2. 구조체 (structure)
✔️ 특징
1) 사용자가 정의하는 새로운 data type
2) 서로 다른 type의 원소들을 모아 하나의 record(or block) 를 구성
- heterogeneous (이질적) -서로 다른 타입의 원소들로 구성
- contiguous (연속적) -빈틈없이 구성
✔️ C/C++ 의 구조체
typedef struct {
char name[20]; //name이라는 문자열(string) 1차원 배열
int age;
float height;
char addr[100]; //주소를 나타내는 문자열
} student; //새로운 data type의 이름 && 구조체의 이름
student A,B,D[10],E[3][5],*F,*G;
//D:student 구조체 10개를 모아놓은 1차원 배열,(1단계 포인터)
//E:구조체의 2차원 배열,(2단계 포인터)
//포인터는 구조체가 아니야. 포인터는 주소를 가리키는 변수일 뿐,,✔️ 일반 사용법
A.name = "nang"
A.age = 24
A.height = 163.0
F = (student*)malloc(10* sizeof(student)(구조체 한 개의 크기))
F[4].name = "dang" //F[4] : 5번째 원소(구조체)
free(F)
G = &B
ex) G->name = "jun"
G->age = 16
cf) . 과 -> :구조체가 독립적인지 구조체를 가리키는 포인터인지에 따라 ✔️ 구조체의 자체 pointer
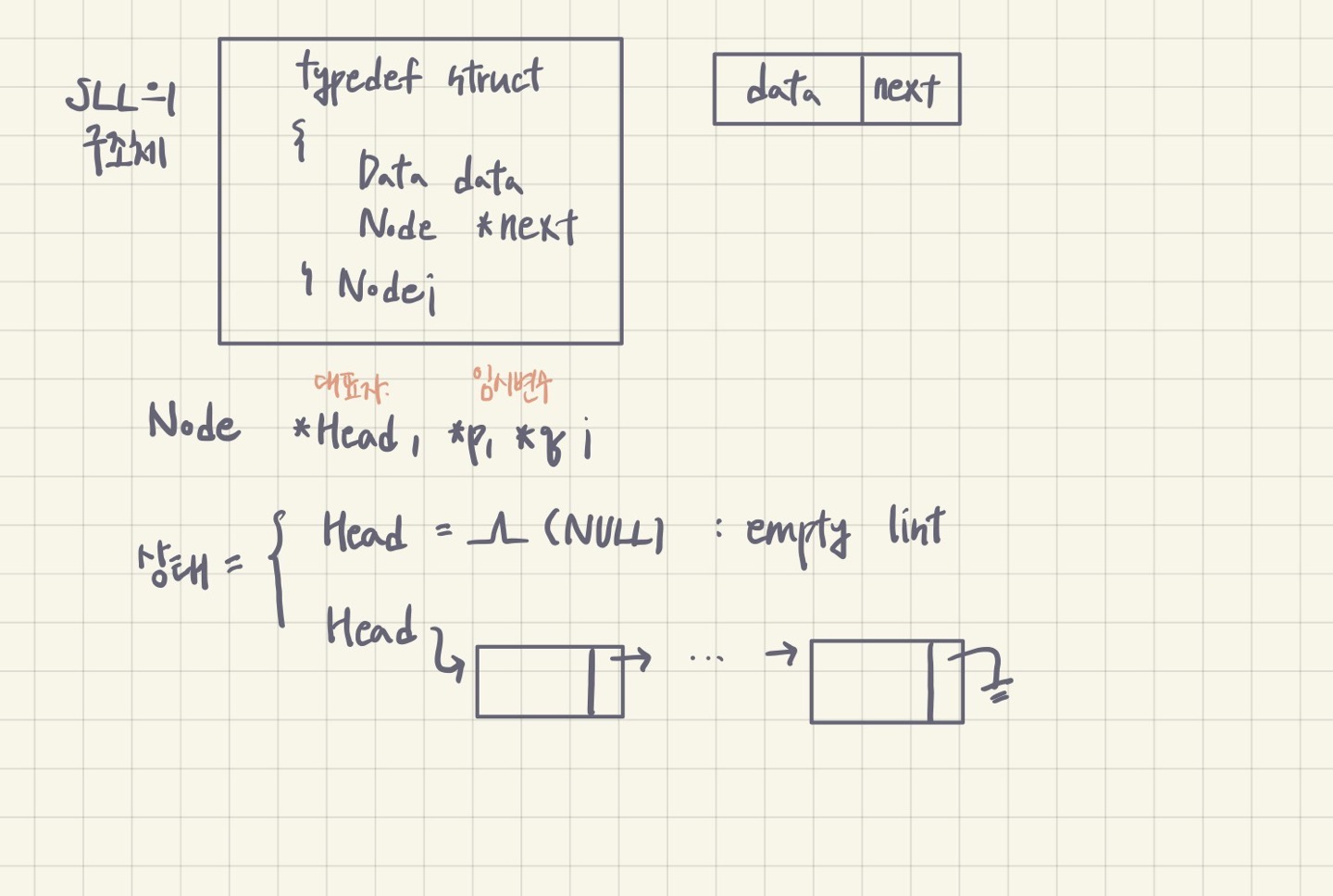
typedef struct {
char name[20];
int age;
float height;
.
