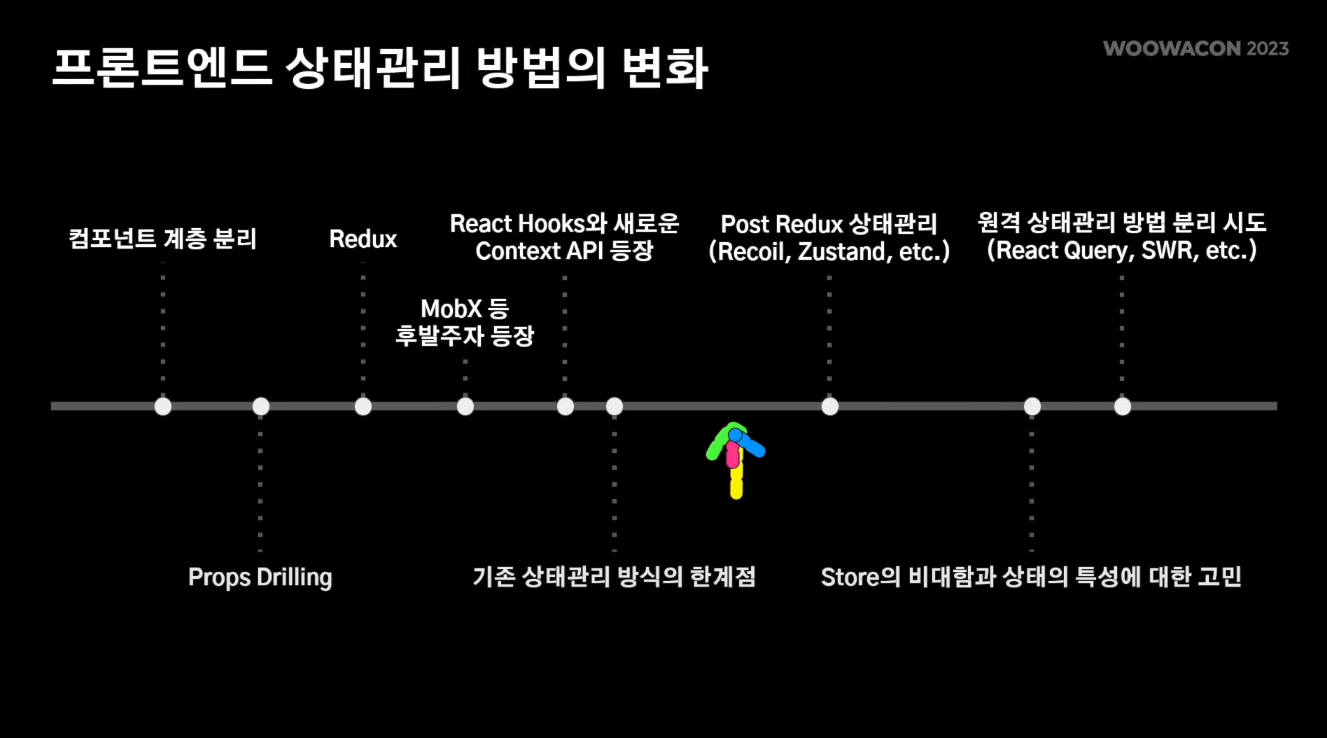
이번 우아콘 영상을 계기로 리액트 패턴의 역사를 정리해본다. 위 이미지에 대략적으로는 나와있지만, 찾아보면 아래와 같은 흐름으로 발전해왔다고 한다.
MVC, MVVM -> Component -> Container-Presenter -> Flux -> Redux -> Mobx -> ContextAPI -> React Hooks -> React-Query -> Zustand -> Recoil, Jotai, Valtio..
