네트워크 기본
TCP/IP 4계층 또는 TCP/IP 5계층 또는 OSI 7계층
OSI 7계층
L7 - 어플리케이션
L6 - 표현
L5 - 세션
L4 - 전송 ( TCP / UDP, 방화벽 )
L3 - 네트워크 (IP)
L2 - 데이터링크
L1 - 물리계층
L1, L2 / L3 / L4 / L5, L6, L7 --> TCP/IP 4계층
말하는 사람이 자기 개념에 맞게끔 사용. (5계층은 잘 안 씀)
물리계층
어떠한 장비에서 0과 1로 이루어진 데이터가 있을 때 빛의 신호로 변환하여 쏴주는 역할
데이터링크 계층
직접적으로 연결
EX. 한 공유기에 연결되어 있는 컴퓨터들 --> 같은 네트워크
우리집 컴퓨터에서 네이버에 연결 --> 다른 네트워크
서브넷 마스크가 같다 = 같은 네트워크다.
• 데이터링크 : 같은 네트워크 상의 통신방법 / 같은 네트워크 상에서 이동을 할 때 데이터링크를 통하며 이동을 한다.
tracert : 거쳐가는 IP 주소를 찍어주는 명령어

arp -a : 이더넷 카드에 대한 주소(MAC주소)
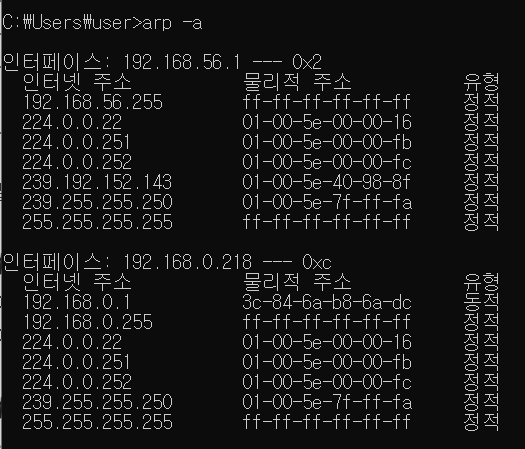
해당 지점에서 다른 지점으로 이동하는 게 ARP 프로토콜
ARP 프로토콜을 거치고 거쳐서 목표지점에 도달
각자 컴퓨터에는 대역이 정해져있다 --> 자기가 가지고 있는 라우트 테이블을 보고 IP를 파악하여 해당 MAC 주소로 보냄 (같은 네트워크 상에는 무조건 MAC 주소로 보냄)
공유기 - 공유기 / 라우터 / 게이트웨이 역할
라우팅 테이블 - 동적으로 결정 : 알고리즘에 의해 효율적으로 업데이트됨
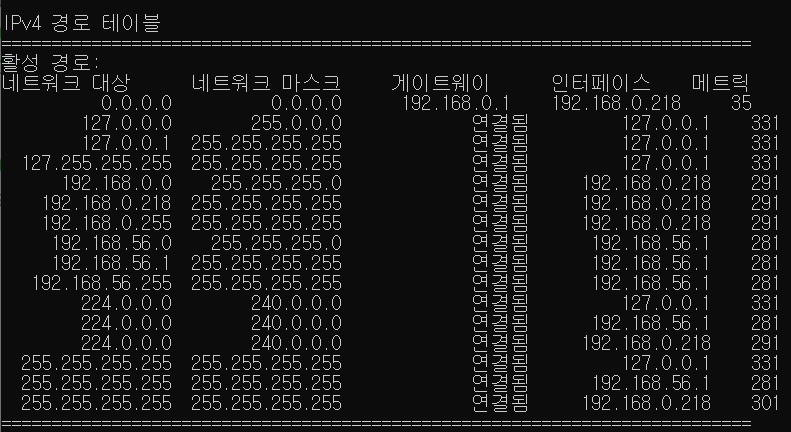
네트워크 계층
IP
전송 계층
TCP vs UDP
TCP : 신뢰기반 연결형 - 속도 비교적 느림, 대신 데이터 손실 확인 가능
채팅, 메일 등 대부분에서 TCP가 쓰임
UDP : 비신뢰기반 연결형 - 속도 빠름, 대신 데이터 손실 확인 불가
게임, 스트리밍에 자주 쓰임
• 포트 : 2바이트의 숫자로 이루어짐
http/ftp 등에 포트숫자가 숨어 있음
응용 계층 (세션, 표현, 어플리케이션)
표현, 세션은 잘 몰라도 됨
L7(어플리케이션) -> http, ftp, ssh 등
• TCP/UDP : 신뢰기반인지 비신뢰기반인지만 구분하는 것
• TCP -> http, ftp ...
= 실제 프로그램에서 쓰는 프로토콜
• Well-known Protocol(1~1000) : 알려져 있는 포트 번호와 프로토콜 이름이 명시되어 있는 프로토콜
--------------기초 끝--------------------
패킷 기반
A -> B에게 데이터를 전송한다고 하자. 중간에 yu라는 컴퓨터가 존재한다.
