
파이썬의 자료형
정수형, 실수형, 복소수형, 리스트, 문자열, 튜플, 사전, 집합
정수형(Integer)
정수를 다루는 자료형
- 양의 정수
- 음의 정수
- 0
실수형(Real Number)
소수점 아래의 데이터를 포함하는 수 자료형
파이썬에서 변수에 소수점을 붙인 수를 대입하면 실수형 변수로 처리
소수부나 정수부가 0인 소수는 0 생략 가능
#소수부가 0일 때 0을 생략
a = 5.
print(a) #5.0
#정수부가 0일 때 0을 생략
a = -.7
print(a) #-0.7지수 표현 방식
파이썬에서 e나 E를 이용하여 지수 표현 방식을 이용할 수 있다.
- e나 E 다음에 오는 수는 10의 지수부를 의미
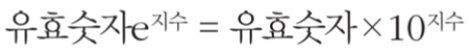
- 임의의 큰 수를 표현하기 위해 자주 사용
- 최단 경로 알고리즘에서는 도달할 수 없는 노드에 대하여 최단 거리를 무한(INF)으로 설정하곤 함
- 이때 가능한 최댓값이 10억 미만이라면 무한(INF)의 값으로 1e9를 이용할 수 있다.
실수형의 정확도
오늘날 IEEE754 표준에서는 실수형을 저장하기 위해 4바이트, 혹은 8바이트의 고정된 크기의 메모리를 할당하므로, 컴퓨터 시스템은 실수 정보를 표현하는 정확도에 한계를 가진다
예를 들어 10진수 체계에서 이지만 2진수에서는 0.9를 정확히 표현할 수 있는 방법이 없고 미세한 오차 발생.
a = 0.3 + 0.6
print(a) #0.8999999999999999
if a == 0.9:
print(True)
else:
print(False) #False로 출력이런 경우 round() 함수 이용하여 반올림
- 123.456 소수 셋째 자리 반올림 123.46: round(123.456, 2)
수 자료형의 연산
- 나누기 연산자(/)는 결과를 실수형으로 반환
- 나머지는 나머지 연산자(%) 이용
ex) 홀수 체크 시 - 몫은 몫 연산자(//) 이용
- 이외에도 거듭 제곱 연산자(**) 등 존재
리스트 자료형
여러 개의 데이터를 연속적으로 담아 처리하기 위해 사용하는 자료형
- C나 JAVA에서의 배열(Array)의 기능 및 연결 리스트와 유사한 기능 지원
- C++의 STL vector와 기능적으로 유사
- 배열 or 테이블이라고 부르기도 함.
리스트 초기화
- 대괄호(
[])안에 원소를 넣어 초기화하며, 쉼표(,)로 원소 구분 - 비어 있는 리스트 선언할 때는
list()혹은 간단히[]를 이용 - 리스트의 원소에 접근할 때는 인덱스(Index) 값을 괄호에 넣는다. 인덱스는 0부터 시작
#크기가 N이고, 모든 값이 0인 1차원 리스트 초기화
n = 5
a = [0] * n
print(a) #결과: [0, 0, 0, 0, 0]리스트의 인덱싱과 슬라이싱
인덱스 값을 입력하여 리스트의 특정한 원소에 접근하는 것을 인덱싱(Indexing)이라고 한다.
- 인덱스 값으로 양의 정수, 음의 정수 모두 사용 가능
- 음의 정수를 넣으면 원소를 거꾸로 탐색
a = [1, 2, 3, 4, 5]
#뒤에서 첫 번째 원소 출력
print(a[-1]) #결과: 5리스트에서 연속적인 위치를 갖는 원소들을 가져와야 할 때는 슬라이싱(Slicing)을 이용
- 대괄호 안에 콜론(:)을 넣어서 시작 인덱스와 끝 인덱스 설정 가능
- 끝 인덱스는 실제 인덱스보다 1을 더 크게 설정
a = [1, 2, 3, 4, 5]
#두 번째 원소부터 네 번째 원소까지
print(a[1 : 4]) #결과: [2, 3, 4]리스트 컴프리헨션(List Comprehension)
리스트를 초기화하는 방법 중 하나로 대괄호 안에 조건문과 반복문을 적용하여 리스트 초기화
예시1)
#0부터 9까지의 수를 포함하는 리스트
array = [i for i in range(10)]
print(array) #[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#1부터 9까지의 수들의 제곱 값을 포함하는 리스트
array = [i * i for i in range(1,10)]
print(array) #[1, 4, 9, 16, 25, 36, 49, 64, 81]예시2) 일반적인 코드와 리스트 컴프리헨션
#리스트 컴프리헨션
#0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [i for i range(20) if i % 2 == 1]
print(array) #[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
#일반적인 코드