.
Node *p,*q; //자체 pointer
} Node; //새로운 구조체 이름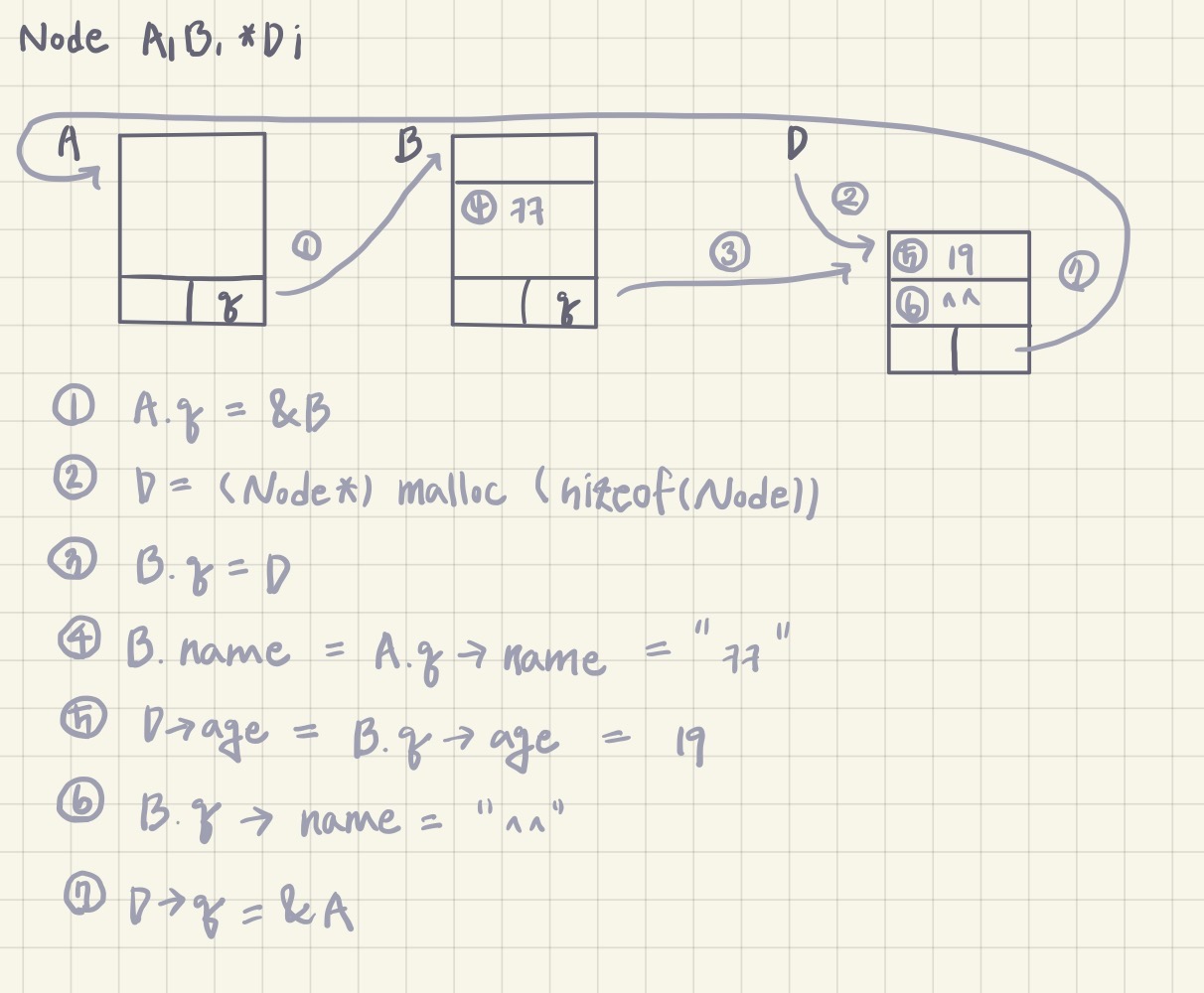
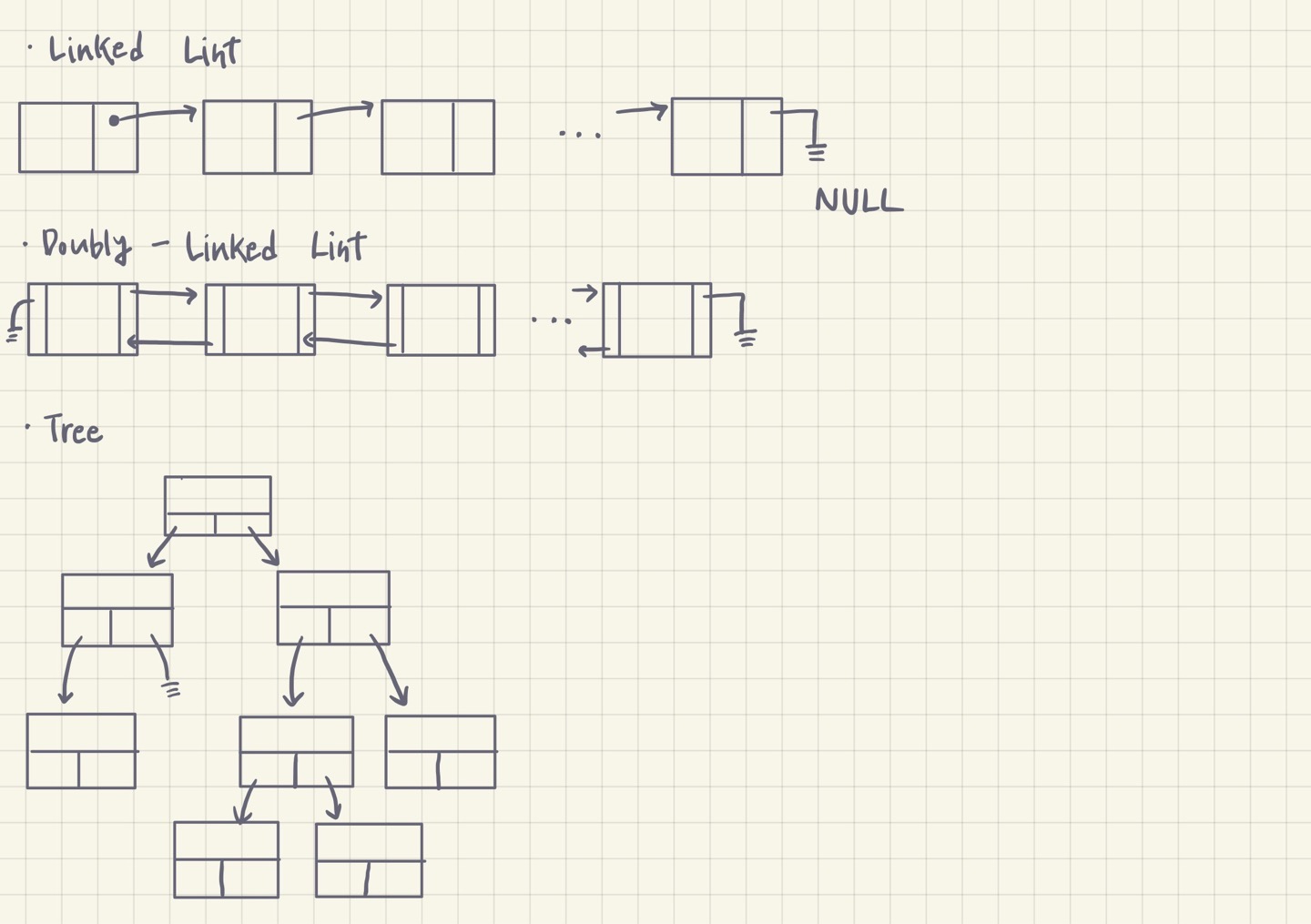
✔️ 자체 pointer에 의한 다양한 자료구조들
Chapter 4. List
