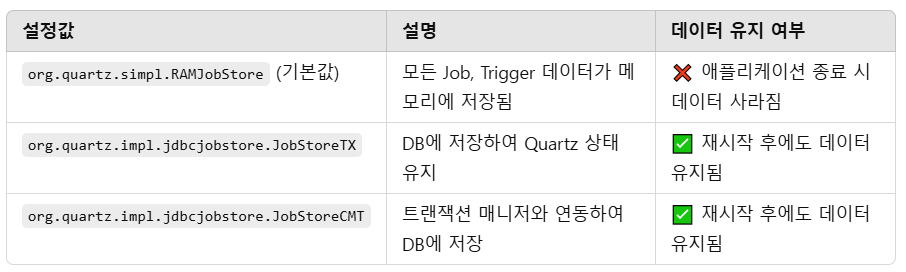
org.quartz.jobStore.class 설정이 없으면 기본적으로 RAMJobStore(메모리 저장 방식)가 사용되며, JobStoreTX나 JobStoreCMT를 사용해야 DB에 저장된다.
메모리에 저장 - RAMJobStore
org.quartz.jobStore.class=org.quartz.simpl.RAMJobStore모든 Job, Trigger 데이터가 메모리에 저장되며, 애플리케이션이 재시작되면 모든 데이터가 사라진다.
DB 설정이 있더라도 RAMJobStore가 설정되어 있다면, 쿼츠는 DB를 사용하지 않고 에모리에 데이터를 저장한다.
DB에 저장 - JobStoreTX/JobStoreCMT
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.dataSource=myDS
org.quartz.jobStore.tablePrefix=QRTZ_먼저 org.quartz.jobStore.class 설정을 JobStoreTX(/JobStoreCMT)로 작성 후, 추가 DB 설정을 작성한다.
이 설정이 있어야만 쿼츠가 데이터를 DB에 저장하고 유지한다. (DB 설정이 있더라도 JobStoreTX(/JobStoreCMT)가 아니라면 DB를 사용하지 않음)
JobStoreTX(/JobStoreCMT)를 사용하면 애플리케이션이 종료되어도 Job, Trigger 정보가 유지된다.
DB에 쿼츠 데이터를 저장하려고 하더라도, 먼저 RamJobStore로 쿼츠를 실행해볼 것을 추천한다.
먼저 DB 설정과 관계없이 쿼츠가 정상 작동한 지 확인하고, 그 후에 DB를 활용하는 방식으로 DB와 연동까지 확인해보는 것이 좋다.
3. start(), shutdown()
설정은 마쳤으니, 샘플 코드를 만들어서 스케줄러를 실행해보자.
다음 코드는 스케줄러의 인스턴스를 생성 후, 스케줄러를 시작하고 셧다운시키는 코드이다.
package com.example.test.quartz;
import org.quartz.Scheduler;
import org.quartz.SchedulerException;
import org.quartz.impl.StdSchedulerFactory;
public class QuartzTest {
public static void main(String[] args) {
try {
// 스케줄러 팩토리를 통한 인스턴스 생성
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.start();
// Job, Trigger 정의 및 스케줄 등록
scheduler.shutdown();
} catch (SchedulerException e) {
throw new RuntimeException(e);
}
}
}스케줄러를 사용하기 전에 먼저 SchedulerFactory를 이용해 스케줄러 인스턴스를 생성해야 한다.
Scheduler 객체를 생성한 직후에는 스케줄러가 stand-by(대기) 상태에 들어가며, 그 후 시작하고 셧다운시킬 수 있다.
start()를 호출해야만 스케줄러가 실제로 잡을 실행하게 된다.
다만, 스프링부트의 경우에는 스프링이 자동으로 스케줄러를 시작해주는 경우가 있다.
만약 스프링부트 환경에서 쿼츠를 사용할 경우, start()를 명시적으로 호출하지 않아도 실행될 수 있다.
하지만 쿼츠의 공식 문서에서는 반드시 start()를 호출할 것을 권장한다.
그 이유는 첫번째 start()를 호출해야 스케줄러가 실행된다는 것을 명확하게 할 수 있도록 코드의 명확성을 유지할 뿐 아니라, 환경이 바뀌더라도 동일한 동작을 보장하기 위함이다.
스케줄러가 한번 셧다운되면 스케줄러 객체를 다시 생성하기 전까지 스케줄러가 재실행되지 않는다.
또한 트리거는 스케줄러가 시작되거나 일시정지된 상태에서는 발동되지 않는다.
스케줄러의 start()와 shutdown() 사이에는 잡, 트리거를 정의하고, 스케줄을 등록할 수 있다.
정상적으로 실행된다면 다음과 같은 로그를 확인할 수 있다.
21:33:06.802 [main] INFO org.quartz.core.QuartzScheduler -- Quartz Scheduler v.2.3.2 created.
21:33:06.802 [main] INFO org.quartz.simpl.RAMJobStore -- RAMJobStore initialized.
21:33:06.803 [main] INFO org.quartz.core.QuartzScheduler -- Scheduler meta-data: Quartz Scheduler (v2.3.2) 'MyScheduler' with instanceId 'NON_CLUSTERED'
Scheduler class: 'org.quartz.core.QuartzScheduler' - running locally.
NOT STARTED.
Currently in standby mode.
Number of jobs executed: 0
Using thread pool 'org.quartz.simpl.SimpleThreadPool' - with 3 threads.
Using job-store 'org.quartz.simpl.RAMJobStore' - which does not support persistence. and is not clustered.
21:33:06.803 [main] INFO org.quartz.impl.StdSchedulerFactory -- Quartz scheduler 'MyScheduler' initialized from default resource file in Quartz package: 'quartz.properties'
21:33:06.803 [main] INFO org.quartz.impl.StdSchedulerFactory -- Quartz scheduler version: 2.3.2
21:33:06.803 [main] INFO org.quartz.core.QuartzScheduler -- Scheduler MyScheduler_$_NON_CLUSTERED started.
21:33:06.824 [main] INFO org.quartz.core.QuartzScheduler -- Scheduler MyScheduler_$_NON_CLUSTERED shutting down.
21:33:06.825 [main] INFO org.quartz.core.QuartzScheduler -- Scheduler MyScheduler_$_NON_CLUSTERED paused.
21:33:06.825 [main] INFO org.quartz.core.QuartzScheduler -- Scheduler MyScheduler_$_NON_CLUSTERED shutdown complete.4. Quartz API, Job, Trigger
1) Quartz API
쿼츠 API의 주요 인터페이스는 다음과 같다.
Scheduler: 스케줄러와 상호작용하는 메인 APIJob: 스케줄러가 실행할 컴포넌트에서 구현해야 할 인터페이스JobDetail: Job 객체를 정의하기 위해 사용Trigger: 주어진 Job이 실행될 일정을 정의하는 컴포넌트JobBuilder: Job 객체를 정의하는 JobDetail 객체를 정의하고 빌드하는데 사용TriggerBuilder: Trigger 객체를 정의하고 빌드하는 데 사용
스케줄러의 생애주기는 SchedulerFactory를 사용한 객체 생성 시점부터 shutdown() 호출 시점 까지이다.
객체를 생성하고 나서는 잡과 트리거를 추가, 삭제 등 스케줄링과 관련된 다양한 작업을 수행할 수 있다.
그러나 스케줄러는 start() 호출을 통해 시작되기 전 까지 어느 트리거도 실행시키지 않는다.
스케줄러 객체 생성, start() 이후 잡과 트리거를 정의하고 스케줄을 등록하는 코드를 살펴보자.
package com.example.test.quartz;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class QuartzTest {
public static void main(String[] args) {
try {
// 스케쥴러 팩토리를 통한 인스턴스 생성
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.start();
// JobBuilder를 통해 Job을 정의하고 Job 클래스와 연결
JobDetail job = JobBuilder.newJob(HelloJob.class) // JobBuilder 객체 생성, JobBuilder.jobClass 세팅
.withIdentity("myJob", "group1") // JobKey 객체 생성, JobBuilder.key 세팅
.build(); // JobBuilder 속성들로 JobDetailImpl(JobDetail 구현) 객체 생성 및 세팅 후 리턴
// Job을 발동할 일정 설정
Trigger trigger = TriggerBuilder.newTrigger() // TriggerBuilder 객체 생성
.withIdentity("myTrigger", "group1") // TriggerKey 객체 생성, TriggerBuilder.key 세팅
.startNow() // 현재 시각으로 TriggerBuilder.startTime 세팅
.withSchedule( // ScheduleBuilder 받아서 TriggerBuilder.scheduleBuilder 세팅
SimpleScheduleBuilder.simpleSchedule() // SimpleScheduleBuilder 객체 생성
.withIntervalInSeconds(4) // SimpleScheduleBuilder.interval(값*1000) 세팅
.repeatForever() // 무한반복. SimpleScheduleBuilder.repeatCount(-1) 세팅, SimpleScheduleBuilder 리턴
)
.build(); // TriggerBuilder 속성들로 MutableTrigger(Trigger 상속) 객체 생성 및 세팅 후 리턴
// 쿼츠 스케줄러에 Job, Trigger 등록 -> 스케줄에 따라 작업을 실행
scheduler.scheduleJob(job, trigger);
// scheduler.shutdown(true);
} catch (SchedulerException e) {
throw new RuntimeException(e);
}
}
}쿼츠 스케줄러에서 객체를 정의하고 생성하는 과정은 각 빌더를 통해 수행한다.
JobDetail 정의는 JobBuilder 클래스를 통해, Trigger 정의는 TriggerBuilder 클래스를 통해, Schedule 정의는 SimpleScheduleBuilder 클래스를 통해 이루어진다.
위 코드에서는 각 메소드의 출처를 표시하기 위해 클래스명을 모두 붙였다.
실제로는 모두 static 메소드이므로 다음과 같이 static import를 사용하여 클래스명을 생략할 수 있다.
import static org.quartz.JobBuilder.*;
import static org.quartz.SimpleScheduleBuilder.*;
import static org.quartz.CronScheduleBuilder.*;
import static org.quartz.CalendarIntervalScheduleBuilder.*;
import static org.quartz.TriggerBuilder.*;
import static org.quartz.DateBuilder.*;2) Job, Trigger
단하나의 심플한 메서드를 갖는 Job 인터페이스를 구현한 구현체인 Job을 정의해야 한다.
다음은 Job 인터페이스 코드이다.