A
L7) GET/ HTTP1.1
HOST : naver.com
L4) 80 TCP
L3) 111.222.111.222
L2) yu의 MAC - AA:BB:33:44:55:66
L1) LAN 연결
YU
L2부터 찬찬히 봄
내가 아는 mac 주소가 아니다 --> PASS
L3 ~ L7정보는 똑같고, L2 주소만 ARP 프로토콜을 사용하여 변환한 뒤 B에게 보내줌
B
L2부터 뜯어봄
내 거다 -> 한 단계 올라감(L3 -> L4 -> L7)
L7까지 올라왔으면 L7의 패킷을 받아 자기 프로그램에서 처리
L2 - 랜카드
L3, L4 - 드라이버/커널(OS)
L7 - 프로그램
방화벽 설정 시 윈도우 커널에서 설정
• 용어들 파악하기
L7 - 데이터
L4 - 세그먼트
L3 - 패킷
L2 - 프레임
데이터 + header + tail : 세그먼트
세그먼트 + header + tail : 패킷
패킷 + header + tail : 프레임
send할 때는 h+t를 붙여나가고
recv할 때는 h+t를 까고
공인 IP
IPv4 - 32비트 (ex. 10.2.5.17)
• 0~255까지 = 2^8, 즉 8비트씩 4자리
IPv6 - 128비트
IP주소 - ISP(Internet Sevice Provider)가 제공
• GeoIP : 나라별 IP 발급
이 나라별 IP를 바탕으로 ISP가 IP주소 제공
학교 등에서도 단체 대역을 잡아서 IP를 구매
기업에서도 ISP업체로부터 IP 대역을 구매할 수 있음
사설 IP
192.168 (C클래스)
172 (B클래스)
10.8 (A클래스)
로 시작하면 무조건 사설 IP
대신 사설 IP를 쓸 때, 누군가는 공인 IP를 가지고 있어야 인터넷 가능
공인 IP를 가지고 있는 게 공유기
첫 시작이 A -> B인지, B -> A인지
A가 사설 IP 갖고 있는 개인 컴퓨터
B가 네이버같은 곳
A -> B
: ARP패킷을 공인 IP를 가지는 컴퓨터에 보내고, 그 컴퓨터의 NAT에 사설IP와 언제 보냈는지 등에 대한 정보가 저장된다.
받을 때의 포트 번호 필요 -> NAT에 저장
이 때는 B -> A일 때 NAT에 정보가 저장되기 때문에 문제없이 전송 가능
B -> A
• 포트포워딩 : NAT를 만들어주는 것
서브넷마스크
255.255.255.0 - C클
255.255.0.0 - B클
255.0.0.0 - A클
255.255.255.0 = 11111111.11111111.11111111.0
192.168.0.~ -> 서브넷마스크가 같으니까 같은 C클래스 (0~255)
192.168.~.~ -> 같은 B클래스
192.~.~.~ -> 같은 A클래스
0~255지만, 특수용도로 안 쓰는 것 제외하면 252대 정도.
내 IP와 서브넷마스크에 있는 숫자만큼 같은 IP들은 같은 네트워크가 되는 것.
서브넷마스크: 고정적 -> 네트워크를 좀 다양하게 분리하고 싶은 경우엔?
CADR : (ex) 255.255.247.0/30 -> 1이 30개가 있다는 것
==> 시작 아이피는 255.255.255.252
192.168.0.7과 같은 네트워크는 192.168.0.4~7
11111111.11111111.11111111.000001/11 (00 ~ 11)연습
내 개인 IP : 192.168.56.1/28
11111111.11111111.11111111.11110000 -> 서브넷마스크
192.168.56.0000/0001
시작 : 192.168.56.0
끝 : 192.168.56.15
WiFi : 192.168.0.218/28
11111111.11111111.11111111.11110000 -> 서브넷마스크
192.168.0.1101/1010
Wi-Fi : 192.168.0.208~223
멀티프로세스 / 멀티스레드 / 멀티플렉싱
멀티프로세스
디스크에 있는 게 프로그램
메모리에 있는 게 프로세스
• 디스크와 메모리를 나눈 구조 : 폰노이만 구조
CPU가 메모리와 통신하기 때문에 폰노이만 구조에서 메모리가 주기억장치
메모리 상에 프로세스가 여러 개 있다면 -> 멀티프로세스
(ex) 카카오톡을 여러 개 띄운 상태
• 메모리 구조
- 스택
- 코드영역
- 힙
- 데이터
멀티프로세스 상태더라도 메모리 구조가 분리되어 있기 때문에 한 프로세스가 다른 프로세스에 영향을 주지 않는다. 즉, 프로세스가 각각 독립적이다.
• 문제점
1. 여러 개의 프로세스가 코드영역이 다 똑같기 때문에 낭비
2. 중복되는 데이터가 여러 개 올라가도 낭비
3. 관리하는 데 오래 걸리고 문맥교환 비용도 많이 든다.
멀티 프로세스: 비효율적 -> 보완한 게 멀티스레드
멀티스레드 (+ 스레드 풀)
• 스레드 : 하나의 실행 흐름. 다른 스레드와 동시 실행 가능. 스택을 제외한 메모리 구조의 3가지 정보를 공유한다. 은행창구의 상담사 느낌
-> 따라서 스레드 하나당 스택만 따로 만들면 됨.
-> PCB보다는 훨씬 간단 -> 비용 저렴단점 : 동기화 이슈
스레드를 생성하고 삭제하는 데에 비용이 가장 많이 든다
이걸 보완하고자 만든 게 스레드 풀
• 스레드 풀 : 내가 쓸 스레드를 미리 만들어 놓는 것. 큐를 이용해서 관리. 비용 부분에서 효율적이다. 대기는 생길 수 있다.
멀티플렉싱
커널의 도움을 받아야 함.
개념) 커널에서 관리하는 큐에 소켓 번호를 넣어두고, 해당 번호를 호출(recv) 시 핸들러(Call-Back 함수)에서 처리할 수 있도록 넘겨줌. FD를 쓰지 않고, 실제 send와 recv를 하는 work 개념. 멀티플렉싱 기법이 훨씬 빠름. 은행에서 고객의 요청을 해당 스레드에게 넘기는 느낌
• FD : 파일 디스크립터
리눅스 : epoll로 구현
