이 포스팅은 김영한 강사님의 '모든 개발잘르 위한 http 웹 기본지식' 을 기반으로 정리한 포스팅입니다.
API URI 설계
리소스 식별, URI 계층 구조 활용
- 회원목록조회 /members
- 회원 조회 /members/{id}
- 회원 등록 /members/{id}
- 회원 수정 /members/{id}
- 회원 삭제 /members/{id}
-> 어떻게 구분하지?
리소스와 행위를 분리
-> 가장 중요한 것은 리소스를 식별한느 것
- URI는 리소스를 판별만한다.
- 리소스와 해당 리소스를 대상으로 하는 '행위' 분리
* 리소스 : 회원- 행위 : 조회, 등록, 삭제 ,변경
- 리소스는 명사
- 행위는 동사
-> 행위는 메서드로 구분
행위는 어떻게 구분할까??
HTTP 메서드 종류
MAIN
- GET : 리소스 조회
- POST : 요청 데이터 처리, 주로 등록에 사용
- PUT : 리소스ㄹ르 대체 , 해당 리소스가 없으면 생성
- PATCH: 리소스 부분 변경
- DELETE : 리소스 삭제
기타
- HEAD : GET 과 동일하지만 메시지 부분을 제외학, 상태줄과 헤더만 반환
- OPTIONS: 대상 리소스에 대한 통신 가능을 설명 -> CORS 에서 사용
- CONNECT: 대상 리소스로 식별되는 서베에 대한 터널을 설정
- TRACE : 대상리소스에 대한 경로를 따라 메시지 루프백 테스트르 수행
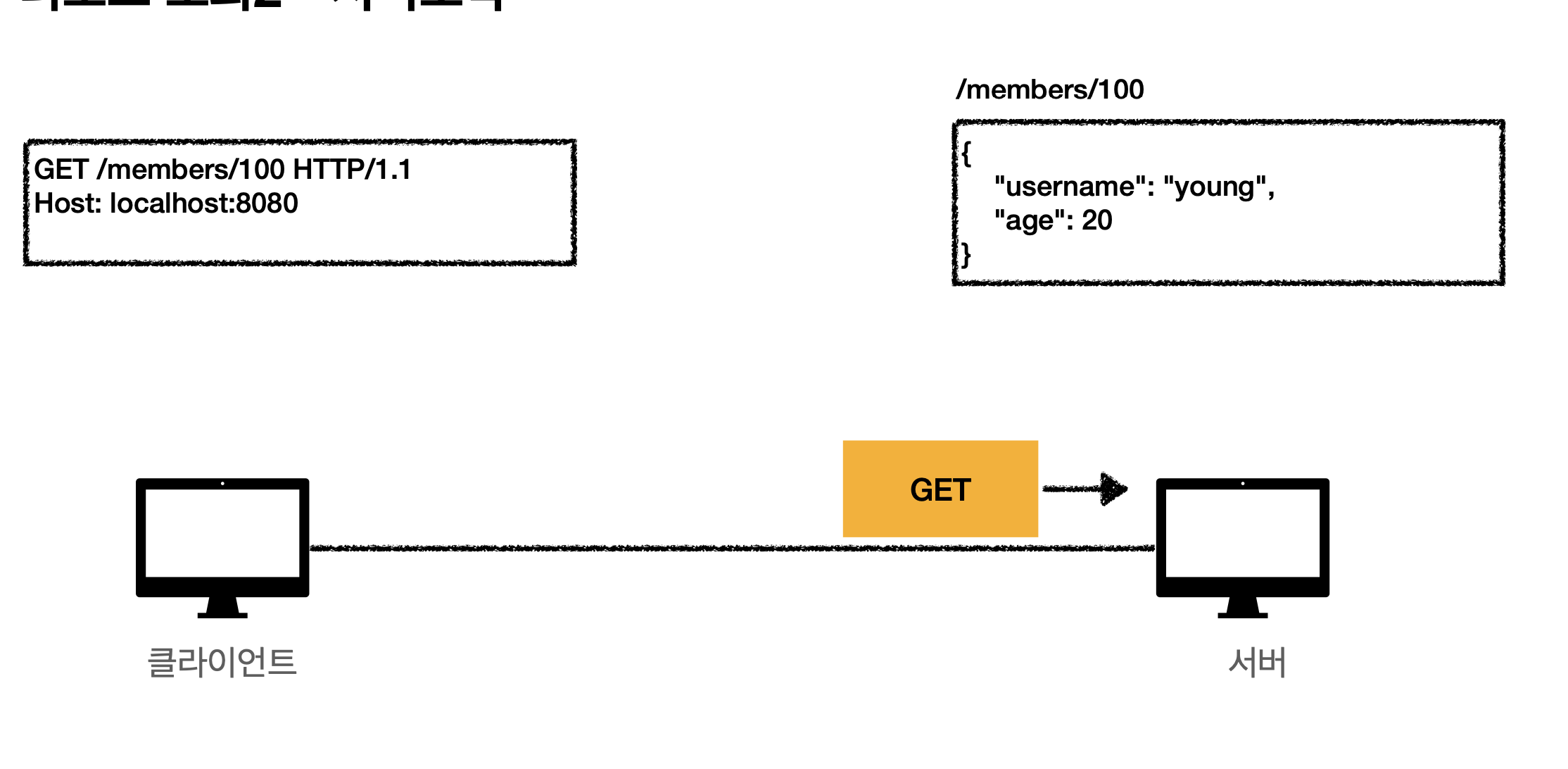
GET
- 주로 리소스를 조회
- 서버에 전달하고 싶은 데이터는 Query( 쿼리 파라미터, 쿼리 스트링)을 통해서 전달한다.
- 메시지 body를 통해서 데이터 전달은 가능하나, 지원하지 않는 곳이 많으므로 추천안함.
리소스 조회
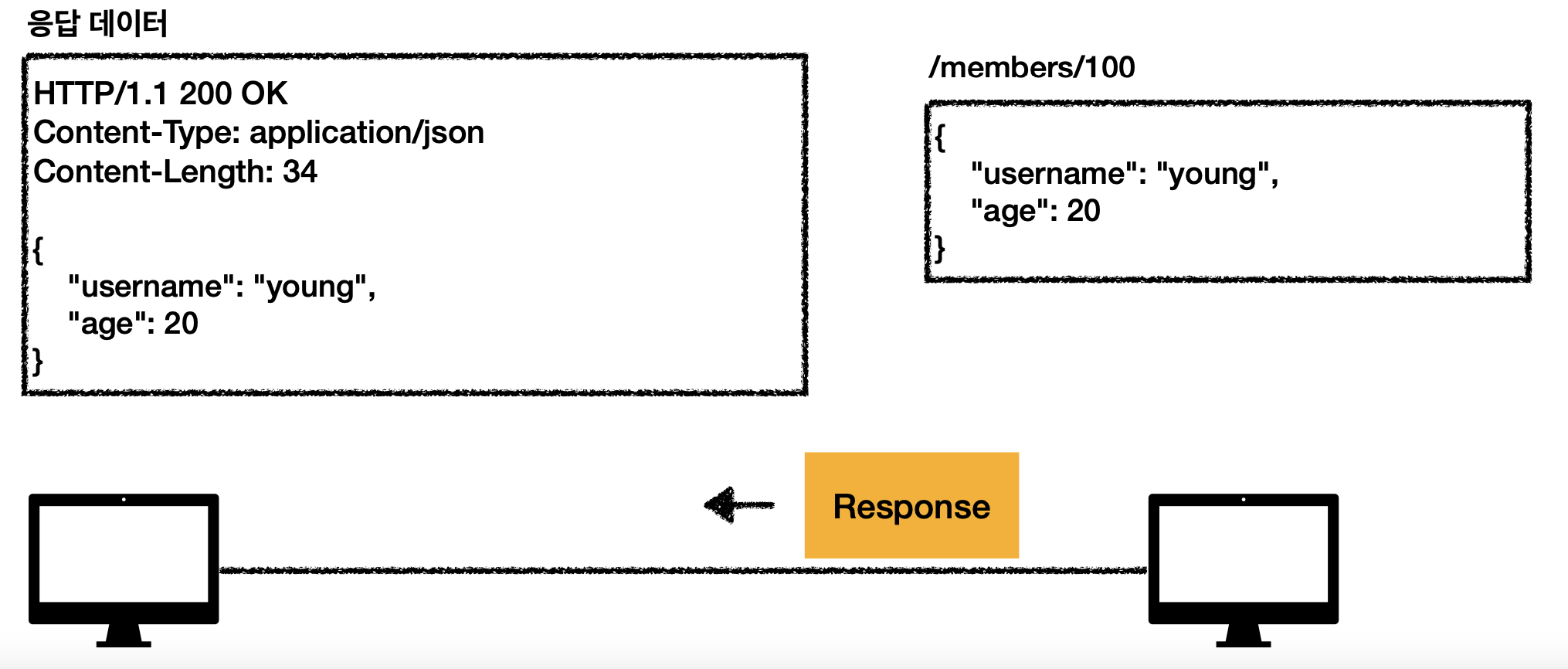
응답 데이터
POST
- 요청데이터 처리
- 메시지 body를 통해 서버로 요청 데이터 전달
- 서버는 요청데이터를 처리
- 메시지 body를 통해 들어온 데이털르 처리하는 모든 기능을 수행한다.