Job Interface
package org.quartz;
public interface Job {
void execute(JobExecutionContext var1) throws JobExecutionException;
}이제 Job 인터페이스에 대한 구현체인 HelloJob을 구현해보자.
execute() 메서드에서 현재 시간 정보와 함께 출력문을 수행한다.
package com.example.test.quartz;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import java.time.LocalTime;
import java.time.format.DateTimeFormatter;
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
LocalTime now = LocalTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm:ss");
String formattedTime = now.format(formatter);
System.out.println("[" + formattedTime + "] executed");
}
}이제 실행해보면 지정해준 시간인 4초마다 로그가 반복적으로 찍히는 것을 확인할 수 있다.
[21:38:07] executed
[21:38:11] executed
[21:38:15] executedexecute(), JobExecutionContext
잡의 트리거가 발동할 때 스케줄러의 워커 스레드 중 하나에 의해 구현 클래스의 execute() 메서드가 호출된다.
이때 JobExecutionContext 객체를 파라미터로 넘기는데, 이 객체는 run-time 환경에 대한 정보를 제공하며 구체적으로는 다음과 같다.
- Job을 실행한 Scheduler
- Job 실행을 유발한 Trigger
- Job 설정을 담고 있는 JobDetail
JobDetail
JobDetail 객체는 쿼츠 클라이언트(사용자 프로그램)가 잡을 스케줄러에 추가할때 생성된다.
이 객체에는 잡의 다양한 속성이 포함된다.
속성 중 JobDataMap은 정의한 잡 클래스의 인스턴스에 대한 상태 정보를 저장하는 데 사용된다.
Trigger
Trigger 객체는 잡의 실행을 일으키는 역할을 한다.
잡을 스케줄링하려면, 트리거 객체를 생성한 후 원하는 실행 일정에 맞게 속성을 설정해줘야 한다.
트리거에도 JobDataMap을 설정할 수 있는데, 트리거 실행 시 필요한 매개변수를 Job으로 전달하는 데 사용한다.
SimpleTrigger, CronTrigger
쿼츠는 여러 유형의 트리거를 포함하고 있는데, 그 중 가장 많이 사용되는 것은 SimpleTrigger와 CronTrigger이다.
SimpleTrigger는 특정 시간에 한번만 실행하거나 특정 시간마다 N번 반복(ex. 10초마다 5번 반복 실행)하여 실행할 때 사용한다.
CronTrigger는 캘린더 기반(ex. 매주 금요일 정오) 스케줄링에 사용한다.
Job과 Trigger의 분리
왜 잡과 트리거일까?
많은 잡 스케줄러는 잡과 트리거에 대한 개념을 별도로 두지 않는다.
일부 스케줄러는 잡을 단순히 실행시간과 ID를 포함한 개체를 정의하기도 하고, 다른 스케줄러들은 쿼츠의 잡과 트리거 개념을 하나로 합친 형태로 사용하기도 한다.
그러나 쿼츠 개발 시 실행 일정(트리거)과 실행할 작업(잡)을 분리하는 것이 더 합리적이라고 판단했다고 한다.
그 이점으로는 잡을 트리거와 독립적으로 생성하고 저장할 수 있다는 점이 있다.
또한 하나의 잡에 여러개의 트리거를 연결할 수도 있다.
이렇게 되면 트리거가 만료되어도 잡을 유지할 수 있고, 이후 다시 스케줄링이 가능하게 된다.
또 트리거만 단독으로 변경이 가능해서 잡을 새로 정의할 필요 없이 실행 일정만 조정해주면 된다.
이렇게 쿼츠는 잡과 트리거를 분리하여 더 강력하고 유연한 스케줄링 기능을 제공한다.
5. Job, Job Details
잡은 단순히 execute() 메서드만 구현하면 되지만, 몇가지를 더 알아보기로 하자.
Job 인터페이스의 구현체인 Job 클래스에서는 해당 잡을 어떻게 수행할 지에 대한 비즈니스 로직을 구현한다.
하지만 쿼츠는 해당 Job 객체가 가져야 할 추가적인 속성들을 필요로 한다.
이러한 정보를 바로 JobDetail 클래스를 통해 제공한다.
JobDetail 객체는 JobBuilder 클래스를 사용하여 생성한다.
이때 코드를 DSL 스타일로 자연스럽게 작성하기 위해 메서드들을 static import하여 사용하는 것이 좋다.
import static org.quartz.JobBuilder.*;쿼츠에서 잡의 본질과 Job 객체의 생애주기를 알아보자.
다음은 앞서 살펴보았던 코드이다.
JobDetail job = newJob(HelloJob.class)
.withIdentity("myJob", "group1") // name "myJob", group "group1"
.build();
Trigger trigger = newTrigger()
.withIdentity("myTrigger", "group1")
.startNow()
.withSchedule(simpleSchedule()
.withIntervalInSeconds(40)
.repeatForever())
.build();
sched.scheduleJob(job, trigger);그리고 다음과 같이 Job 인터페이스를 구현한 HelloJob 클래스가 있다.
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
LocalTime now = LocalTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm:ss");
String formattedTime = now.format(formatter);
System.out.println("[" + formattedTime + "] executed");
}
}JobDetail 객체 생성과 전달
다음과 같이 스케줄러에게 JobDetail 객체를 제공한다.
sched.scheduleJob(job, trigger);이 JobDetail을 생성할 때에는 Job의 클래스 정보를 제공함으로써 스케줄러에게 실질적으로 실행할 잡(HelloJob)을 알려줘야 한다.
JobDetail job = newJob(HelloJob.class)
...Job 클래스의 기본생성자
스케줄러가 잡을 실행할 때 마다, 매번 새로운 Job 객체를 생성하고 execute() 메서드를 호출한다.
JobFactory가 Job 클래스의 기본생성자를 호출하여 Job 객체를 생성하고, 생성된 Job 객체를 통해 execute() 메서드를 호출하는 것이다.
잡의 실행이 완료되면 Job 클래스 인스턴스에 대한 참조를 끊고, 이후 GC에 의해 메모리 상에서 제거된다.
이 때문에 쿼츠에서 기본적으로 사용하는 JobFactory 구현체는 잡 객체를 생성하기 위해 기본생성자를 사용해야 한다.
HelloJob 클래스의 코드는 사실 기본생성자를 가지고 있고, 이 숨겨진 기본생성자를 통해 객체가 생성되고 객체의 메서드가 실행된 것이다.
(클래스 내에 명시적으로 정의된 생성자가 하나도 없으면 객체 생성 시 기본적 초기화를 수행할 수 있도록 자바 컴파일러는 기본 생성자를 자동으로 생성해줌)
public class HelloJob implements Job {
// 코드에 명시되지 않아도 컴파일러가 기본생성자 자동 생성
public HelloJob() {
}
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// Job 비즈니스 로직
}
}그러므로 Job 클래스 내부에는 반드시 기본 생성자가 존재해야 한다.
다음과 같이 매개변수 생성자만 정의하면 쿼츠가 기본생성자를 이용하여 Job 객체를 생성할 수 없게 된다.
(매개변수 생성자가 존재하면 기본생성자는 자동으로 생성되지 않음)
public class HelloJob implements Job {
private String message;
// 매개변수가 있는 생성자만 정의
public HelloJob(String message) {
this.message = message;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// Job 비즈니스 로직
}
}쿼츠가 기본생성자를 찾지 못할 경우 다음과 같은 오류가 발생하게 된다.
즉, 기본생성자가 없어 JobFactory가 객체를 만들 수 없다는 의미이다.
org.quartz.SchedulerException: Problem instantiating class 'com.example.test.quartz.HelloJob'
at org.quartz.simpl.SimpleJobFactory.newJob(SimpleJobFactory.java:58)
at org.quartz.simpl.PropertySettingJobFactory.newJob(PropertySettingJobFactory.java:69)
at org.quartz.core.JobRunShell.initialize(JobRunShell.java:127)
at org.quartz.core.QuartzSchedulerThread.run(QuartzSchedulerThread.java:392)
Caused by: java.lang.InstantiationException: com.example.test.quartz.HelloJob
at java.base/java.lang.Class.newInstance(Class.java:639)
at org.quartz.simpl.SimpleJobFactory.newJob(SimpleJobFactory.java:56)
... 3 common frames omitted
Caused by: java.lang.NoSuchMethodException: com.example.test.quartz.HelloJob.<init>()
at java.base/java.lang.Class.getConstructor0(Class.java:3585)
at java.base/java.lang.Class.newInstance(Class.java:626)
... 4 common frames omitted이 경우 Job 객체 생성에 이용할 수 있도록 명시적으로 기본생성자를 추가해줄 수 있다.
public class HelloJob implements Job {
private String message;
// 기본생성자 추가
public HelloJob() {
}
// 매개변수가 있는 생성자만 정의
public HelloJob(String message) {
this.message = message;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// Job 비즈니스 로직
}
}JobDataMap
사실 위와 같이 Job 클래스 내부에는 인스턴스 변수(필드)에 상태 데이터를 저장하는 것은 의미가 없다.
각 실행마다 새로운 Job 객체가 생성되므로 이전 실행의 필드값이 유지되지 않기 때문이다.
그러면 Job 인스턴스에 추가적인 속성이 필요하다면 어떻게 해야 할까?
이때 JobDetail 객체의 속성 중 하나인 JobDataMap을 사용할 수 있다.
JobDataMap을 사용하면 잡이 실행될 때 사용할 데이터를 저장할 수 있다.
JobDataMap은 자바의 Map 인터페이스를 구현하였는데, 원시 타입의 값들을 쉽게 저장하고 불러올 수 있는 편의 기능의 메서드들이 추가되어 있다.
public class JobDataMap extends StringKeyDirtyFlagMap implements Serializable {
private static final long serialVersionUID = -6939901990106713909L;
public JobDataMap() {
super(15);
}
public JobDataMap(Map<?, ?> map) {
this();
Map<String, Object> mapTyped = map;
this.putAll(mapTyped);
this.clearDirtyFlag();
}
...
}다음은 Job을 스케줄러에 등록하기 전에, JobDetail을 정의/빌드하면서 JobDataMap에 데이터를 저장하는 코드의 예시이다.
JobDetail job = JobBuilder.newJob(HelloJob.class)
.withIdentity("myJob", "group1")
.usingJobData("current time", LocalTime.now().format(DateTimeFormatter.ofPattern("HH:mm:ss"))) // JobDataMap에 데이터 저장
.usingJobData("fav number", 8) // JobDataMap에 데이터 저장
.build();이렇게 저장한 데이터는 다음과 같이 Job 클래스의 execute() 메서드에서 가져와 쓸 수 있다.