: data의 명단으로서 배열 or linked list에 저장
1) Singly - Linked List (SLL)
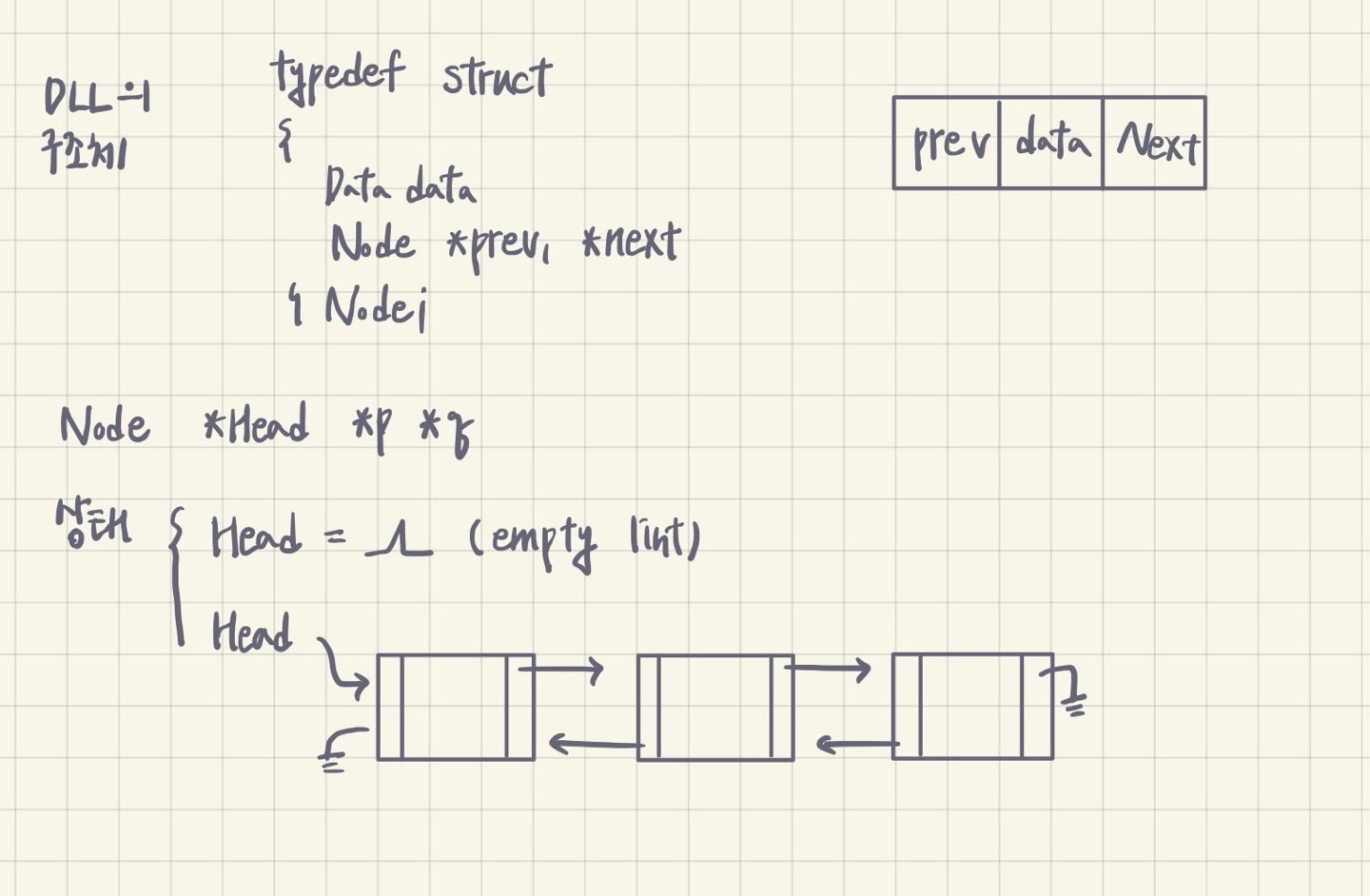
2) Doubly - Linked List (DLL)
📎 모든 ADT (추상적 자료구조)의 기본연산
1) 검색 (search)
2) 수정 (modify)