#0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = []
for i in range(20):
if i % 2 == 1:
array.append(i)
print(array) #[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]- 리스트 컴프리헨션은 2차원 리스트 초기화 할 때 효과적으로 사용
- 특히 N x M 크기의 2차원 리스트를 한 번에 초기화 해야 할 때 매우 유용
좋은 예시: array = [[0] * m for _ in range(n)]
잘못된 예시: array = [[0]*m] * n
위 코드는 전체 리스트 안에 포함된 각 리스트가 모두 같은 객체로 인식되어 특정한 인덱스 값을 변경 시 예상치 못한 결과가 나올 수 있다
#좋은 예시
#N x M 크기의 2차원 리스트 초기화
n = 4
m = 3
array = [[0] * m for _ in range(n)]
#[[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
print(array) 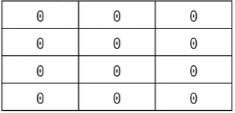
#잘못된 예시
#N x M 크기의 2차원 리스트 초기화
n = 4
m = 3
array = [[0]*m] * n
#[[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]
print(array)
#내부 리스트가 모두 같은 객체로 인식
array[1][1] = 5
#[[0, 5, 0], [0, 5, 0], [0, 5, 0], [0, 5, 0]]
print(array)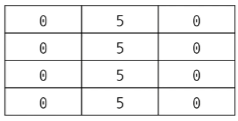
💡 언더바( _ )는 언제 사용할까?
반복을 수행하되 반복을 위한 변수의 값을 무시하고자 할 때 언더바( _ ) 사용
리스트 관련 기타 메서드
| 함수명 | 사용법 | 설명 | 시간 복잡도 |
|---|---|---|---|
| append() | 변수명.append() | 리스트에 원소 하나 삽입 시 사용 | |
| sort() | 변수명.sort() | 기본 정렬 기능, 오름차순 정렬 | |
| 변수명.sort(reverse=True) | 내림차순 정렬 | ||
| reverse() | 변수명.reverse() | 리스트의 원소 순서를 모두 뒤집어 놓는다 | |
| insert() | insert(삽입할 위치 인덱스, 삽입할 값) | 특정 위치에 원소 삽입 시 | |
| count() | 변수명.count(특정값) | 리스트에서 특정한 값을 가지는 데이터 개수를 셀 때 | |
| remove() | 변수명.remove(특정값) | 특정한 값을 갖는 원소 제거 | |
| 값을 가진 원소가 여러개면 하나만 제거 |
리스트에서 특정 값을 가지는 원소 모두 제거하기
a = [1, 2, 3, 4, 5, 5, 5]
remove_set ={3, 5} #집합 자료형
#remove_set에 포함되지 않은 값만을 저장
result = [i for i in a if i not in remove_set]
print(result) #[1, 2, 4]문자열 자료형
문자열 변수를 초기화할 때는 큰따옴표(")나 작은 따옴표(')이용
- 문자열 안에 큰 따옴표나 작은따옴표가 포함되어야 하는 경우
- 전체 문자열을 큰따옴표로 구성하는 경우, 내부적으로 작은따옴표 포함 가능
- 전체 문자열을 작은따옴표로 구성하는 경우, 내부적으로 큰따옴표 포함 가능
- 혹은 백슬래시(\)를 사용하는 경우, 큰따옴표나 작은따옴표를 원하는 만큼 포함 가능
data = 'Hello World'
print(data) #Hello World
data = "Don't you know \"Python\"?"
print(data) #Don't you know "Python"?문자열 연산
- 문자열 변수에 덧셈(+)을 이용하면 문자열이 더해져서 연결(Concatenate)된다.
- 문자열 변수를 특정한 양의 정수와 곱하는 경우, 문자열이 그 값만큼 여러 번 더해진다.
- 문자열에 대해서도 인덱싱, 슬라이싱 이용 가능.
(다만 문자열은 특정 인덱스의 값을 변경할 수는 없다. Immutable)
a = "Hello"
b = "World"
print(a + " " + b) #Hello World
a = "String"
print(a * 3) #StringStringString
a = "ABCDEF"
print(a[2 : 4]) #CD튜플 자료형
튜플 자료형은 리스트와 유사하지만 다음과 같은 문법적 차이가 있다.