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// JobDetail 출력
JobKey jobKey = jobExecutionContext.getJobDetail().getKey();
JobDataMap dataMap = jobExecutionContext.getJobDetail().getJobDataMap();;
System.out.println("[JobKey] " + jobKey + " / "
+ "[DataMap] current time: " + dataMap.getString("current time")
+ ", fav number: " + dataMap.getInt("fav number"));
// 비즈니스 로직
LocalTime now = LocalTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm:ss");
String formattedTime = now.format(formatter);
System.out.println("[" + formattedTime + "] executed");
}
}실행결과를 보면 DataMap의 속성값은 잡의 수행과 무관하게 계속 유지되는 것을 확인할 수 있다.
[JobKey] group1.myJob / [DataMap] current time: 21:14:54, fav number: 8
[21:14:54] executed
[JobKey] group1.myJob / [DataMap] current time: 21:14:54, fav number: 8
[21:14:58] executed
[JobKey] group1.myJob / [DataMap] current time: 21:14:54, fav number: 8
[21:15:02] executedJobStoreTX나 JobStoreCMT와 같이 Persistent JobStore를 사용할 경우, JobDataMap에 저장할 객체를 신중하게 선택해야 한다.
왜냐면 저장된 객체는 직렬화되어 저장되기 때문이다.
따라서 클래스 정의가 변경되면 직렬화된 데이터와의 버전 불일치 문제가 발생할 수 있다.
안전하게 데이터를 저장하는 방법은 Java의 표준 타입(원시 타입, String ...)을 사용하는 것이다.
사용자 정의 클래스를 저장하게 될 경우 필드를 추가하거나 삭제하여 클래스 정의가 변경되면 이전 버전과의 호환성이 깨질 위험이 있다는 것을 기억해야 한다.
이러한 직렬화 문제를 완전히 피하려면 JDBC-JobStore와 JobDataMap을 원시 타입과 String으로만 저장 가능한 모드로 설정할 수 있다.
JobDataMap에서 데이터 쉽게 가져오기
JobDataMap의 키 이름과 일치하는 setter를 Job 클래스에 추가하면 쿼츠의 기본 JobFactory가 자동으로 해당 setter 메서드를 호출하여 값을 설정한다.
이렇게하면 execute() 메서드 안에서 JobDataMap에서 직접 값을 꺼낼 필요 없이 필드를 통해 접근할 수 있다.
예시를 보면 msg라는 key로 데이터를 저장하였다.
JobDetail job = JobBuilder.newJob(HelloJob.class)
.withIdentity("myJob", "group1")
.usingJobData("msg", "hello") // JobDataMap에 데이터 저장
.build();그리고 Job 클래스에서 똑같은 이름의 필드를 정의하고, 이 필드에 해당하는 세터를 만들어주었다.
(세터 메서드를 명시하지 않고 클래스 레벨에 @Setter 어노테이션을 달아주어도 동일함)
public class HelloJob implements Job {
private String msg;
public void setMsg(String msg) {
this.msg = msg;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// JobDataMap 값 출력
System.out.println("msg: " + msg);
// 비즈니스 로직
LocalTime now = LocalTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm:ss");
String formattedTime = now.format(formatter);
System.out.println("[" + formattedTime + "] executed");
}
}이 방식도 앞의 방식과 동일하게 작동하는 것을 확인할 수 있다.
msg: hello
[21:39:10] executed
msg: hello
[21:39:14] executed
msg: hello
[21:39:18] executed또한 JobExecutionContext의 getMergedJobDataMap() 메서드를 이용해 가져올 수도 있다.
이는 JobDataMAp과 Trigger에 있는 JobDataMap을 병합한 형태이다.
동일한 key가 있다면 Trigger는 JobDetail의 값을 덮어쓴다.
Trigger에 JobDataMap 설정
잡에 JobDataMap을 사용한 것 처럼 트리거에도 JobDataMap을 설정할 수 있다.
이 기능은 하나의 잡이 여러 개의 트리거에 의해 반복적으로 실행될 때 유용하다.
즉, 각 트리거마다 서로 다른 데이터 값을 잡에 전달할 수 있다.
다음 예시를 살펴보면 JobDetail에서 JobData를 설정해주었고, Trigger에도 JobData를 설정해주었다.
JobDetail job = JobBuilder.newJob(HelloJob.class)
.withIdentity("myJob", "group1")
.usingJobData("msg", "hello") // JobDetail의 JobDataMap
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("myTrigger", "group1")
.usingJobData("msgFromTrigger", "hello from trigger") // Trigger의 JobDataMap
.startNow()
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(4)
.repeatForever()
)
.build(); 설정해준 JobData는 역시 execute() 메서드에서 JobExecutionContext로 부터 꺼내 쓸 수 있는데, JobDetail의 데이터는 getJobDetail() 메서드를, Trigger의 데이터는 getTrigger()의 메서드를 통해 가져올 수 있다.
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// JobDataMap 출력
JobDataMap dataMapFromJobDetail = jobExecutionContext.getJobDetail().getJobDataMap();
JobDataMap dataMapFromTrigger = jobExecutionContext.getTrigger().getJobDataMap();
System.out.println("msg: " + dataMapFromJobDetail.getString("msg")
+ ", msgFromTrigger: " + dataMapFromTrigger.getString("msgFromTrigger"));
// 비즈니스 로직
LocalTime now = LocalTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm:ss");
String formattedTime = now.format(formatter);
System.out.println("[" + formattedTime + "] executed");
}
}또한 setter 방식도 가능하다.
public class HelloJob implements Job {
private String msg; // JobDetail의 JobDataMap
private String msgFromTrigger; // Trigger의 JobDataMap
public void setMsg(String msg) {
this.msg = msg;
}
public void setMsgFromTrigger(String msgFromTrigger) {
this.msgFromTrigger = msgFromTrigger;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
// JobDataMap 값 출력
System.out.println("msg: " + msg + ", msgFromTrigger: " + msgFromTrigger);
// 비즈니스 로직
LocalTime now = LocalTime.now();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("HH:mm:ss");
String formattedTime = now.format(formatter);
System.out.println("[" + formattedTime + "] executed");
}
}로그는 두 방식 모두 동일하다.
msg: hello, msgFromTrigger: hello from trigger
[21:53:36] executed
msg: hello, msgFromTrigger: hello from trigger
[21:53:40] executed
msg: hello, msgFromTrigger: hello from trigger
[21:53:44] executedgetMergedJobDataMap()
JobDataMap에서 데이터를 가져오는 방식은 세가지가 있다.
2가지 방식은 앞서 살펴보았다.
각 JobDetail과 Trigger에 다음 JobData를 설정했다고 하자.
JobDetail -> usingJobData("msg", "jobDetailMsg")
Trigger -> usingJobData("msg", "TriggerMsg")첫번째는 JobDetail과 Trigger에서 각각 가져오는 방식이다.
이 방식은 같은 이름의 key로 JobData를 입력했다고 해도 각 JobDeatil과 Trigger의 데이터를 그대로 가져올 수 있다.
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
JobDataMap jobDetailDataMap = jobExecutionContext.getJobDetail().getJobDataMap();
JobDataMap triggerDataMap = jobExecutionContext.getTrigger().getJobDataMap();
System.out.println(jobDetailDataMap.getString("msg")); // jobDetailMsg
System.out.println(triggerDataMap.getString("msg")); // TriggerMsg
}
}두번째 방식은 setter를 이용하는 방식이었다.
이 경우 Trigger의 데이터가 JobDetail의 데이터를 덮어쓴다.
public class HelloJob implements Job {
private String msg;
public void setMsg(String msg) {
this.msg = msg;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println(msg); // TriggerMsg
}
}이제 세번째 방식을 알아보자.
이 방식은 첫번째 방식처럼 JobExecutionContext를 이용하는 방식이지만, getMergedJobDataMap() 메서드를 사용한다.
이 경우 또한 JobDetail에 설정된 JobDataMap과 Trigger에 설정된 JobDataMap을 병합한 것이다.
두번째 방식처럼 같은 키를 가진 값이 있을 경우 Trigger가 JobDetail의 JobDataMap 값을 덮어쓴다.
public class HelloJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
JobDataMap dataMap = jobExecutionContext.getMergedJobDataMap();
System.out.println(dataMap.getString("msg")); // TriggerMsg
}
}하나의 JobDetail로 여러 Trigger 실행
이 때 세터를 활용하는 방식은 JobDataMap의 key가 같다면 Trigger에 설정한 데이터가 JobDetail 데이터를 덮어쓴다.
왜 트리거의 JobDataMap이 우선 적용되는 것일까?
앞서 설명한대로 하나의 잡이 여러 트리거에서 실행될 수 있기 때문이다.
JobDetail의 JobDataMap은 기본값 역할을 하게 하고, 트리거에서 설정해주는 JobDataMap을 트리거마다 변경할 값 역할을 하게 할 경우 유용하다.
즉, 각 실행마다 다른 데이터를 잡에 전달할 수 있도록 하기 위해서이다.
예를 들어 이메일 알림 시스템을 생각해보자.
JobDetail에는 기본적인 메일 템플릿이 저장되고, 각 트리거마다 다른 사용자에게 이메일을 보내는 경우이다.
그때 JobDetail에는 기본값 역할로 "default@company.com"을 저장해두고, 트리거1이 실행될 때는 "user1@example.com"을 덮어쓰고, 트리거2가 실행될 때는 "user2@example.com"를 덮어쓸 수 있다.
즉, 같은 잡으로 다른 사용자에게 메일을 보낼 수 있다.
JobDetail job = JobBuilder.newJob(EmailJob.class)
.withIdentity("emailJob")
.usingJobData("email", "default@company.com") // 기본값
.build();
Trigger trigger1 = TriggerBuilder.newTrigger()
.withIdentity("trigger1")
.usingJobData("email", "user1@example.com") // 덮어쓰기 값
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule() // 5초마다 실행
.withIntervalInSeconds(5)
.repeatForever())
.forJob(job) // Job과 연결
.build();
Trigger trigger2 = TriggerBuilder.newTrigger()
.withIdentity("trigger2")
.usingJobData("email", "user2@example.com") // 덮어쓰기 값
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule() // 10초마다 실행
.withIntervalInSeconds(10)
.repeatForever())
.forJob(job) // Job과 연결
.build();
// 같은 Job을 여러 트리거로 실행
scheduler.scheduleJob(job, trigger1);
scheduler.scheduleJob(trigger2); // 트리거 정의 시 forJob(job)을 통한 잡과 트리거 연결 필수위 예제는 다음과 같은 결과를 가질 것이다.