3) 삽입 (insert)
4) 삭제 (delete)
1. SLL (Singly - Linked List)
1) 검색 (search) (Key(data의 덩어리)를 찾음)
p = Head;
while (p != NULL) {
if (p->data = Key) {
found!!
}
p = p -> Next
}
Not found ㅠㅠ(while문을 탈출한 것은 찾고자 하는 data가 없다)💡 참고
1) 선형검색(linear search) : 시간 분석 결과가 n에 대한 일차식 -> O(n)
- data가 순차적 공간(sequential memory)(ex.SLL, tape, 하드디스크, ..)에 저장되었거나, 정렬이 안되었을 때(unsorted)
-> 순차적 공간: 위치에 따라 접근시간이 달라짐
2) 이진 검색 (binary search) -> O(logn) (최선)
: 배열 등의 RAM에 sorting 된 data
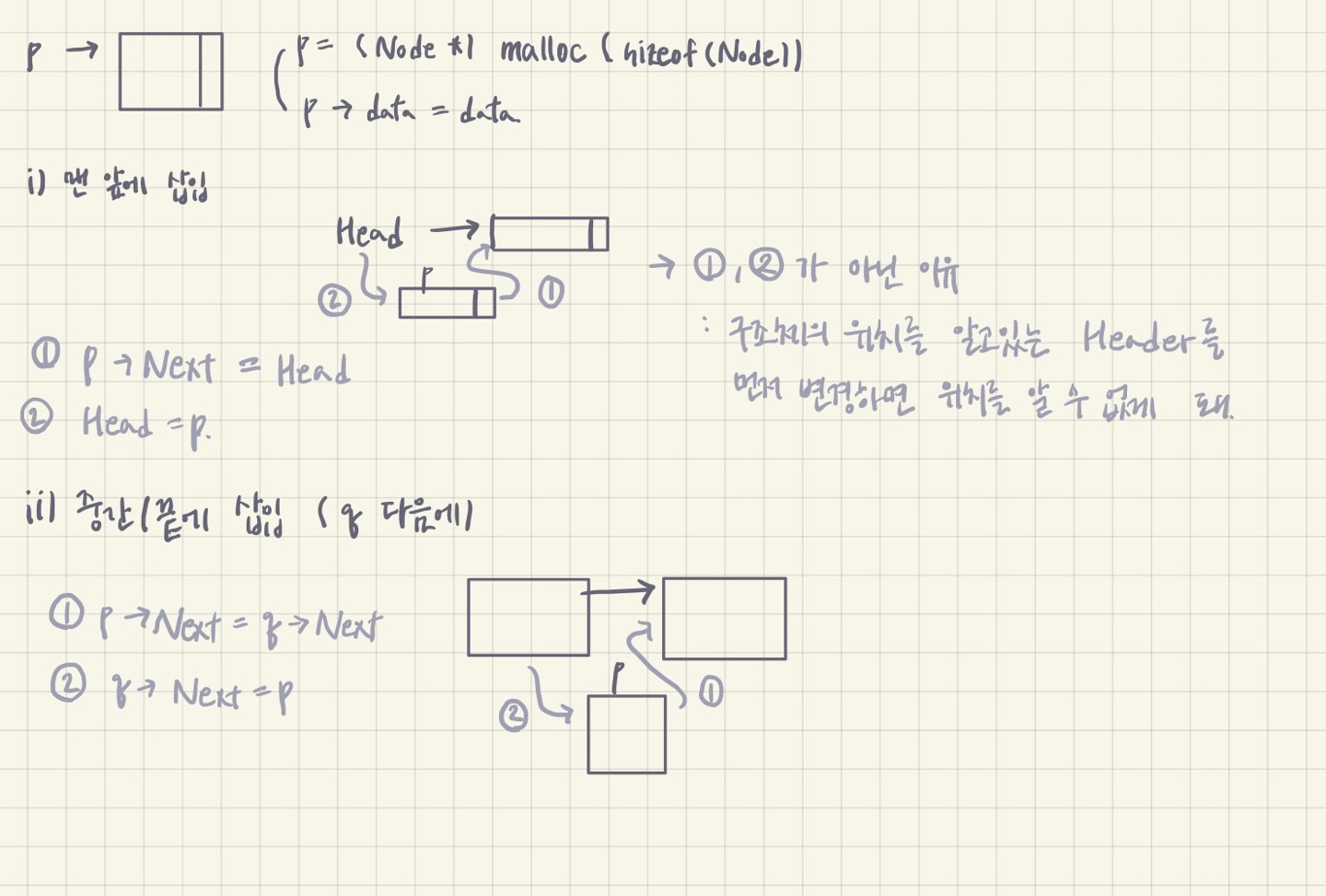
2) 삽입 (insert)