- 주로 전달된 데이터로 신규 리소스 등록(singup) , 프로세스 처리에 사용
요청 데이터를 어떻게 처리한다는 뜻일까?
- 스펙: POST 메서드는 대상 리소스가 리소스의 고유 한 의미 체계에 따라 요청에 포함 된 표현을 처리하도록 요청합니다.
예를 들어 POST는 다음과 같은 기능에 사용됩니다.
예) HTML FORM에 입력한 정보로 회원 가입, 주문 등에서 사용
HTML 양식에 입력 된 필드와 같은 데이터 블록을 데이터 처리 프로세스에 제공
- 게시판, 뉴스 그룹, 메일링 리스트, 블로그 또는 유사한 기사 그룹에 메시지 게시
예) 게시판 글쓰기, 댓글 달기
예) 신규 주문 생성
- 서버가 아직 식별하지 않은 새 리소스 생성
예) 한 문서 끝에 내용 추가하기
- 기존 자원에 데이터 추가
정리: 이 리소스 URI에 POST 요청이 오면 요청 데이터를 어떻게 처리할지 리소스마다 따로 정해야 함 -> 정해진 것이 없음
정리
-
새 리소스 생성(등록)
서버가 아직 식별하지 않은 새 리소스 생성 -
요청 데이터 처리
단순히 데이터를 생성하거나, 변경하는 것을 넘어서 프로세스를 처리해야 하는 경우예) 주문에서 결제완료 -> 배달시작 -> 배달완료 처럼 단순히 값 변경을 넘어 프로세스의 상태가 변경되는 경우 POST의 결과로 새로운 리소스가 생성되지 않을 수도 있음 예) POST /orders/{orderId}/start-delivery (컨트롤 URI) -
다른 메서드로 처리하기 애매한 경우
예) JSON으로 조회 데이터를 넘겨야 하는데, GET 메서드를 사용하기 어려운 경우애매하면 POST
PUT
- 리소스를 대체
* 리소스가 있으면 완전히 대체 -> 쉽게 말해 덮어버림- 리소스가 없으면 새로 생성
POST 와의 차이점
PUT은 클라이언트가 리소스 위치를 알고 URI를 지정한다.
/members/100 -> 100 이 리소스의 위치를 제대로 알고있다는 뜻

PATCH
- 리소스 부분 변경
-> 지원안하는 경우도 있음
-> 지원안하면 POST 사용
무적인가 POST....
DELETE
- 리소스를 제거한다.