- trigger1 실행 → "user1@example.com"으로 이메일 전송
- trigger2 실행 → "user2@example.com"으로 이메일 전송
이렇게 Job을 재사용하면서 실행마다 다른 동작을 하게 만들 수 있다.
하나의 Job으로 여러 개의 JobDetail 생성
하나의 Job 클래스를 생성하고, 여러 개의 JobDetail 인스턴스를 만들 수 있다.
이때 각 JobDetail마다 각기 다른 속성과 JobDataMap을 설정한 후 스케줄러에 추가해주면, 하나의 Job 클래스로 여러개의 JobDetail 객체가 생성된다.
예를 들어, Job 인터페이스를 구현한 SalesReportJob 클래스가 있다.
이 Job 클래스는 JobDataMap을 통해 전달된 매개변수를 기반으로 특정 영업 사원의 매출 보고서를 생성하도록 설계될 수 있다.
이렇게 SalesReportForJoe, SalesReportForMikde와 같아 JobDetail 인스턴스를 생성하고, 각 Job의 JobDataMap에 "Joe"와 "Mike"라는 값을 설정하여 각각의 작업에 입력 데이터로 활용할 수 있다.
트리거가 실행되면 해당 트리거와 연결된 JobDetail(인스턴스 정의)가 로드되고, 스케줄러에 설정된 JobFactory를 통해 해당 Job 클래스의 인스턴스가 생성된다.
기본 JobFactory는 Job 클래스의 newInstance()를 호출하고, JobDataMap 내 키 이름과 일치하는 setter 메서드를 찾아 호출한다.
다음은 하나의 Job 클래스로 여러 JobDetail을 만드는 예시이다.
이때, 쿼츠에서는 하나의 Trigger는 하나의 JobDetail만 가질 수 있기 때문에 각각의 JobDetail에 대해 별도의 Trigger를 함께 생성해줘야 한다.
public class QuartzTest {
public static void main(String[] args) {
try {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.start();
QuartzTest2 test = new QuartzTest2();
JobDetail salesReportForJoe = test.makeJobDetail("Joe");
JobDetail salesReportForMike = test.makeJobDetail("Mike");
Trigger triggerForJoe = test.makeTrigger("Joe", 4);
Trigger triggerForMike = test.makeTrigger("Mike", 5);
scheduler.scheduleJob(salesReportForJoe, triggerForJoe);
scheduler.scheduleJob(salesReportForMike, triggerForMike);
} catch (SchedulerException e) {
throw new RuntimeException(e);
}
}
private JobDetail makeJobDetail(String name) {
return JobBuilder.newJob(SalesReportJob.class)
.withIdentity("SalesReportFor" + name, "group1")
.usingJobData("name", name)
.build();
}
private Trigger makeTrigger(String name, int intervalSec) {
return TriggerBuilder.newTrigger()
.withIdentity("TriggerFor" + name, "group1")
.startNow()
.withSchedule(
SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(intervalSec)
.repeatForever()
)
.build();
}
}Job 클래스의 예시는 다음과 같다.
public class SalesReportJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
JobDataMap jobDetail = jobExecutionContext.getMergedJobDataMap();
System.out.println(jobDetail.getString("name") + "'s Report Executed");
}
}그러면 다음과 같이 출력되는 것을 확인할 수 있다.
Joe's Report Executed
Mike's Report Executed
Joe's Report Executed
Mike's Report Executed
Joe's Report Executed
Mike's Report Executed
Joe's Report ExecutedJobDetail마다 Trigger를 만드는 방식은 쿼츠의 기본적인 동작 방식이긴 하지만, 확장성이 떨어지지 않아 실무에서는 잘 쓰지 않는다.
대신 바로 직전에 살펴본 하나의 JobDetail로 여러 Trigger 실행하는 방식을 주로 사용한다.
다만 이 예제를 통해 JobDetail과 Trigger 간에 1:N 관계는 가능하지만, 반대로 N:1 관계는 가능하지 않다는 것을 이해할 수 있다.
즉, 하나의 JobDetail로 여러개의 Trigger를 사용할 수 있으나 하나의 Trigger로 여러개의 JobDetail을 사용할 수는 없다.
그러나 JobDataMap을 JobDetail에서 설정하면, 각각의 JobDetail이 고유한 데이터를 가질 수 있다.
반면, Trigger에서 JobDataMap을 설정하는 방식은 Job 실행 시 동적으로 데이터를 전달하는 방식이기 때문에, Job의 정의 자체만 공유되고 실행시마다 데이터만 다르게 주어지는 형태가 된다.
만약 Job이 특정한 초기 상태나 설정값을 유지해야 한다면(매 실행마다 변하지 않는 기본 설정이 필요하다면), 개별 JobDetail을 만들고, 각각 다른 Trigger를 사용하는 게 적합할 수 있다.
그렇다면 실무에서는 어떤 방식을 써야할까?
만약 각 Job이 독립적인 상태를 가져야 한다면 JobDetail마다 Trigger를 생성하는 방식(1:1)을 사용하는 것이 좋을 것이다.
만약 동일한 Job이 실행될 때 마다 다른 데이터를 받아야 한다면 JobDetail은 하나로 만들고 여러 Trigger를 생성하는 방식(1:n)을 사용하여 Trigger에서 JobDataMap을 설정하는 것이 좋다.
실제 프로젝트에서는 후자 방식이 더 유연하고 유지보수하기 쉽기 때문에 더 많이 사용한다.
쿼츠에서의 용어 정리
쿼츠에서 각각의 저장된 JobDetail을 Job Definition 또는 JobDetail Instance라고 부른다.
반면 실행 중인 Job은 Instance of a Job Definition 또는 Job Instance이라고 한다.
일반적으로 Job이라고 하면 JobDetail를 의미하며, Job 인터페이스를 구현한 클래스를 지칭할 때는 Job Class라는 용어를 사용한다.
JobExecutionException
잡 클래스의 execute 메서드에서 던질 수 있는 유일한 예외는 JobExecutionException이다.
execute 메서드 내부 로직을 try-catch 블록으로 감싸는 것이 일반적이다.
public class ErrorHandlingJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
try {
// 실행 코드
} catch (Exception e) {
throw new JobExecutionException(e);
}
}
}6. Simple Trigger
SimpleTrigger는 정확한 특정 시점에 한 번만 실행되거나, 특정 시점 이후 일정 간격으로 반복 실행되어야 하는 작업에 유용하다.
다음과 같은 경우 심플 트리거를 사용한다.
- 2025년 1월 13일 오전 11시 23분 54초에 한 번 실행
- 위 시점에 실행된 후 10초마다 5번 더 실행
1) SimpleTrigger 속성
SimpleTrigger의 주요 속성
start-time: 시작 시간end-time: 종료 시간, 옵션repeat-count: 반복 횟수repeat-interval: 반복 간격, 밀리초 단위
repeat count, repeat interval
repeat count에는 반복할 횟수를 정의하며, 0, 양의 정수, 무한반복 상수값이 될 수 있다.
0: 반복 없이 단 한 번만 실행양의 정수: 지정된 횟수만큼 반복 실행SimpleTrigger.REPEAT_INDEFINITELY: 무한 반복
repeat interval에는 반복할 간격을 정의하며, 0, 양의 정수가 될 수 있다.
0: 트리거가 가능한 한 동시에 여러 번 실행양의 정수: 지정된 간격으로 실행 (밀리초 단위)
이때 반복 간격을 0으로 설정하면 반복 횟수만큼 즉시 동시 실행될 수 있음에 주의해야 한다.
DateBuilder
특정 시간 기반으로 트리거를 설정해야 할 때 쿼츠의 DataBuilder 클래스를 활용하면 startTime과 endTime을 계산할 때 유용하다.
futureDate(int amount, IntervalUnit unit)
현재 시간 기준으로 지정된 시간 후의 날짜 반환
Date futureTime = DateBuilder.futureDate(10, IntervalUnit.MINUTE);
System.out.println("current time: " + new Date());
System.out.println("after 10 min: " + futureTime);current time: Sat Feb 08 20:03:10 KST 2025
after 10 min: Sat Feb 08 20:13:10 KST 2025dateOf(int hour, int minute, int second)
오늘 날짜 기준으로 특정 시각의 날짜 반환
Date todaySpecificTime = DateBuilder.dateOf(15, 30, 10);
System.out.println("current time: " + new Date());
System.out.println("today's specific time: " + todaySpecificTime);current time: Sat Feb 08 20:18:32 KST 2025
today's specific time: Sat Feb 08 15:30:10 KST 2025dateOf(int hour, int minute, int second, int day, int month, int year)
특정 날짜와 시각 반환
Date specificTime = DateBuilder.dateOf(15, 30, 15, 20, 5, 2025);
System.out.println("current time: " + new Date());
System.out.println("specific time: " + specificTime);current time: Sat Feb 08 20:25:32 KST 2025
specific time: Tue May 20 15:30:15 KST 2025evenHourDate(Date date)
지정된 날짜 이후 가장 가까운 정각(00:00) 반환
// null -> 현재 시간을 기준으로 다음 정각
Date nextHourTime = DateBuilder.evenHourDate(null);
// 현재 시간을 기준으로 다음 정각
Date nextHourTimeAfterNow = DateBuilder.evenHourDateAfterNow();
// 지정된 시간을 기준으로 다음 정각
Date nextHourTimeOfSpecificDate = DateBuilder.evenHourDate(DateBuilder.futureDate(10, IntervalUnit.DAY));
System.out.println("current time: " + new Date());
System.out.println("specific time: " + nextHourTime);
System.out.println("specific time: " + nextHourTimeAfterNow);
System.out.println("specific time: " + nextHourTimeOfSpecificDate);current time: Sat Feb 08 20:44:56 KST 2025
specific time: Sat Feb 08 21:00:00 KST 2025
specific time: Sat Feb 08 21:00:00 KST 2025
specific time: Tue Feb 18 21:00:00 KST 2025evenMinuteDate(Date date)
지정된 날짜 이후 가장 가까운 정각 분(00초) 반환
// null -> 현재 시간을 기준으로 다음 정각 분
Date nextEvenMinTime = DateBuilder.evenMinuteDate(null);
// 현재 시간을 기준으로 다음 정각 분
Date nextEvenMinTimeAfterNow = DateBuilder.evenMinuteDateAfterNow();
// 지정된 시간을 기준으로 다음 정각 분
Date nextEvenMinTimeOfSpecificDate = DateBuilder.evenMinuteDate(DateBuilder.futureDate(10, IntervalUnit.DAY));
System.out.println("current time: " + new Date());
System.out.println("specific time: " + nextEvenMinTime);
System.out.println("specific time: " + nextEvenMinTimeAfterNow);
System.out.println("specific time: " + nextEvenMinTimeOfSpecificDate);current time: Sat Feb 08 20:46:59 KST 2025
specific time: Sat Feb 08 20:47:00 KST 2025
specific time: Sat Feb 08 20:47:00 KST 2025
specific time: Tue Feb 18 20:47:00 KST 2025이 외에도 많은 유용한 메서드들을 가지고 있다.
