건축물대장 데이터 출처
우선 공공데이터 포털 건축물대장 API링크다.
인증키를 받는 방법은 여기저기 많으니 설명하지 않겠음.
가이드를 다운받아서 요청메세지 명세를 보자.
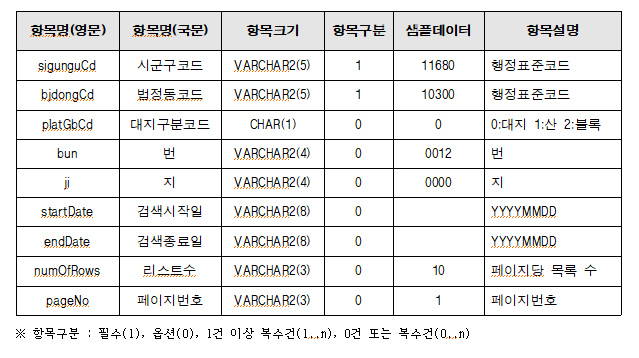
시군구코드, 법정동코드가 필수인 것을 볼 수 있다.
지번코드(PNU) 란

이런 구조로 이루어져있음.
나는 실거래가 데이터가 먼저 있었기때문에 거기서 지번코드를 뽑아 인풋데이터로 활용했다.
엑셀로 다운받았는데...처음엔 엑셀에서 자동으로 자릿수가 긴 지번코드를 e로 변환해놔서 뒷자리가 반올림 된걸 모르고 쓰다 데이터를 몇번 날렸다.
엑셀에서 세자리수마다 쉼표를 넣어서 불러오기를 해서 해결함.(다른 더 좋은 방법이 있을것같긴함)
엑셀 데이터를 다운받아서 쓰다보니 utf-8문제라던가...신고년도밖에 없어 월별 예측이 불가능 하다던가...여러가지 문제가 많아 결국 API로 불러오고있다...
지번코드 쪼개기
아무튼 다운받은 실거래가 엑셀을 불러와 지번코드 속성만 뽑아
쉼표 제거,
중복 제거 후,
df=df.loc[:,['지번코드']] ##실거래가(df)파일에서 지번코드 속성만 뽑기
df['지번코드']=df['지번코드'].str.replace(pat=r'[^0-9]', repl=r'', regex=True) #숫자뺴고 다 제거
df['지번코드'] = df.drop_duplicates(['지번코드'], keep='first') #중복 제거
df=df.dropna(axis=0) #결측치 제거
df = df.sort_values(by=['지번코드'], ascending=[True]) #혹시 모르니 오름차순 정렬시군구 5자리, 읍면동 5자리, 필지구분 1자리, 본번 4자리, 부번 4자리로 나누는 작업을 함.
df['sigungu']=(df.지번코드.str[:5])
df['dong']=(df.지번코드.str[5:10])
df['daesi']=(df.지번코드.str[10:11]) #0:대지 1:산 2:블록
df['bun']=(df.지번코드.str[11:15]) #본번
df['ji']=(df.지번코드.str[15:19]) #부번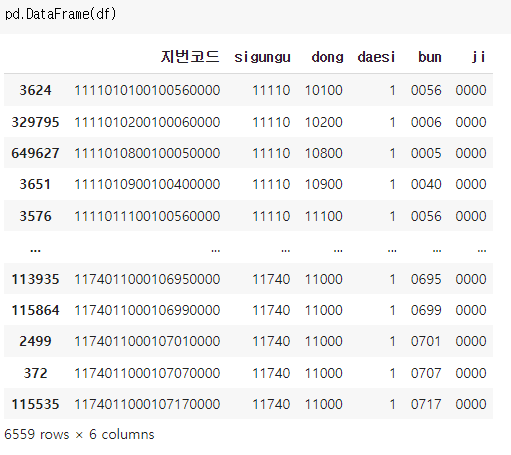
잘 나눠졌다.
여기서 필지구분(daesi)가 거의 1인걸 볼 수 있는데...(차후 문제가 생김...)
나눠진 지번코드를 반복문 파라미터로 쓰기 위해 리스트로 변환
sigungu=df['sigungu'].values.tolist()
dong=df['dong'].values.tolist()
daesi=df['daesi'].values.tolist()
bun=df['bun'].values.tolist()
ji=df['ji'].values.tolist()건축물 대장 XML 샘플 데이터 보기
데이터 출력 샘플을 보자
샘플을 보는 방법은 API 가이드에 적힌 url에 본인 인증키를 넣으면 된다

너무 길어서 한페이지에 캡쳐가 안된다...

음...저런 태그 안에 저런 데이터가 감싸져있군...