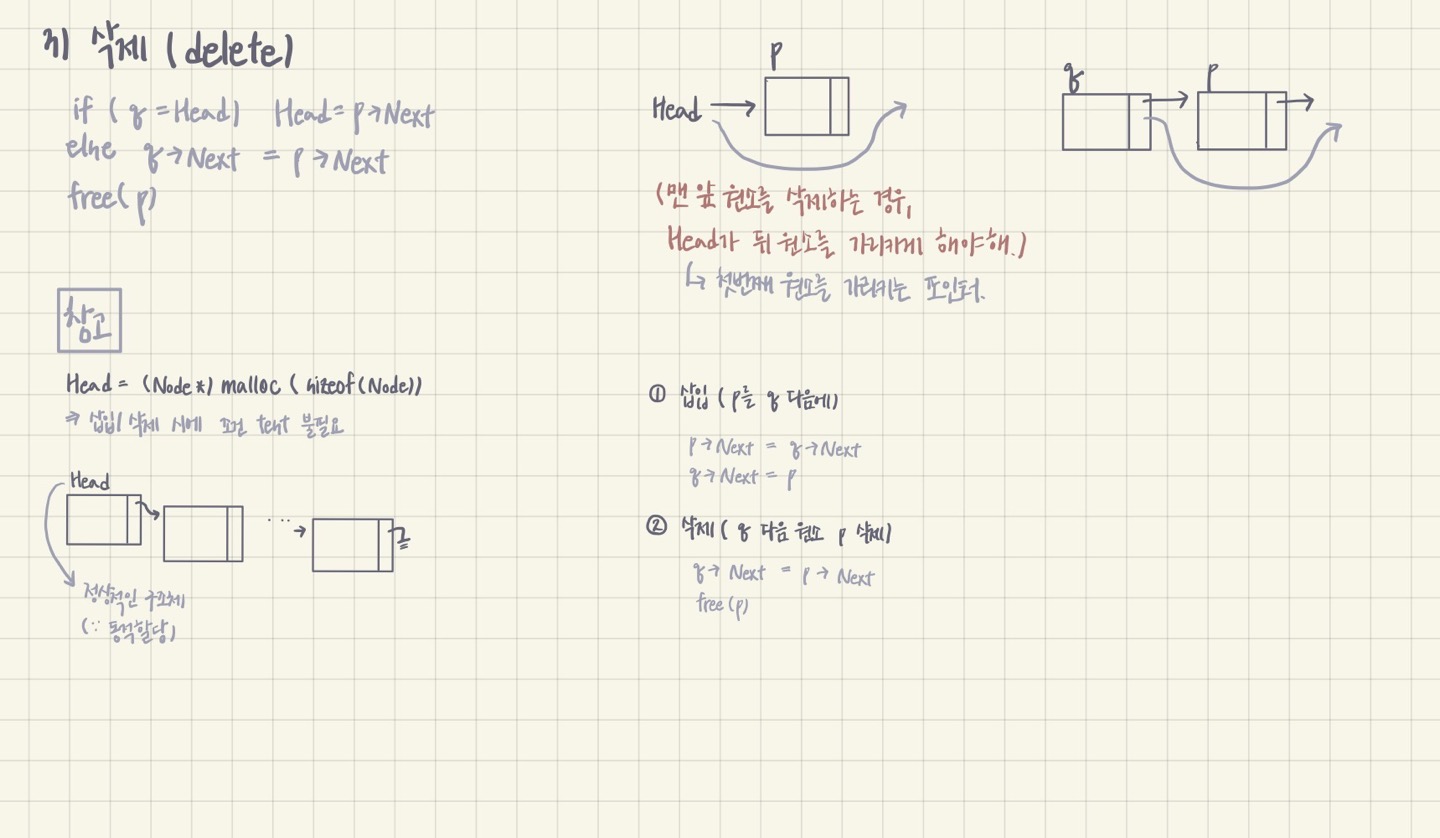
3) 삭제 (delete)
: q 다음 원소인 p 삭제
2. DLL (Doubly - Linked List)
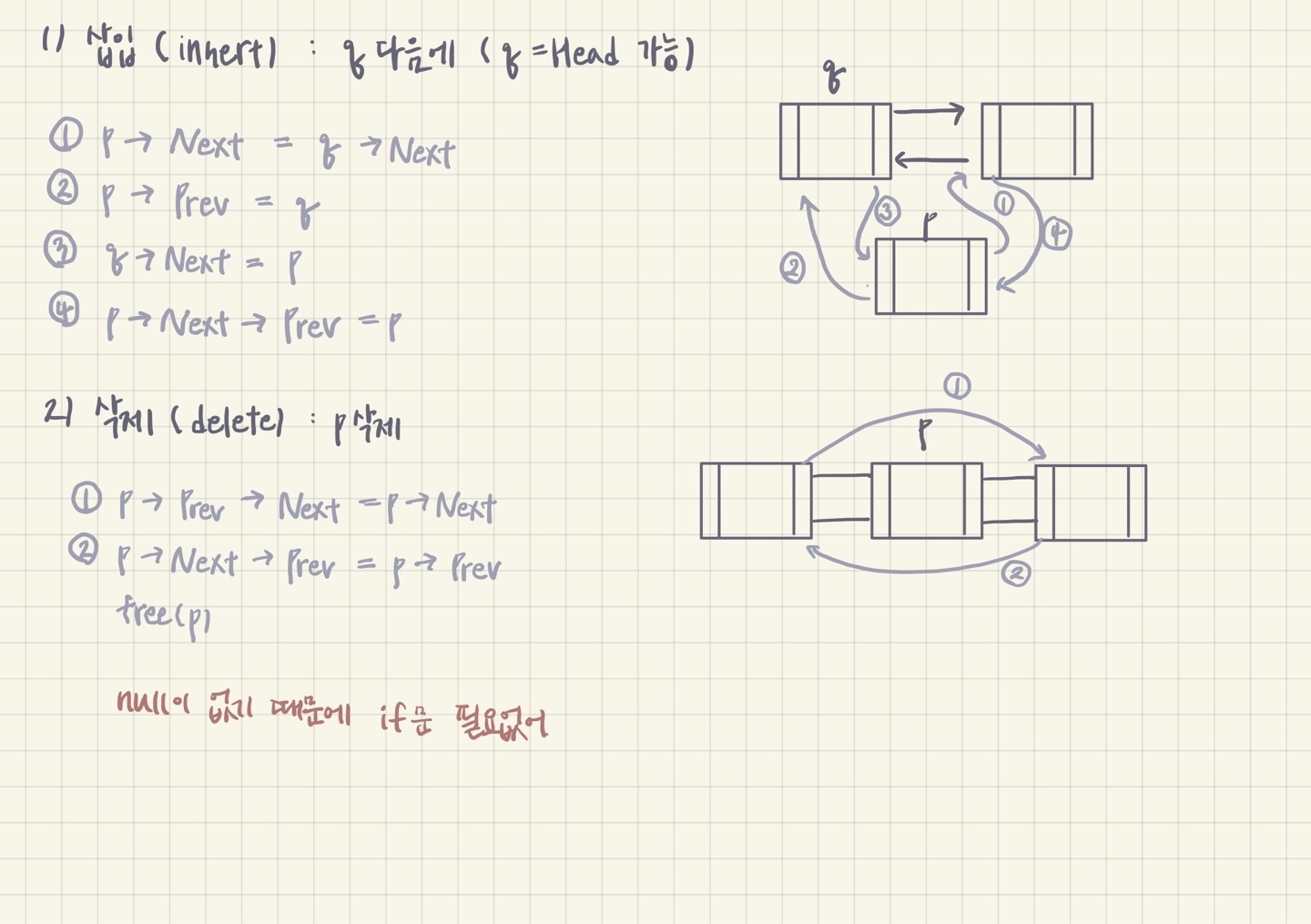
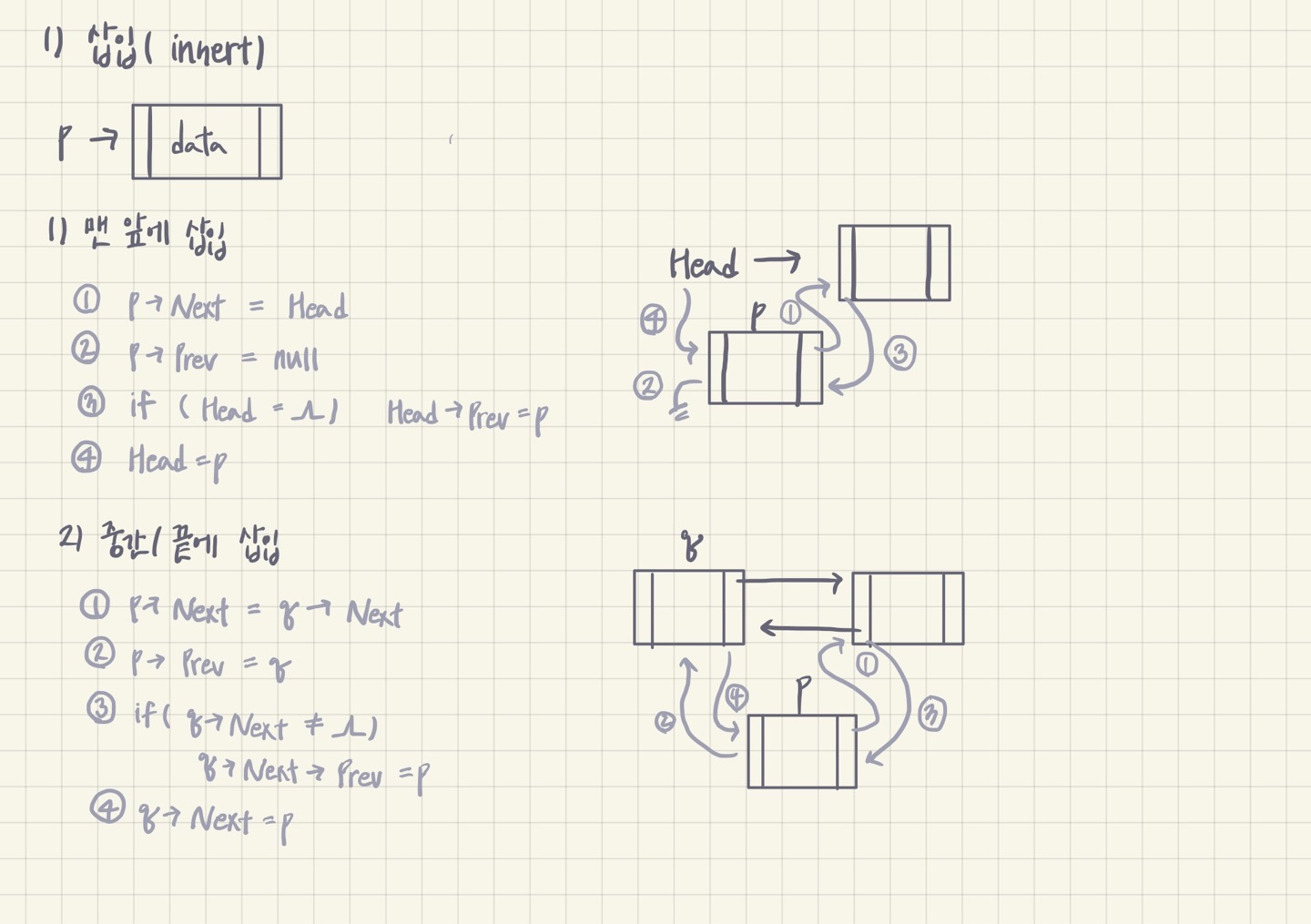
1) 삽입 (insert)