DateBuilder를 사용했음을 표시하기 위해 DateBuilder 클래스를 명시했으나, 모두 static 메서드 이므로 static import하여 DateBuilder 클래스를 명시하지 않고 메서드 자체로 사용하는 것이 좋다.
import static org.quartz.DateBuilder.*;end-time이 repeat-count를 우선한다
end-time 속성이 설정되어 있을 경우, end-time 속성은 repeat-count보다 우선된다.
예를 들어 특정 시간까지 10초마다 반복할 트리거를 생성할 경우 유용하다.
이 경우 반복 횟수를 계산할 필요 없이 end-time을 지정하고, 단순히 repeat-count를 REPEAT_INDEFINITELY(무한반복)으로 설정하면 된다.
그러므로 특정 종료 시점까지만 실행하고 싶다면 repeat-count 대신 end-time을 설정하는 것이 좋다.
2) SimpleTrigger 생성
SimpleTrigger는 TriggerBuilder 또는 SimpleScheduleBuilder를 통해 생성할 수 있다.
TriggerBuilder: 트리거의 주요 속성 설정SimpleScheduleBuilder: SimpleTrigger에 특화된 속성 설정
DSL 스타일로 사용하려면 static import를 사용할 수 있다.
import static org.quartz.TriggerBuilder.*;
import static org.quartz.SimpleScheduleBuilder.*;
import static org.quartz.DateBuilder.*:심플 트리거에 대한 여러 예시들을 살펴보자.
예시들에서 사용할 Job 클래스는 단순 실행 시간을 출력하는 로직으로, 다음과 같다.
public class TriggerTestJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("executed time: " + new Date());
}
}즉시 시작, 반복 없음
System.out.println("current time: " + new Date());
SimpleTrigger trigger = (SimpleTrigger) TriggerBuilder
.newTrigger()
.withIdentity("myTrigger", "group1")
.startNow() // 실행 시점
.build();9시 9분 13초에 등록된 트리거는 실제로 같은 시간에 실행되었다.
current time: Sat Feb 08 21:09:13 KST 2025
executed time: Sat Feb 08 21:09:13 KST 2025사실 즉시 시작은 startNow() 조차 필요하지 않고, 실행 시점이 정의되어 있지 않으면 기본으로 즉시 시작한다.
특정 시간 시작, 반복 없음
System.out.println("current time: " + new Date());
Date nextEvenMinTimeAfterNow = DateBuilder.evenMinuteDateAfterNow();
SimpleTrigger trigger = (SimpleTrigger) TriggerBuilder
.newTrigger()
.withIdentity("myTrigger", "group1")
.startAt(nextEvenMinTimeAfterNow) // 실행 시점
.build();9시 2분 21초에 등록된 트리거는 실제로 3분 00초에 실행되었고, 시간이 흘러 4분 00초가 되어도 더이상 실행되지 않았다.
current time: Sat Feb 08 21:02:21 KST 2025
executed time: Sat Feb 08 21:03:00 KST 2025특정 시간 시작, 3초마다 3번 반복
System.out.println("current time: " + new Date());
Date nextEvenMinTimeAfterNow = DateBuilder.evenMinuteDateAfterNow();
SimpleTrigger trigger = (SimpleTrigger) TriggerBuilder
.newTrigger()
.withIdentity("myTrigger", "group1")
.startAt(nextEvenMinTimeAfterNow) // 실행 시점
.withSchedule(
SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(3) // 반복 간격
.withRepeatCount(3)) // 반복 횟수
.build();9시 12분 39초에 등록된 트리거는 실제로 13분 00초에 실행되었고, 3초 간격으로 반복 실행되어 총 4번(초기 실행 + 3회 반복) 실행되었다.
current time: Sat Feb 08 21:12:39 KST 2025
executed time: Sat Feb 08 21:13:00 KST 2025
executed time: Sat Feb 08 21:13:03 KST 2025
executed time: Sat Feb 08 21:13:06 KST 2025
executed time: Sat Feb 08 21:13:09 KST 202530초 후 시작, 반복 없음
System.out.println("current time: " + new Date());
Date futureTime = DateBuilder.futureDate(30, IntervalUnit.SECOND);
SimpleTrigger trigger = (SimpleTrigger) TriggerBuilder
.newTrigger()
.withIdentity("myTrigger", "group1")
.startAt(futureTime) // 실행 시점
.build();9시 19분 41초에 등록된 트리거는 실제로 30초 후인 20분 11초에 실행되었다.
current time: Sat Feb 08 21:19:41 KST 2025
executed time: Sat Feb 08 21:20:11 KST 2025즉시 시작, 10초마다 반복, 특정 시간까지
SimpleTrigger trigger = (SimpleTrigger) TriggerBuilder
.newTrigger()
.withIdentity("myTrigger", "group1")
.withSchedule(
SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(10) // 반복 간격
.repeatForever() // 반복 횟수
)
.endAt(dateOf(21, 28, 0))
.build();9시 27분 28초에 등록된 트리거는 즉시 실행되어 10초마다 9시 28분 0초가 되기 전까지 반복 실행되었다.
current time: Sat Feb 08 21:27:28 KST 2025
executed time: Sat Feb 08 21:27:28 KST 2025
executed time: Sat Feb 08 21:27:38 KST 2025
executed time: Sat Feb 08 21:27:48 KST 2025
executed time: Sat Feb 08 21:27:58 KST 2025특정 시간 시작, 10초마다 반복, 무한 반복
System.out.println("current time: " + new Date());
Date futureTime = DateBuilder.futureDate(30, IntervalUnit.SECOND);
SimpleTrigger trigger = (SimpleTrigger) TriggerBuilder
.newTrigger()
.withIdentity("myTrigger", "group1")
.startAt(futureTime)
.withSchedule(
SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(10) // 반복 간격
.repeatForever() // 반복 횟수
)
.build();9시 33분 22초에 등록된 트리거는 실제로 30초 후인 33분 52초에 실행되었고, 10초 간격으로 무한으로 반복 실행되었다.
current time: Sat Feb 08 21:33:22 KST 2025
executed time: Sat Feb 08 21:33:52 KST 2025
executed time: Sat Feb 08 21:34:02 KST 2025
executed time: Sat Feb 08 21:34:12 KST 2025
(...무한 반복) 3) SimpleTrigger 기본 동작
SimpleTrigger trigger = (SimpleTrigger) TriggerBuilder
.newTrigger()
.build();
scheduler.start();
scheduler.scheduleJob(job, trigger);TriggerBuiler(혹은 쿼츠의 다른 트리거 빌더들)은 기본적으로 위 코드로만으로도 동작한다.
withIdentity()를 호출하지 않으면 랜덤한 트리거 이름이 자동 생성된다.
startAt() 또는 startNow() 메소드를 통한 실행시점을 지정하지 않으면 기본값으로 즉시 실행된다.
4) SimpleTrigger Misfire 정책
예약된 트리거 실행 시간이 지나고도 트리거가 실행되지 않을 경우 Misfire(불발)되었다고 한다.
Misfire가 발생하는 주요 원인은 다음과 같다.
스케줄러가 과부하 상태
쿼츠는 Thread Pool을 사용하여 잡을 실행하는데, 트리거 실행 시간이 되었으나 모든 쓰레드가 작동중이면 트리거 실행이 지연될 수 있다.
이런 경우 쓰레드 풀 크기를 증가(org.quartz.threadPool.threadCount) 시키거나, 잡 실행 시간을 최적화하여 불필요한 지연을 줄일 수 있다.
스케줄러가 장시간 정지(shutdown)
또한 shutdown() 호출로 인해 쿼츠가 종료되었거나, 서버 다운과 같이 시스템이 종료되는 경우, DB 연결이 끊기는 경우와 같이 스케줄러가 장시간 정지되는 경우가 있다.
이 경우 쿼츠를 클러스터 모드로 설정하여 다른 인스턴스가 잡을 실행할 수 있도록 하는 방법이 있다.
또한 스케줄러 재시작 시, 불발된 트리거에 대한 Misfire 정책을 설정해둬야 한다.
Job 실행 시간이 너무 길 때
잡 실행 시간이 너무 오래 걸리면 다음 예약된 트리거 실행 시간까지 잡이 끝나지 못할 수 있고, 다음 트리거의 실행 시간이 지나면서 Misfire 상태가 된다.
이 경우 DB 쿼리 최적화나 비효율적인 로직 개선을 통한 잡 실행시간을 최적화하고, org.quartz.jobStore.misfireThreshold 값을 조정하여 Misfire 감지 시간을 늘릴 필요가 있다.
Misfire Threadhold 설정값이 너무 낮음
쿼츠에는 Misfire 상태를 감지하는 Misfire Threshold(임계값)이 있다.
기본값은 6000ms(60초)이며, 이 시간 이상이 지연되면 Misfire로 간주된다.
너무 짧게 설정하면 불필요한 Misfire가 발생할 수 있으므로, org.quartz.jobStore.misfireThreshold 값을 기본값(60초) 이상으로 설정하는 방법이 있다.
quartz.properties
org.quartz.jobStore.misfireThreshold = 120000이런 Misfired Trigger에 대해 다음과 같은 정책을 제공한다.
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
MISFIRE_INSTRUCTION_FIRE_NOW
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT
MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT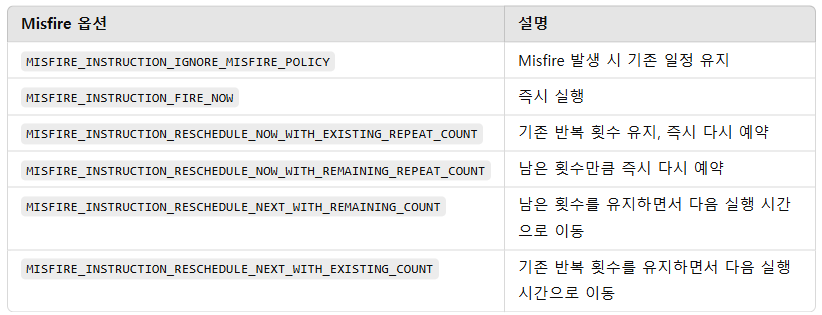
기본값으로는 Trigger.Trigger.MISFIRE_INSTRUCTION_SMART_POLICY가 사용되며, 트리거 설정과 트리거 객체의 상태에 따라 적절한 옵션이 자동 선택된다.
