[ 중요 포인트 요약 ]
-
손실함수 : 가중치 값 중에 어떤것이 좋은지 확인하는 과정( 계산을 통해 손실함수가 0에 수렴하는가 )
-
최적화 : 가중치 값이 문제를 최적으로 해결하는 classifier 로 설정됐는지 최적화
-
차원 : 데이터에서 차원은 피쳐의 개수로 볼 수 있음. 예를 들어서 유전자는 2억개의 피쳐 즉 2억 차원임. 일차원일때는 단순 “U”형의 손실함수여서 미분을 통해 최솟값을 구할 수 있음. 하지만 다차원이 되는 경우에는 단순한 미분으로는 최솟값을 확인 할 수 없고, 내적을 통해 확인 가능함.
1) CNN 과 같은 애들은 “데이터의 분포를 어떻게 잘 포착할 수 있는가” 가 중요한 포인트
데이터에서 패턴이나 특징을 효과적으로 추출 !
2) 손실함수와 최적화는 어떻게 파라미터 W를 잘 선정할 수 있을지 지속적인 업데이트
3) 학습률의 크기는 “모델이 손실 함수의 최솟값에 얼마나 빨리 수렴할 수 있는지”를 결정
4) 기울기가 클 때 학습률을 점진적으로 줄이는 이유: 학습률 키우면 빨리 최솟값으로 가는 거 아닌가? 라는 생각 들 수 있지만 ,,,, 학습률을 기울기가 클때 늘리면 발산할 수 있음 ! ( 과도한 업데이트 )
학습 초기에는 큰 학습률을 사용하여 빠르게 최솟값 근처로 접근할 수 있음. 하지만 최솟값 근처에서는 학습률을 줄여 작은 범위의 미세 조정을 통해 정확한 최솟값에 도달할 수 있음
5) L1 정규화 (라쏘), L2 정규화 (릿지)
- 라쏘 : weights에 절댓값을 함으로써 feature selection을 하는 효과를 줌.
- 첫번째 그림처럼 ∣β1∣+∣β2∣≤t와 같은 L1 정규화의 제약 조건과 잔차 제곱합 오류 함수(Residual Sum of Squares, RSS, 예측 값과 실제 값 사이의 차이를 제곱하여 합산한 값)이 만나는 순간 즉 weights가 0이 되는 경향을 증가 시켜서 가중치의 희소성을 만듬
- 릿지 : weights를 제곱함으로써 weights가 0에 가까워지게 하지만, 완전히 0이 되지는 않도록 함.
- 이 두번째 그림처럼 β1^2 + β2^2≤t^2 와 RSS 가 만나는 부분에서도 weights가 0이 되지는 않음. 이런식으로 데이터의 모든 특성을 일정 부분 활용하도록 하여, 정보 손실을 줄이기, 최적화 과정에서 모델이 더 안정적으로 수렴할 수 있도록 돕기
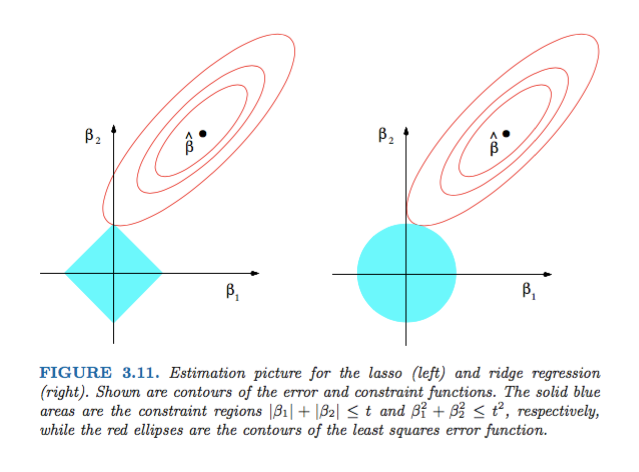
- 이 두번째 그림처럼 β1^2 + β2^2≤t^2 와 RSS 가 만나는 부분에서도 weights가 0이 되지는 않음. 이런식으로 데이터의 모든 특성을 일정 부분 활용하도록 하여, 정보 손실을 줄이기, 최적화 과정에서 모델이 더 안정적으로 수렴할 수 있도록 돕기
[PT Lecture Review] 발표한 자료는 아래와 같습니다

발표 자료 :
참고 강의 :

[ SPS Lab Paper Seminar YouTube ] : https://www.youtube.com/@spslab.1648