React Pattern History
MVC
Old Fashioned, Classic pattern.. (작성중)
Container-Presenter Architecture
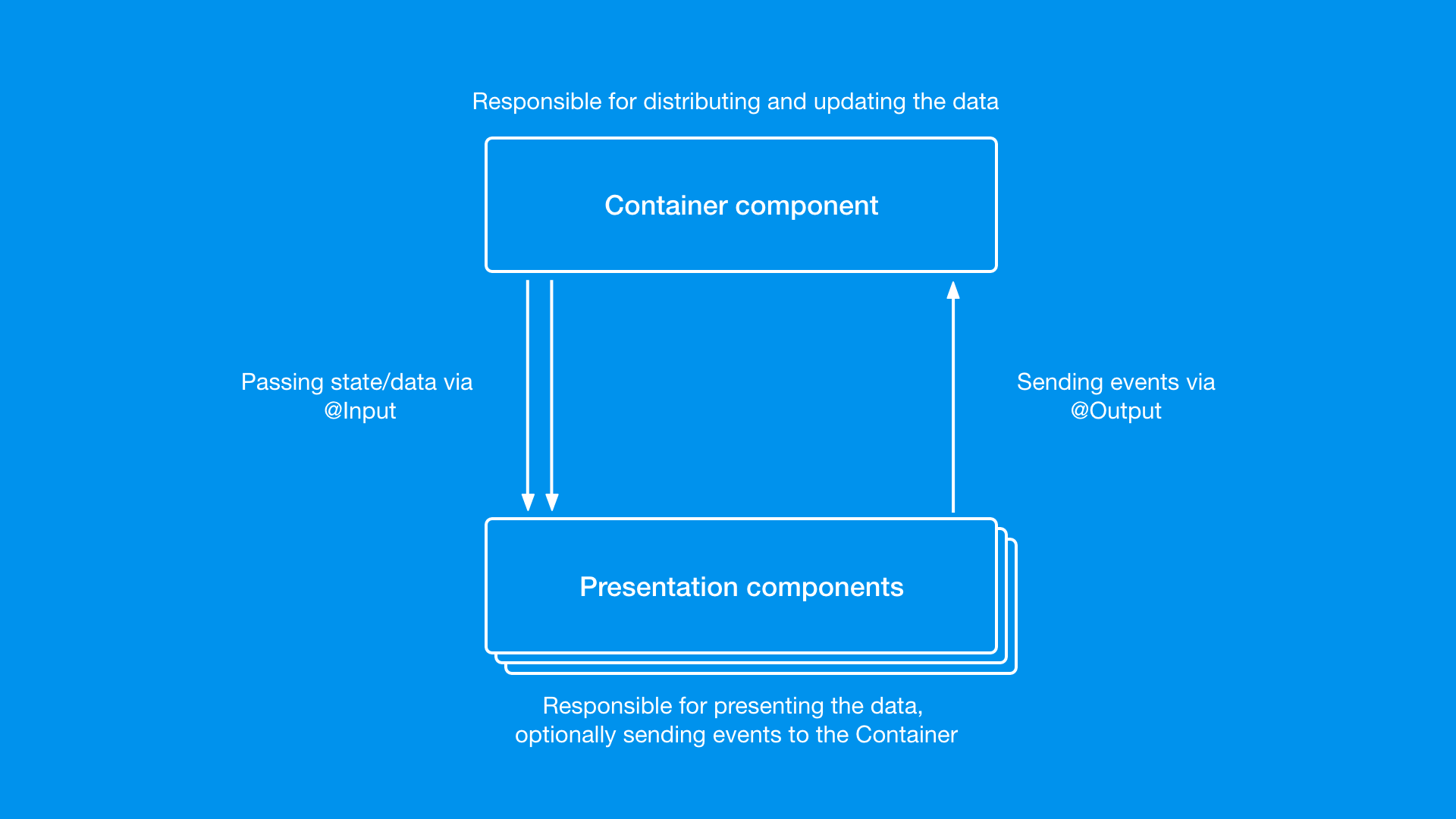
리액트의 베이스는 관심사를 재사용가능한 컴포넌트로 쪼개 분리하고, 필요에 따라 조립해 웹 서비스를 조립하는 패턴이다.
- 비즈니스 로직을 관장하는 컴포넌트는 Container Component
- 데이터만 뿌려주는 UI와 같은 컴포넌트는 Presenter Component
뼈대가 되는 아키텍쳐에서 컴포넌트 구조가 복잡해지면, 부모가 자식에게 데이터를 전달하기 위해 props를 계속 전달하며 수많은 props가 쌓이는 props drilling이 발생한다.