Misfire 정책은 스케줄 정의 시 다음과 같이 설정할 수 있다.
trigger = newTrigger()
.withIdentity("trigger7", "group1")
.withSchedule(simpleSchedule()
.withIntervalInMinutes(5)
.repeatForever()
.withMisfireHandlingInstructionNextWithExistingCount()) // Misfire 발생 시 기존 반복 횟수를 유지하면서 다음 실행 시간으로 이동
.build();7. Cron Trigger
SimpleTrigger는 간격에 따라 반복해야 할 경우 유용하지만, CronTrigger는 캘린더 기반의 스케줄의 경우 유용하다.
CronTrigger를 사용하면 다음과 같은 스케줄 예약을 설정할 수 있다.
- 매주 금요일 정오
- 매주 평일 오전 9시 30분
- 1월의 매주 월, 수, 금 오전 9시부터 10시까지 5분마다
1) CronTrigger 속성
SimpleTrigger와 마찬가지로 CronTrigger 역시 start-time과 end-time을 가진다.
start-time: 일정이 언제부터 활성화될지 지정end-time: 일정이 언제 종료될지 지정
2) CRON 표현식
크론 표현식은 CronTrigger의 동작을 설정하는 데 사용된다.
이 표현식은 7개의 서브 표현식으로 구성되며, 각 항목은 공백(space)로 구분된다.
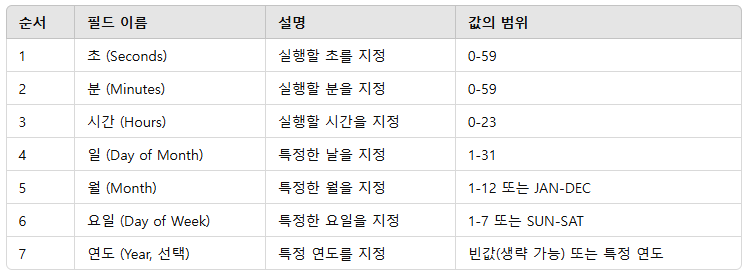
초 분 시간 일 월 요일 (연도)
0 0 12 ? * WED이 표현식은 매주 수요일(WED) 정오(12:00:00 PM)에 실행됨을 의미한다.
예제를 통해 더 자세히 알아보도록 하자.
-(Range) ,(List)
각 필드는 범위 또는 리스트 형식으로 값을 지정할 수 있다.
MON-FRI-> 월~금MON,WED,FRI-> 월, 수, 금MON-WED,SAT-> 월~수, 토
* : 모든 값
가능한 모든 필드의 값으로 모든 값을 의미하는 와일드카드 *을 사용할 수 있다.
* (Month 필드)-> 모든 달* (Day-Of-Week 필드)-> 모든 요일
/ : 시작/반복
슬래시 /는 특정 값에서 시작하여 주기적으로 반복 실행할 때 사용한다.
0/15 (Minutes 필드)-> 매시간 0분부터 시작해서 15분마다 실행 (예: 00, 15, 30, 45)3/20 (Minutes 필드)-> 3분부터 시작해서 20분마다 실행 (예: 03, 23, 43)/35-> "매 35분마다"가 아니라 "매시간 0분과 35분에 실행"
? : 값을 지정하지 않음
물음표 ?는 Day-of-Month(날짜) 또는 Day-of-Week(요일) 필드에서 사용 가능하며, 특정 값을 지정하지 않음을 의미한다.
0 0 12 ? * WED-> 매주 수요일 정오(12:00:00)에 실행 (날짜 필드는 ?로 설정)0 30 10 15 * ?-> 매월 15일 오전 10:30에 실행 (요일 필드는 ?로 설정)
L : 마지막
L은 Last(마지막)를 의미하며, Day-of-Month(날짜)와 Day-of-Week(요일) 필드에서 다르게 동작한다.
0 0 12 L * ?-> 매월 마지막 날 정오(12:00:00)에 실행0 0 12 ? * 6L또는0 0 12 ? * FRIL-> 매월 마지막 금요일 정오에 실행0 0 12 L-3 * ?-> 매월 마지막에서 세 번째 날 정오에 실행
이때 L을 범위 또는 리스트와 함께 사용하면 예상치 못한 동작이 발생할 수 있으므로 주의하자.
W : 가장 가까운 평일
W는 WeekDay를 의미하며, 지정한 날짜에서 가장 가까운 평일(월~금)로 이동한다.
0 0 9 15W * ?-> 매월 15일에서 가장 가까운 평일 오전 9시에 실행
예를 들어, 15일이 토요일이면 14일(금요일)에 실행하고, 15일이 일요일이면 16일(월요일)에 실행한다.
# : 특정 요일 지정
#은 해당 월의 N번째 요일을 지정할 때 사용한다.
0 0 12 ? * 6#3또는0 0 12 ? * FRI#3-> 매월 세 번째 금요일 정오에 실행0 30 8 ? * MON#1-> 매월 첫 번째 월요일 오전 8:30에 실행
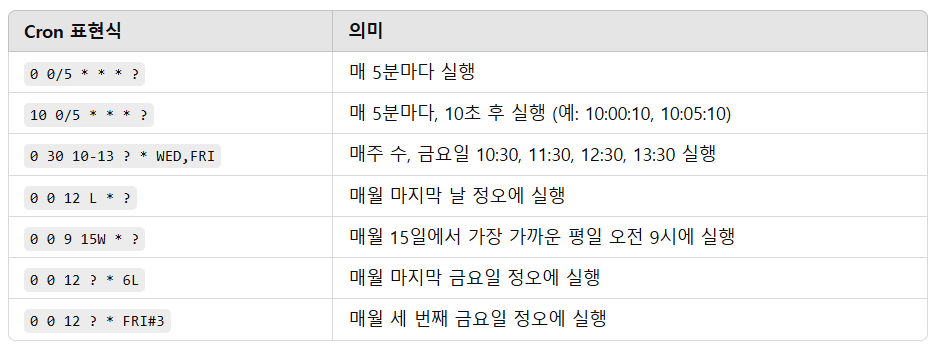
다음은 더 많은 예제이다.
0 0/5 * * * ?- 매 5분마다 실행되는 트리거
- 초(0) → 0분부터 5분 간격으로 실행
- 예: 00:00, 00:05, 00:10, ..., 23:55
10 0/5 * * * ?- 매 5분마다 실행되지만, 10초 후 실행
- 초(10) → 분이 0, 5, 10, 15...일 때, 10초 후 실행
- 예: 10:00:10, 10:05:10, 10:10:10, ...
0 30 10-13 ? * WED,FRI- 매주 수요일(WED)과 금요일(FRI) 실행
- 시간(10-13) → 10:30, 11:30, 12:30, 13:30 실행
- 예: 수요일과 금요일의 10:30, 11:30, 12:30, 13:30
0 0/30 8-9 5,20 * ?- 매월 5일과 20일, 오전 8시~9시 사이 30분마다 실행되는 트리거
- 매월 5일과 20일 실행
- 시간(8-9) → 8시부터 9시까지 실행 (10시는 포함되지 않음)
- 30분 간격 실행
- 예: 08:00, 08:30, 09:00, 09:30
첫 번째 트리거: 0 0/5 9-10 * * ? → 9시~10시 사이 5분마다 실행
두 번째 트리거: 0 0/20 13-22 * * ? → 13시~22시 사이 20분마다 실행 - 단일 트리거로 표현하기 어려운 일정
- 두 개의 트리거를 생성하여 같은 작업에 등록
3) CronTrigger 생성
이제 CronTrigger를 생성해보자.
SimpleTrigger 예제와 마찬가지로 Job 클래스에서는 단순 실행시간을 출력할 것이다.
public class TriggerTestJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("executed time: " + new Date());
}
}CRON 표현식 사용
다음은 매일 20시 40분 0초에 실행되는 트리거이다.
이 경우 CronScheduleBuilder의 cronSchedule()을 사용해 크론 표현식을 직접 정의하였다.
System.out.println("current time: " + new Date());
CronTrigger trigger = (CronTrigger) TriggerBuilder
.newTrigger()
.withIdentity("myTrigger", "group1")
.withSchedule(
CronScheduleBuilder
.cronSchedule("0 40 20 * * ?")
)
.build();기타 메서드 사용
같은 내용의 트리거를 CronScheduleBuilder에서 제공하는 dailyAtHourAndMinute() 메서드를 사용하여 간단히 표현할 수 있다.
또한 weeklyOnDayAndHourAndMinute() 등 다양한 메서드를 제공한다.
System.out.println("current time: " + new Date());
CronTrigger trigger = (CronTrigger) TriggerBuilder
.newTrigger()
.withIdentity("myTrigger2", "group1")
.withSchedule(
CronScheduleBuilder
.dailyAtHourAndMinute(20, 40)
)
.build();결과는 두가지 방법 모두 동일하다.
current time: Mon Feb 10 20:39:12 KST 2025
executed time: Mon Feb 10 20:40:00 KST 2025
(...매일 반복)4) CronTrigger Misfire 정책
CronTrigger 역시 다음과 같이 Misfire 정책을 설정할 수 있다.
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY
MISFIRE_INSTRUCTION_DO_NOTHING
MISFIRE_INSTRUCTION_FIRE_NOW
기본값은 MISFIRE_INSTRUCTION_FIRE_NOW 이며, Misfire 발생 시 즉시 실행된다.
Misfire 정책은 스케줄 정의 시 다음과 같이 설정할 수 있다.
trigger = newTrigger()
.withIdentity("trigger3", "group1")
.withSchedule(cronSchedule("0 0/2 8-17 * * ?")
.withMisfireHandlingInstructionFireAndProceed()) // Misfire 발생 시 즉시 실행 후 다음 일정 진행
.forJob("myJob", "group1")
.build();8. Job Stores
JobStore는 스케줄러에 제공한 모든 작업 데이터(잡, 트리거, 캘린더 등)를 저장하고 곤리하는 역할을 하며, 쿼츠는 이를 기반으로 스케줄링을 수행한다.
적절한 JobStore를 선택하는 것은 쿼츠 스케줄러 인스턴스 설정에서 중요한 단계이다.
이제 각 JobStore에 대한 차이를 이해해보자.
1) JobStore 설정
쿼츠 스케줄러 설정 시 어떤 JobStore를 사용할지 지정해야 한다.
JobStore를 설정하는 방법은 두 가지가 있는데, JDBCJobStore를 사용한다는 가정 하에 예시 코드를 살펴보자.