본격적으로 데이터 가져오기
그리고 여기서부터는 다른 분이 쓰신걸 참조했다.
https://operstu1.tistory.com/87
데이터를 가져오는중 에러가 나는걸 방지하기 위해 함수를 만든다.
def parse():
try:
platPlc = item.find("platPlc").get_text()
sigunguCd = item.find("sigunguCd").get_text()
bjdongCd = item.find("bjdongCd").get_text()
platGbCd = item.find("platGbCd").get_text()
bun = item.find("bun").get_text()
ji = item.find("ji").get_text()
vlRat = item.find("vlRat").get_text()
bcRat = item.find("bcRat").get_text()
engrGrade = item.find("engrGrade").get_text()
engrRat = item.find("engrRat").get_text()
gnBldGrade = item.find("gnBldGrade").get_text()
gnBldCert = item.find("gnBldCert").get_text()
bldNm = item.find("bldNm").get_text()
totPkngCnt = item.find("totPkngCnt").get_text()
return {
"대지위치":platPlc,
"시군구코드":sigunguCd,
"법정동코드":bjdongCd,
"필지구분":platGbCd,
"번":bun,
"지":ji,
"용적률":vlRat,
"건폐율":bcRat,
"에너지효율등급":engrGrade,
"에너지절감률":engrRat,
"친환경건축물등급":gnBldGrade,
"친환경건축물인증점수":gnBldCert,
"건물명":bldNm,
"총주차수":totPkngCnt
}
except AttributeError as e:
return {
"대지위치":None,
"시군구코드":None,
"법정동코드":None,
"필지구분":None,
"번":None,
"지":None,
"용적률":None,
"건폐율":None,
"에너지효율등급":None,
"에너지절감률":None,
"친환경건축물등급":None,
"친환경건축물인증점수":None,
"건물명":None,
"총주차수":None
}반복문 파라미터 여러개 한번에 넣기
그리고 아까 나눴던 시군구, 동, 대지, 번, 지 코드를 zip 함수를 사용해 한줄씩 묶어 파라미터로 넣는다.
(파라미터 여러개 한번에 넣는 방법을 찾느라 많이 헤맸다...)
data=[]
row = []
for sigungu, dong, daesi, bun, ji in zip(sigungu, dong, daesi, bun, ji):
url="http://apis.data.go.kr/1613000/BldRgstService_v2/getBrRecapTitleInfo?sigunguCd=" + str(sigungu) + "&bjdongCd=" + str(dong) + "&platGbCd=" + str(daesi) + "&bun=" + str(bun) + "&ji=" + str(ji) + "&ServiceKey=본인의 인증키"
print(url)
result=requests.get(url)
soup=BeautifulSoup(result.text, 'lxml-xml')
items=soup.find_all('item')
print(items)
for item in items:
row.append(parse())
print(row)
data = pd.DataFrame(row)휴...처음에 이대로 실행했다가 공공데이터 포털 트래픽이 하루 만건이라 데이터를 못가져와서 다 null값 담겨있기도 했고...
print를 너무 많이 찍어서 런타임 에러가 나서 데이터가 다 날아가기도 했다.
데이터 가져온 결과물 ver.1
그리고 우여곡절끝에 얻은 데이터가
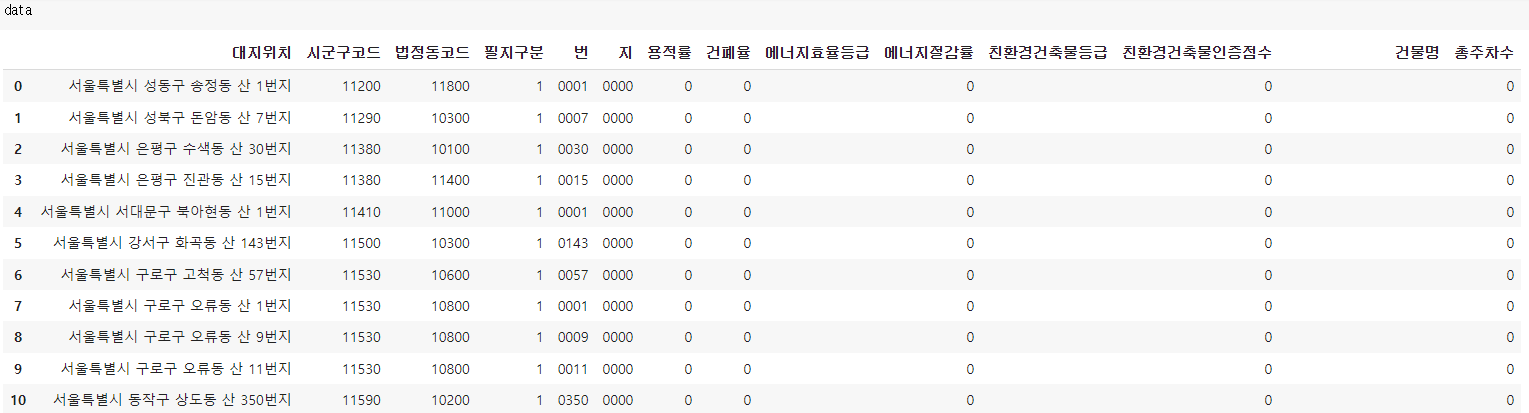
27개밖에 되지 않는데..........
이게 무슨일이요...