HTTP 메서드의 속성
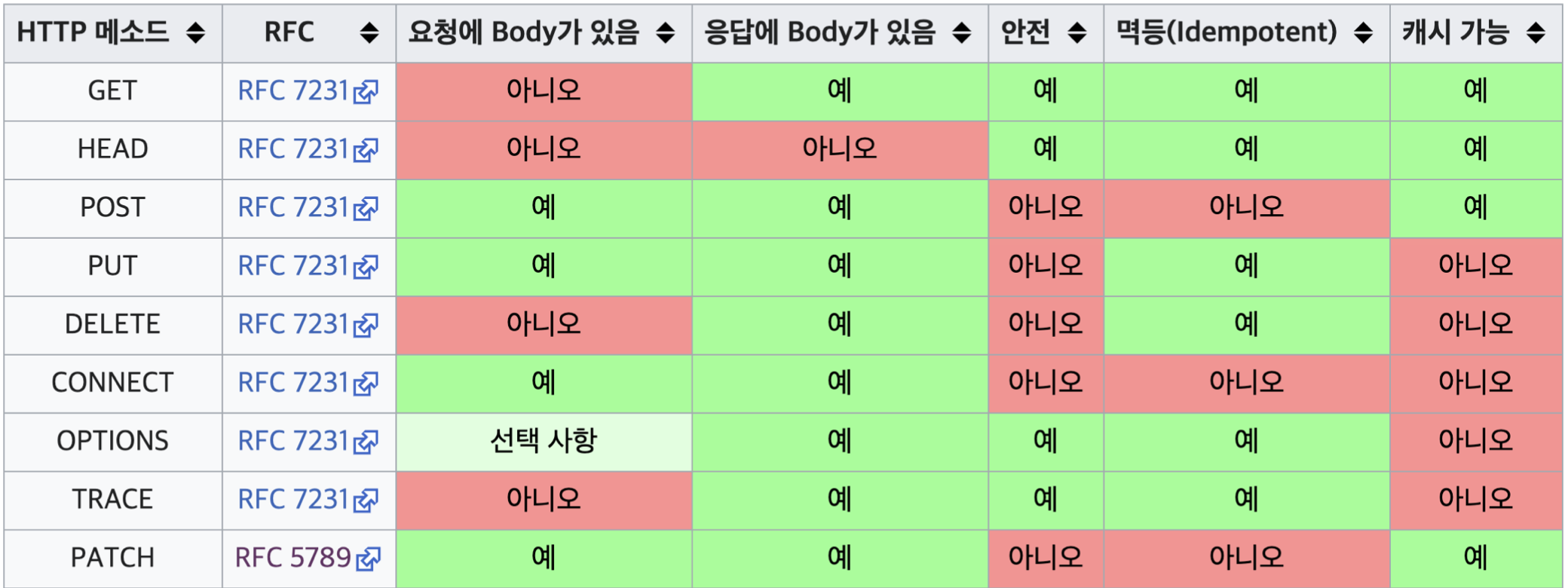
출처: https://ko.wikipedia.org/wiki/HTTP
안전
-
호출해도 리소스를 변경하지않는다.
ex) GET 여러번해도 조회만 할뿐 데이터에 손을 대진 않음 -
계속 호출로 로그가 쌓여서 서버에 부담을 주는건?
-> 안전은 해당 리소스만 고려한다. 즉 그 조회를 했을때만의 상황만 고려한다. 그런 부분까지 고려를 하진 않는다.
멱등(Idempotent)
-
한 번 호출하든 두 번 호출하든 100번 호출하든 결과는 같다!
-
멱등 메서드
- GET : 한번 조회하든, 두번 조회하든 같은 결과 조회
- PUT : 결과를 대체 한다. 여러번 같은 것을 대체해도 결과는 같은 것으로 결정됨
- DELETE : 결과를 삭제한다. 여러번 요청해도 삭제된 결과는 동일
POST: 멱등이 아니다! 두번 호출하면 같은 결제가 중복해서 발생 할 수 있다.
-
활용
- 자동 복구 메커니즘
- 서버가 TIMEOUT 등으로 정상 응답을 못주었을 때, 클라이언트가 같은 요청을 다시 해 도 되는가? 판단 근거
-
Q: 재요청 중간에 다른 곳에서 리소스를 변경해버리면?
사용자1: GET -> username:A, age:20
사용자2: PUT -> username:A, age:30
사용자1: GET -> username:A, age:30 -> 사용자2의 영향으로 바뀐 데이터 조회 -
A: 멱등은 외부 요인으로 중간에 리소스가 변경되는 것 까지는 고려하지는 않는다.
캐시 가능
- 응답 결과 리소스를 캐시해서 사용해도 되는가?
- GET,HEAD,POST,PATCH 가능
- BUT , 실제로는 GET,HEAD 정도만 사용
- POST, PATCH는 본문 내용까지 캐시 키로 고려해야하는데, 구현이 쉽지 않음
