
문제
어떤 나라에는 1번부터 N번까지의 도시와 M개의 단방향 도로가 존재한다. 모든 도로의 거리는 1이다.
이 때 특정한 도시 X로부터 출발하여 도달할 수 있는 모든 도시 중에서, 최단 거리가 정확히 K인 모든 도시들의 번호를 출력하는 프로그램을 작성하시오. 또한 출발 도시 X에서 출발 도시 X로 가는 최단 거리는 항상 0이라고 가정한다.
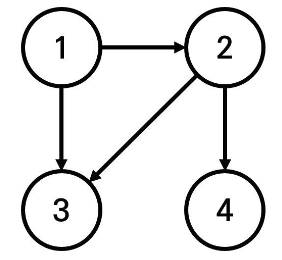
예를 들어 N=4, K=2, X=1일 때 다음과 같이 그래프가 구성되어 있다고 가정하자.
이 때 1번 도시에서 출발하여 도달할 수 있는 도시 중에서, 최단 거리가 2인 도시는 4번 도시 뿐이다. 2번과 3번 도시의 경우, 최단 거리가 1이기 때문에 출력하지 않는다.
입력
첫째 줄에 도시의 개수 N, 도로의 개수 M, 거리 정보 K, 출발 도시의 번호 X가 주어진다. (2 ≤ N ≤ 300,000, 1 ≤ M ≤ 1,000,000, 1 ≤ K ≤ 300,000, 1 ≤ X ≤ N) 둘째 줄부터 M개의 줄에 걸쳐서 두 개의 자연수 A, B가 공백을 기준으로 구분되어 주어진다. 이는 A번 도시에서 B번 도시로 이동하는 단방향 도로가 존재한다는 의미다. (1 ≤ A, B ≤ N) 단, A와 B는 서로 다른 자연수이다.
출력
X로부터 출발하여 도달할 수 있는 도시 중에서, 최단 거리가 K인 모든 도시의 번호를 한 줄에 하나씩 오름차순으로 출력한다.
이 때 도달할 수 있는 도시 중에서, 최단 거리가 K인 도시가 하나도 존재하지 않으면 -1을 출력한다.
입출력 예제
풀이
heap 다익스트라를 사용한 풀이
출발점을 파라미터로 지정하고 dijkstra 함수를 실행한다.
distances 딕셔녀리는 start에서 갈 수 있는 지점을 key(vertex)로,
그 지점까지 갈 수 있는 최소 거리를 value로 가진다.
메서드 초기 시작 시 모두 무한대 값을 지정한다.
출발점에서 출발점으로 가는 경로는 0이기 때문에 0으로 지정한다.그리고 탐색 시작 지점인 출발점을 heap에 넣는다.
이때 heap에 (현재까지 이동한 거리, 현재 위치) 형태의 튜플을 넣는다.
heap에 튜플이나 배열을 넣을 경우 0번째 인덱스를 기준으로 정렬되기 때문에
순서가 매우 중요하다.
heapq.heappop(heap) 으로 현재까지 이동한 거리가 가장 짧은 정보를 빼서
cur_distance와 cur에 할당한다.
distance에는 출발지점에서 각 노드까지 걸리는 최소 거리의 과거 정보를 가지고 있다.
따라서 업데이트 될 지점의 거리 정보가 과거 거리 정보보다 크면 방문(사용)하지 않는다.(continue)
업데이트 될 지점의 거리 정보가 과거 거리 정보보다 작거나 같다면
방문한 노드에서 인접한 노드(다음 방문 대상 노드)의 정보를 순회한다.방문한 노드에서 다음 방문 대상의 노드까지 가는데 거리는 거리를 계산한다.
다음 방문 대상까지 가는 거리= 방문대상까지 오는데 거리 + 방문 노드에서 다음 방문 대상 노드까지 가는데 거리
next_distance = cur_distance + weight다음 방문 대상까지 가는 거리(next_distance)가 과거 이력보다 작으면 업데이트하고
방문할 예정인 곳을 저장하는 heap에 heapq.heappush() 메서드를 사용해서 넣는다.
이 과정을 heap이 빌때까지 반복하면
출발 지점에서 각 노드까지 도달할 수 있는 최소거리가 distances 딕셔너리에 저장된다.import heapq import sys INF = int(1e9) sys.stdin = open("data.txt", 'r') N, M, K, X = map(int, sys.stdin.readline().rstrip().split(" ")) graph = {start: {} for start in range(1, N + 1)} for _ in range(M): start, end = map(int, sys.stdin.readline().rstrip().split(" ")) graph[start][end] = 1 def dijkstra(start): distances = {vertex: INF for vertex in range(1, N + 1)} distances[start] = 0 heap = [(0, start)] while heap: cur_distance, cur = heapq.heappop(heap) if distances[cur] < cur_distance: continue for neighbor, weight in graph[cur].items(): next_distance = cur_distance + weight if next_distance < distances[neighbor]: distances[neighbor] = next_distance heapq.heappush(heap, (next_distance, neighbor)) return distances def solution(N, M, K, X, graph): distances = dijkstra(X) count = 0 for vertex, distance in distances.items(): if distance == K: print(vertex) count += 1 if count == 0: print(-1) return solution(N, M, K, X, graph)
회고
시간 복잡도 계산heap을 사용한 다익스트라 알고리즘의 시간 복잡도는 O(NlogN) 이다.
N 이 최대 300,000 이기 때문에 300,000 * 18.19 로 5,457,000 이다.
파이썬에서 heap은 기본적으로 min heap 이며,
배열일 경우 첫번째 요소를 기준으로, 딕셔너리의 경우 Key 값을 기준으로 정렬된다.기준점을 몰라서 계속 틀렸다.
주의하자..

잘봤습니다.