- 튜플은 한 번 선언된 값을 변경할 수 없다
- 리스트는 대괄호(
[])를 이용하지만, 튜플은 소괄호(())이용
튜플은 리스트에 비해 상대적으로 공간 효율적
튜플을 사용하면 좋은 경우
-
서로 다른 성질의 데이터를 묶어서 관리해야 할 때
ex) 최단 경로 알고리즘 (비용, 노드 번호) 형태로 자주 사용 -
데이터의 나열을 해싱(Hashing)의 키 값으로 사용해야 할 때
튜플은 변경이 불가능하므로 리스트와 다르게 키 값으로 사용 가능 -
리스트보다 메모리를 효율적으로 사용해야 할 때
사전 자료형
키(Key)와 값(Value)의 쌍을 데이터로 가지는 자료형
- '변경 불가능한(Immutable) 자료형'을 키로 사용
- 파이썬의 자료형은 해시 테이블(Hash Table)을 이용하므로 데이터의 조회 및 수정에 있어서 의 시간에 처리 가능.
[예시]
| 키(Key) | 값(Value) |
|---|---|
| 사과 | Apple |
| 바나나 | Banana |
| 코코넛 | Coconut |
data = dict()
data['사과'] = 'Apple'
data['바나나'] = 'Banana'
data['코코넛'] = 'Coconut'
print(data)
if '사과' in data:
print("'사과'를 키로 가지는 데이터가 존재합니다.")
[실행결과]
{'사과': 'Apple', '바나나': 'Banana', '코코넛: 'Coconut'}
'사과'를 키로 가지는 데이터가 존재합니다.사전 자료형 관련 메서드
keys()함수: 키 데이터만 뽑아서 리스트로 이용할 때 사용values()함수: 값 데이터만을 뽑아서 리스트로 이용할 때 사용items()함수: 키와 값을 뽑아서 리스트로 이용할 때 사용
- 단, 위 함수들은 하나의 객체로 반환되기 때문에 실제론list()함수를 사용하여 list로 형 변환 후 주로 사용
[예시]
data = dict()
data['사과'] = 'Apple'
data['바나나'] = 'Banana'
data['코코넛'] = 'Coconut'
#키 데이터만 담은 리스트
key_list = data.keys()
#값 데이터만 담은 리스트
value_list = data.values()
#키와 값 데이터를 담은 리스트
item_list = data.items()
print(key_list)
print(value_list)
print(item_list)
#각 키에 따른 값을 하나씩 출력
for key in key_list:
print(data[key])
#키와 해당되는 값을 하나씩 출력
for key, value in data.items():
print(key, value) [실행결과]
dict_keys(['사과', '바나나', '코코넛'])
dict_values(['Apple', 'Banana', 'Coconut'])
dict_items([('사과', 'Apple'), ('바나나', 'Banana'), ('코코넛', 'Coconut')])
Apple
Banana
Coconut
사과 Apple
바나나 Banana
코코넛 Coconut집합 자료형
-
집합의 특징
- 중복을 허용하지 않는다.
- 순서가 없다. -
집합은 리스트 혹은 문자열을 이용해서 초기화 할 수 있다.
- 이때set()함수 이용
- 혹은 중괄호({}) 안에 각 원소를 콤마(,)를 기준으로 구분하여 삽입
-
데이터의 조회 및 수정에 있어서 의 시간에 처리 가능.
#집합 자료형 초기화 방법 1
data = set([1, 1, 2, 3, 4, 5, 5])
print(data)
#집합 자료형 초기화 방법 2
data = {1, 1, 2, 3, 4, 5, 5}
print(data)[실행 결과]
{1, 2, 3, 4, 5}
{1, 2, 3, 4, 5}집합 자료형의 연산
기본적인 집합 연산으로는 합집합, 교집합, 차집합 연산 등이 있다.
- 합집합: ,
|연산자 사용 - 교집합: ,
&연산자 사용 - 차집합: ,
-연산자 사용
a= set([1, 2, 3, 4, 5])
b= set([3, 4, 5, 6, 7])
#합집합
print(a | b)
#교집합
print(a & b)
#차집합
print(a - b)[실행 결과]
{1, 2, 3, 4, 5, 6, 7}
{3, 4, 5}
{1, 2}집합 자료형 관련 메서드
add(): 새로운 원소 추가update(): 새로운 원소 여러 개 추가remove(): 특정한 값을 갖는 원소 삭제
data = set([1, 2, 3])
print(data)
#새로운 원소 추가
data.add(4)
print(data)
#새로운 원소 여러 개 추가
data.update([5, 6])
print(data)
#특정한 값을 갖는 원소 삭제
data.remove(3)
print(data)[실행 결과]
{1, 2, 3}
{1, 2, 3, 4}
{1, 2, 3, 4, 5, 6}
{1, 2, 4, 5, 6}리스트, 튜플, 사전, 집합 비교
-
리스트와 튜플은 순서가 있기 때문에 인덱싱을 통해 자료형의 값을 얻을 수 있다.
-
사전과 집합은 순서가 없기 때문에 인덱싱으로 값을 얻을 수가 없다.
- 사전은 키(key), 집합은 원소(Element)를 이용해 의 시간 복잡도로 조회