이에 따라 발생한 단점
- 컴포넌트의 재사용과 독립성의 지나친 강조
- Component간 데이터 전달이 어렵다
- Model의 관리가 파편화 된다
- Props drilling이 발생한다
이를 해결하기 위해 "Flux Architecture"가 등장하게 된다.
Flux Architecture
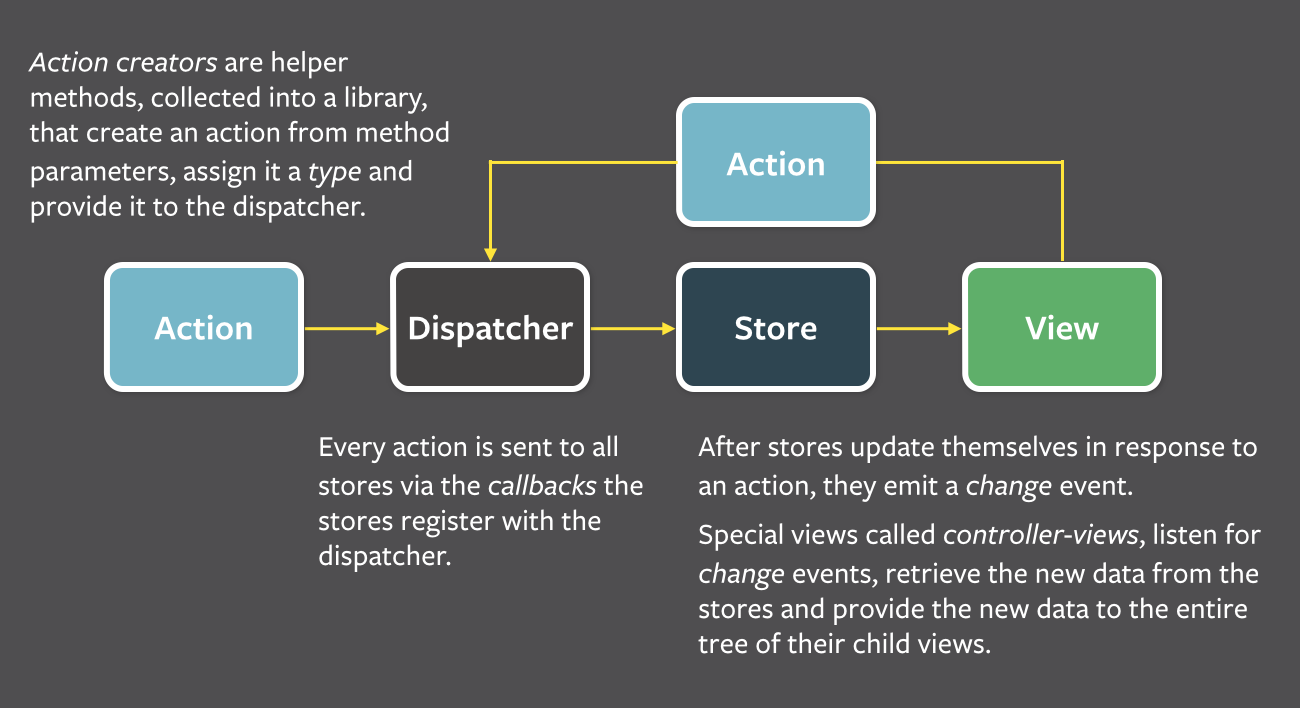
Flux는 meta(구 facebook)에서 클라이언트사이드 웹 어플리케이션을 만들기 위해 사용했던 어플리케이션 아키텍쳐이다. 이미지에서 보이듯 Action -> View로 이어지는 단방향 데이터 흐름을 활용해 뷰 컴포넌트를 구성하는 React를 보완하는 역할을 한다.
Flux application은 3가지 메인 파트를 갖고 있다 : dispatcher, stores, views (React components). 이는 MVC pattern과 유사하지만, Flux엔 Contoller가 존재하지 않는 다는 점에서 다르다.
Flux의 구조는 단방향이다. View에서 Action을 호출하면 Dispatcher를 통해 Store에 Data가 보관되고 이 Data는 다시 View로 전달된다.