속성파일
quartz.properties와 같은 별도의 설정 파일에서 정의하는 방식이다.
quartz.properties
org.quartz.scheduler.instanceName = MyScheduler
org.quartz.scheduler.instanceId = AUTO
# JDBCJobStore 사용
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.tablePrefix = QRTZ_
org.quartz.jobStore.dataSource = myDS
# 데이터베이스 연결 설정
org.quartz.dataSource.myDS.driver = com.mysql.cj.jdbc.Driver
org.quartz.dataSource.myDS.URL = jdbc:mysql://localhost:3306/quartz
org.quartz.dataSource.myDS.user = root
org.quartz.dataSource.myDS.password = password
org.quartz.dataSource.myDS.maxConnections = 5
# 스레드 풀 설정
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 5
org.quartz.threadPool.threadPriority = 5코드에서 직접 설정
코드 상에서 SchedulerFactory 객체를 생성하면서 설정하는 방식이다.
JobStore 인스턴스를 코드에서 직접 사용할 수 없다.
JobStore는 쿼츠 자체의 내부 용도로만 사용된다.
어떤 JobStore를 사용할 지 설정한 이후에는 코드에서 Scheduler 인터페이스만 사용해야 한다.
// Quartz 설정을 위한 Properties 객체 생성
Properties props = new Properties();
props.setProperty("org.quartz.scheduler.instanceName", "MyScheduler");
props.setProperty("org.quartz.scheduler.instanceId", "AUTO");
// JDBCJobStore 설정
props.setProperty("org.quartz.jobStore.class", "org.quartz.impl.jdbcjobstore.JobStoreTX");
props.setProperty("org.quartz.jobStore.driverDelegateClass", "org.quartz.impl.jdbcjobstore.StdJDBCDelegate");
props.setProperty("org.quartz.jobStore.tablePrefix", "QRTZ_");
props.setProperty("org.quartz.jobStore.dataSource", "myDS");
// 데이터베이스 연결 설정
props.setProperty("org.quartz.dataSource.myDS.driver", "com.mysql.cj.jdbc.Driver");
props.setProperty("org.quartz.dataSource.myDS.URL", "jdbc:mysql://localhost:3306/quartz");
props.setProperty("org.quartz.dataSource.myDS.user", "root");
props.setProperty("org.quartz.dataSource.myDS.password", "password");
props.setProperty("org.quartz.dataSource.myDS.maxConnections", "5");
// 스레드 풀 설정
props.setProperty("org.quartz.threadPool.class", "org.quartz.simpl.SimpleThreadPool");
props.setProperty("org.quartz.threadPool.threadCount", "5");
props.setProperty("org.quartz.threadPool.threadPriority", "5");
// SchedulerFactory 생성 및 설정 적용
StdSchedulerFactory schedulerFactory = new StdSchedulerFactory();
schedulerFactory.initialize(props);
// Scheduler 시작
Scheduler scheduler = schedulerFactory.getScheduler();
scheduler.start();2) RamJobStore
RAMJobStore는 가장 사용하기 간단한 JobStore이며, 또한 가장 뛰어난 성능(CPU 시간 기준)을 제공한다.
RAMJobStore는 이름 그대로 모든 데이터를 RAM에 저장한다. 그래서 매우 빠르고, 설정도 간단하다.
단점은 애플리케이션이 종료되거나 충돌하면 모든 스케줄링 정보가 손실된다는 것이다.
이는 RAMJobStore가 작업과 트리거의 "비휘발성" 설정을 보존할 수 없음을 의미한다.
RAMJobStore를 사용하려면(StdSchedulerFactory를 사용하는 경우) 다음과 같이 Quartz 설정에서 JobStore 클래스 속성으로 클래스 이름 org.quartz.simpl.RAMJobStore를 지정하기만 하면 된다.
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore3) JDBCJobStore
JDBCJobStore는 이름 그대로 데이터를 JDBC를 통해 데이터베이스에 저장한다.
이 때문에 RAMJobStore보다 설정이 다소 복잡하며 속도도 빠르지 않다.
그러나 성능 저하는 심각한 수준은 아니며, 특히 기본 키(primary key)에 인덱스를 추가하면 속도가 개선될 수 있다.
현대적인 서버 환경과 적절한 LAN 연결(스케줄러와 데이터베이스 간 네트워크)이 갖춰진 경우, 트리거를 조회 및 갱신하는 데 걸리는 시간은 일반적으로 10밀리초 미만이다.
JdbcJobStore의 JobStoreTX를 사용하는 경우의 quartz.properties 설정이다.
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX다음은 JdbcJobStore의 JobStoreCMT를 사용하는 경우의 설정이다.
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreCMT쿼츠 테이블
JDBCJobStore는 거의 모든 데이터베이스에서 작동하며, 대표적으로 Oracle, PostgreSQL, MySQL, MS SQLServer, HSQLDB, DB2에서 널리 사용된다.
JDBCJobStore를 사용하려면 먼저 Quartz에서 사용할 데이터베이스 테이블을 생성해야 한다.
Quartz 배포판의 "docs/dbTables" 디렉터리에서 테이블 생성 SQL 스크립트를 찾을 수 있다.
오라클 sql 쿼리를 다음 포스팅에 올려두었다.
이 스크립트에서는 모든 테이블이 “QRTZ_” 접두어를 사용한다(예: “QRTZ_TRIGGERS”, “QRTZ_JOB_DETAIL”).
이 접두어는 원하는 값으로 변경할 수 있지만, Quartz 설정에서 JDBCJobStore에 해당 접두어를 알려야 한다.
다른 접두어를 사용하면 동일한 데이터베이스에서 여러 개의 스케줄러 인스턴스를 운영할 때 유용할 수 있다.
다음은 각 테이블에 대한 설명이다.
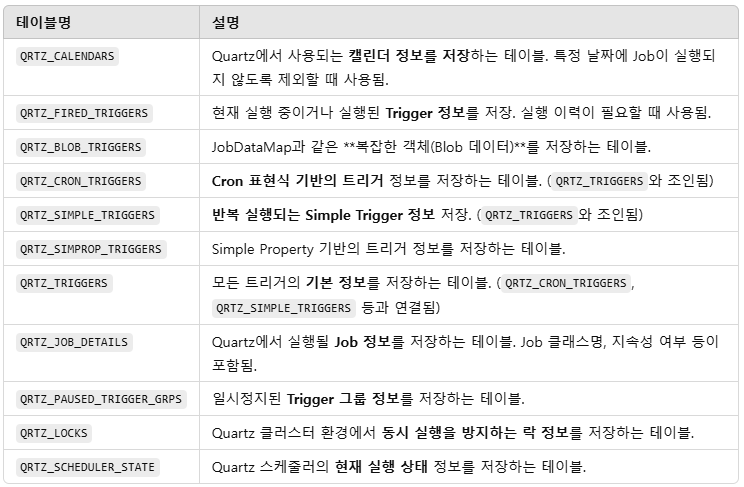
QRTZ_TRIGGERS→ 모든 트리거의 기본 정보 저장QRTZ_JOB_DETAILS→ 실행될 Job 정보 저장QRTZ_CRON_TRIGGERS,QRTZ_SIMPLE_TRIGGERS→ 트리거 타입별 세부 정보 저장QRTZ_FIRED_TRIGGERS→ 실행된 트리거 이력 저장QRTZ_LOCKS,QRTZ_SCHEDULER_STATE→ 클러스터 동기화 및 상태 관리
트랜잭션 관리
테이블을 생성한 후, JDBCJobStore를 설정하고 실행하기 전에 중요한 결정을 하나 더 내려야 한다.
바로 어플리케이션에서 필요한 트랜잭션 유형을 결정하는 것이다.
JDBCJobStore에는 JobStoreTX와 JobStoreCMT가 있다 . 데이터베이스에 정보를 저장한다는 점에서는 동일하지만, 트랜잭션을 관리하는 방법이 다르다.
트리거 추가 및 삭제와 같은 스케줄링 명령을 다른 트랜잭션과 연계할 필요가 없다면, Quartz가 직접 트랜잭션을 관리하도록 JobStoreTX를 선택하면 된다.
JobStoreTX를 선택하는 것이 일반적이다.
Quartz가 다른 트랜잭션과 함께 작동해야 하는 경우(J2EE 애플리케이션 서버 내에서), JobStoreCMT를 사용해야 하며, 이 경우 Quartz는 애플리케이션 서버 컨테이너가 트랜잭션을 관리하도록 한다.
DataSource 설정
마지막으로, JDBCJobStore가 데이터베이스와 연결할 수 있도록 DataSource를 설정해야 한다.
DataSource와 관련해서는 다음과 같은 속성들이 있다.
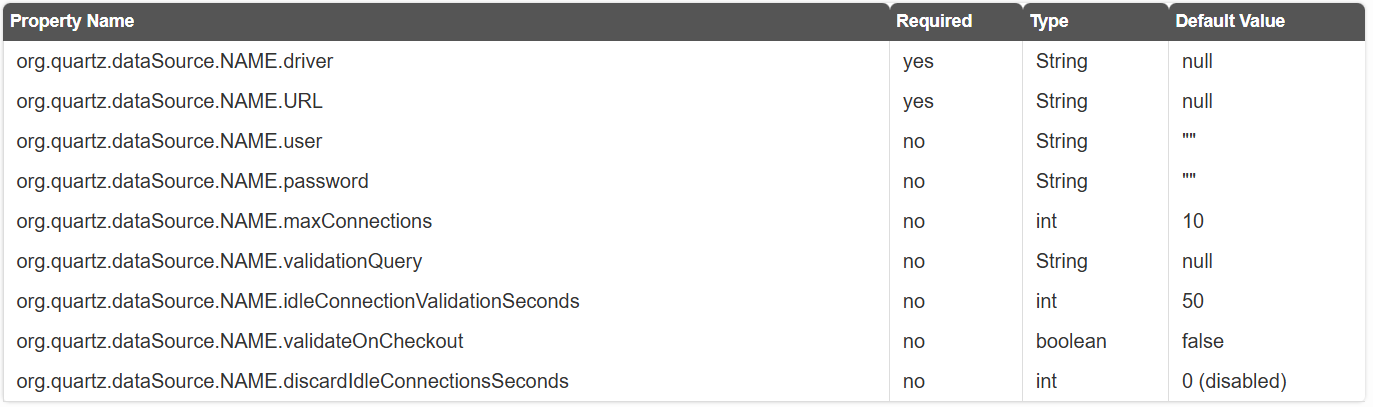
org.quartz.dataSource.NAME.driver: 데이터베이스의 JDBC 드라이버에 대한 자바 클래스 이름org.quartz.dataSource.NAME.URL: 데이터베이스에 연결하기 위한 연결 URL(호스트, 포트 등)org.quartz.dataSource.NAME.user: 데이터베이스에 연결할 때 사용할 사용자 이름org.quartz.dataSource.NAME.password: 데이터베이스에 연결할 때 사용할 비밀번호org.quartz.dataSource.NAME.maxConnections:- ``: DataSource가 생성할 수 있는 최대 연결 수
org.quartz.dataSource.NAME.validationQuery: DataSource가 실패한 연결을 감지하고 교체하는 데 사용할 수 있는 선택적 SQL 쿼리 문자열org.quartz.dataSource.NAME.idleConnectionValidationSeconds: 유휴 연결을 테스트하는 시간 간격(초). validationQuery 속성이 설정된 경우에만 활성화. 기본값은 50초org.quartz.dataSource.NAME.validateOnCheckout: 연결 풀에서 연결을 가져올 때마다 연결이 여전히 유효한지 확인하기 위해 데이터베이스 SQL 쿼리가 실행될지 여부. 기본값은 false(연결이 체크인될 때 검증 수행)org.quartz.dataSource.NAME.discardIdleConnectionsSeconds: 연결이 유휴 상태로 이 시간(초) 동안 지속되면 해당 연결을 폐기. 기본값은 0(이 기능 비활성화)
다음은 DataSource 설정 예시이다.