이건 뭔가 이상하다 싶어 이렇게 저렇게 살펴본 결과... 필지번호(daesi)가 행정과 건축에서 뭔가 미묘하게 다르게 쓰고 있단걸 알게되었다...(이부분 확인이 필요한데 어디 전화해야할지 모르겠음)
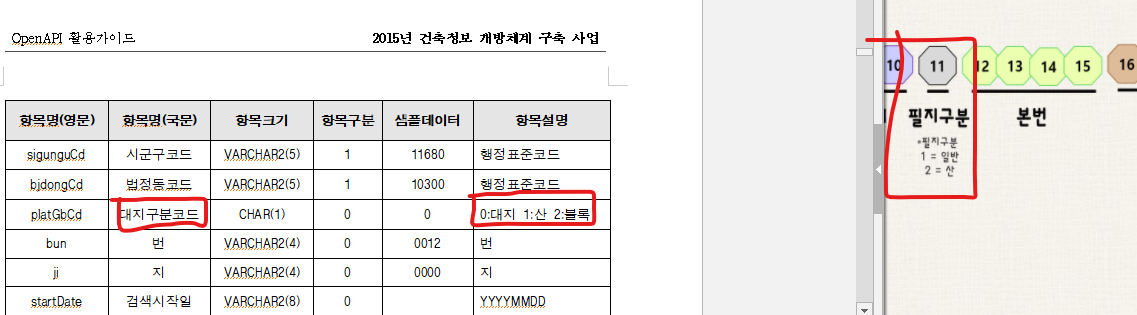
PNU 검색하면 자꾸 부산대 나와서 빡침.
데이터 가져온 결과물 ver.2
필지번호를 빼고 반복문을 돌려봄.
data1=[]
row = []
for sigungu, dong, bun, ji in zip(sigungu, dong,bun, ji):
url="http://apis.data.go.kr/1613000/BldRgstService_v2/getBrRecapTitleInfo?sigunguCd=" + str(sigungu) + "&bjdongCd=" + str(dong) + "&platGbCd=&bun=" + str(bun) + "&ji=" + str(ji) + "&ServiceKey=본인의 인증키"
#print(url)
result=requests.get(url)
soup=BeautifulSoup(result.text, 'lxml-xml')
items=soup.find_all('item')
#print(items)
for item in items:
row.append(parse())
#print(row)
data1 = pd.DataFrame(row)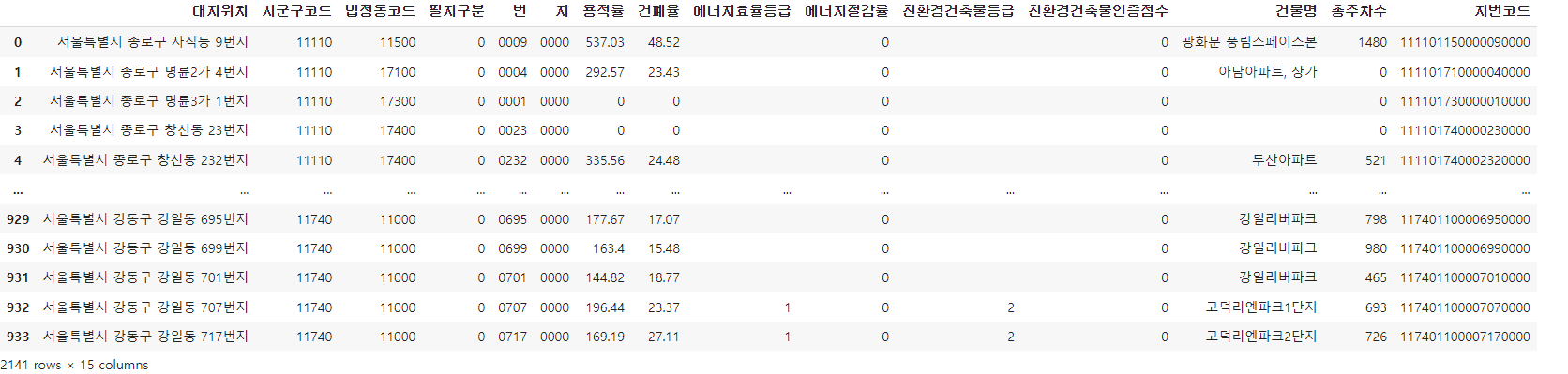
이번에는 일치하는 가져온 데이터가 2141개인 것을 볼 수 있다.
실거래가와 건축물대장 JOIN
뭔가...꺼림칙 하긴 하지만 실거래가 데이터프레임과 조인해본다

건물명_x가 실거래가에 있던 속성, 건물명_y가 건축물대장에서 가져온 속성이다.
필지번호를 빼고 넣은 지번코드의 건물명이 일치하는 것을 볼 수 있다.
아니 이거 쓰는거 왜이렇게 시간 많이 걸리고 힘들어
이것저것 다 생략했는데도 쓰는거 너무 힘들다.
나는 과연...포스팅을 몇개나 올릴 수 있을까...