2) 삭제 (delete)
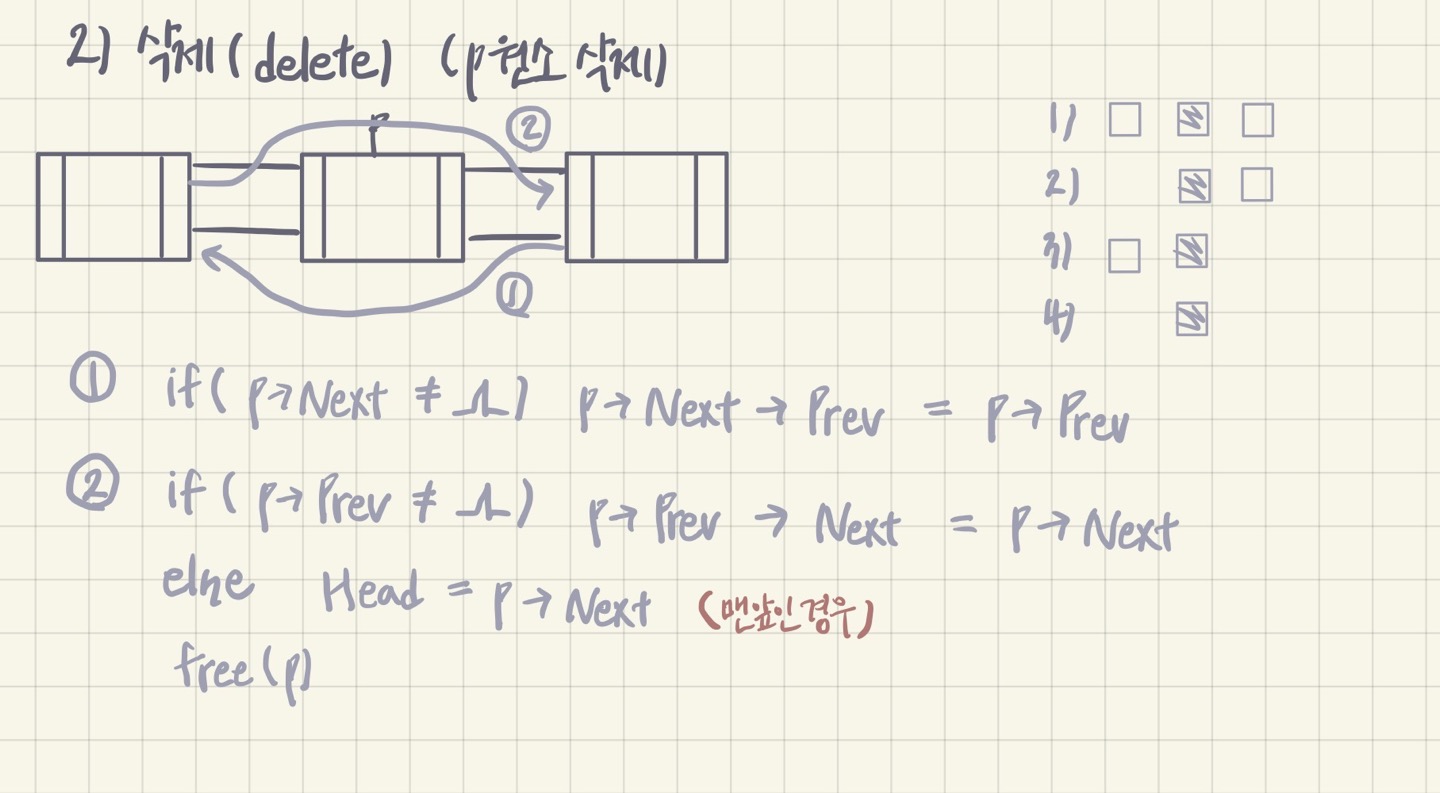
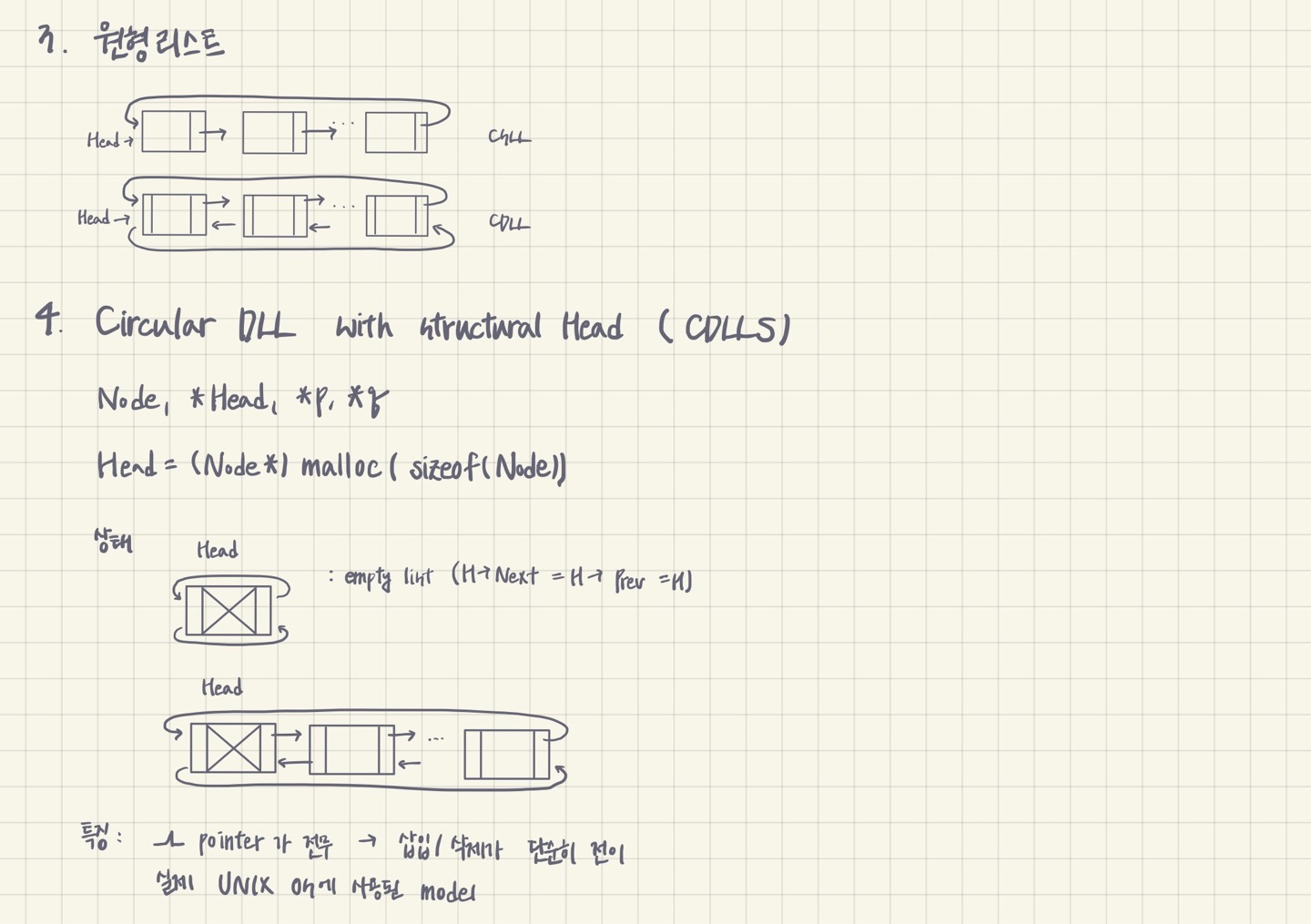
3. 원형리스트
4. Circular DLL with structural Head (CDLLS)
1) 삽입 (insert)
2) 삭제 (delete)