org.quartz.dataSource.myDS.driver = oracle.jdbc.driver.OracleDriver
org.quartz.dataSource.myDS.URL = jdbc:oracle:thin:@10.0.1.23:1521:demodb
org.quartz.dataSource.myDS.user = myUser
org.quartz.dataSource.myDS.password = myPassword
org.quartz.dataSource.myDS.maxConnections = 30JobStoreTX 설정
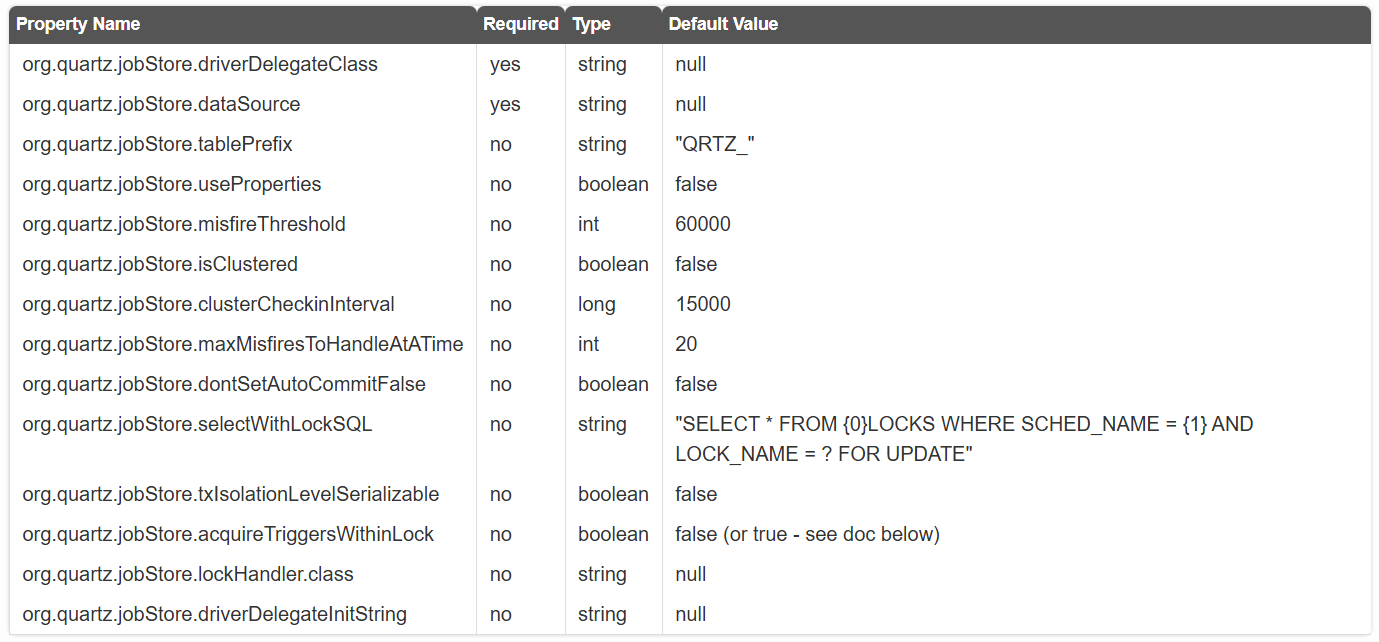
org.quartz.jobStore.driverDelegateClass: 사용하려는 데이터베이스에 맞는 Driver Delegate 클래스 설정 (예: org.quartz.impl.jdbcjobstore.oracle.OracleDelegate)org.quartz.jobStore.dataSource: 사용할 DataSource 이름 지정 (quartz.properties에 정의된 데이터소스 참조)org.quartz.jobStore.tablePrefix: Quartz 테이블의 접두어(Prefix) 설정 (여러 개의 Quartz 인스턴스를 동일한 DB에서 사용 가능)org.quartz.jobStore.useProperties: JobDataMap을 String으로 저장할지 여부 (true이면 BLOB이 아닌 Key-Value 형태로 저장됨)org.quartz.jobStore.misfireThreshold: Trigger의 Misfire 허용 시간(ms) (기본값: 60초)org.quartz.jobStore.isClustered: 클러스터링 활성화 여부 (true로 설정하면 여러 인스턴스가 같은 DB를 공유)org.quartz.jobStore.clusterCheckinInterval: 클러스터 모드에서 인스턴스 간 체크 주기(ms)org.quartz.jobStore.maxMisfiresToHandleAtATime: 한 번에 처리할 최대 Misfire 트리거 개수org.quartz.jobStore.dontSetAutoCommitFalse: setAutoCommit(false) 호출 여부 (true로 설정하면 호출하지 않음)org.quartz.jobStore.selectWithLockSQL: Lock을 위한 SQL 문 (DB별로 커스텀 가능)org.quartz.jobStore.txIsolationLevelSerializable: 트랜잭션 격리 수준을 SERIALIZABLE로 설정할지 여부org.quartz.jobStore.acquireTriggersWithinLock: 트리거 획득 시 잠금(Lock)을 사용할지 여부org.quartz.jobStore.lockHandler.class: Locking을 위한 세마포어 클래스 지정 (고급 설정)org.quartz.jobStore.driverDelegateInitString: DriverDelegate 초기화 시 전달할 설정 값
Driver Delegate 클래스 목록
다음은 org.quartz.jobStore.driverDelegateClass 속성에 설정할 수 있는 클래스 목록이다.
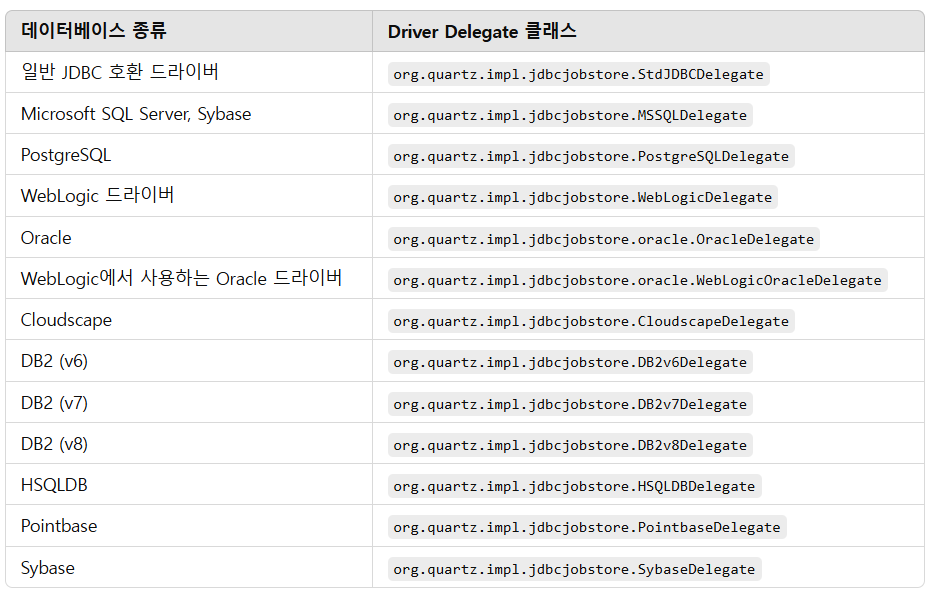
일반 JDBC 호환 데이터베이스는 StdJDBCDelegate 클래스를 사용하여 여러 데이터베이스에서 호환 가능하도록 처리된다.
그와 달리 Oracle 드라이버는 다른 데이터베이스 드라이버와는 다르게 특별한 처리가 필요할 수 있어서, OracleDelegate 클래스를 사용해야 한다.
# Quartz 기본 설정
org.quartz.scheduler.instanceName = MyScheduler
org.quartz.scheduler.instanceId = AUTO
# JobStore 설정 (JDBCJobStoreTX 사용)
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.oracle.OracleDelegate
org.quartz.jobStore.tablePrefix = QRTZ_
org.quartz.jobStore.dataSource = myDS
org.quartz.jobStore.isClustered = false
# 데이터 소스 설정 (Oracle)
org.quartz.dataSource.myDS.driver = oracle.jdbc.OracleDriver
org.quartz.dataSource.myDS.URL = jdbc:oracle:thin:@localhost:1521/xe
org.quartz.dataSource.myDS.user = {user}
org.quartz.dataSource.myDS.password = {password}
org.quartz.dataSource.myDS.maxConnections = 10
org.quartz.dataSource.myDS.validationQuery = SELECT 1 FROM DUAL
# ThreadPool 설정
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount = 5
org.quartz.threadPool.threadPriority = 5org.quartz.jobStore.driverDelegateClass = OracleDelegate→ Oracle 전용 드라이버 델리게이트 사용org.quartz.jobStore.tablePrefix = QRTZ_→ 테이블 접두어 설정 (기본값 유지)org.quartz.dataSource.myDS→ Oracle DB 연결 정보 (필요에 따라 user, password, URL 변경)org.quartz.threadPool.threadCount = 5→ 5개의 작업 스레드 사용
참고자료
https://www.quartz-scheduler.org/documentation/quartz-2.3.0/