이 구조는 함수형 반응 프로그래밍을 다시 재현하는 것을 쉽게 만들거나 데이터-흐름 프로그래밍, 흐름 기반 프로그래밍을 쉽게 만들어준다. 어플리케이션 데이터 흐름이 양방향 바인딩이 아닌 단방향이기 때문이다. 어플리케이션의 상태는 오직 store에 의해서만 관리되고 어플리케이션의 다른 부분들과는 완전히 분리된다. store 사이에 의존성이 발생하더라도 엄격한 위계하에 dispatcher에 의해 동기적으로 관리된다.
State Management
이렇게 기존 아키텍쳐에서 완전히 분리하면서 이 개념을 State Management(상태 관리)라고 부르게 되었다. 상태관리의 개념을 종합해서 기존 패턴과의 차이점을 정리하면 아래와 같다.
공통적으로 사용되는 비지니스 로직의 Layer와 View의 Layer를 완전히 분리되어 상태관리라는 방식으로 관리한다.
각각의 독립된 컴포넌트가 아니라 하나의 거대한 View 영역으로 간주한다.
둘 사이의 관계는 Action과 Reduce라는 인터페이스로 분리한며 Controller는 이제 양방향이 아니라 단반향으로 Cycle을 이루도록 설계한다.
대표적인 Flux 패턴의 상태관리 라이브러리는 Redux와 MobX가 존재한다.
하지만 Flux 패턴의 상태관리 역시 사용자가 늘고 시간이 지나며 단점들이 드러났다.
아래는 Redux의 대표적인 단점들이다.
- store 뿐 아니라 비동기 처리 역할도 확장되면서 어플리케이션의 복잡성이 높아진다.
- 스토어 자체를 관리하기 위한 모든 action을 dispatcher에 등록해야 한다.
- redux-thunk, redux-saga, redux toolkit과 같은 추가 미들웨어 library를 필요로 한다.
이런 단점을 보완하기 위해 recoil, contextAPI 등이 도입되었다.
리덕스 스터디 기록
Client State Management
React Hooks, ContextAPI
앞서 Redux와 Flux 패턴에서 지적한 문제점들을 극복하기 위해 React18부터 ContextAPI가 도입되었다.
그럼 Context는 왜 도입되었을까? 공식문서 참조에 따르면 가장 큰 목적은 props drilling을 해결하기 위해서이다. Context는 부모 컴포넌트가 하위 트리 전체에 데이터를 전달할 수 있도록 도와준다.

ContextAPI core concept
다음으로 공식 문서에 따르면 ContextAPI는 아래와 같은 기능을 한다.
- tree의 깊은 곳까지 데이터를 전달한다
- context를 통해 전달된 데이터를 업데이트한다
- provider가 없더라도
default value를 사용할 수 있다- tree의 일부분에서 사용되는 context를 overriding할 수 있다
- context와 useMemo의 사용을 통해 리렌더링을 최적화할 수 있다
위의 기능 목록을 살펴보면 React 자체 Hook으로서 큰 역할을 해주는 것처럼 보인다. 사용 시에도 React의 useState, useEffect등과 함께 상태 관리를 편리하게 해준다. 하지만 이에 따른 단점 역시 존재한다.
- 작은 규모의 앱은 괜찮지만, 큰 프로덕트에서 context값이 변경되면 useContext가 리렌더링을 유도한다. 이는 React.memo를 사용하거나 context 객체를 분리하여 해결할 수도 있다.
Recoil

Recoil은 Redux와 Context가 가지는 단점들을 해결하고 React다운 개발을 위해 등장한 상태관리 라이브러리이다. 공식문서 motivation 참조를 보면 제작 동기를 알 수 있다.
- 컴포넌트의 상태는 공통된 상위요소까지 끌어올려야만 공유될 수 있으며, 이 과정에서 거대한 트리가 다시 렌더링 되는 효과를 야기하기도 한다.
- Context는 단일 값만 저장할 수 있으며, 자체 소비자(consumer)를 가지는 여러 값의 집합을 담을 수는 없다.
- 이 두 가지 특성이 트리의 최상단(state가 존재하는 곳)부터 트리의 말단(state가 사용되는 곳)까지의 코드 분할을 어렵게 한다.
Recoil은 이런 단점을 개선하고자 atoms와 selectors로 구성된 data-flow graph 기반 상태관리를 제안했다. 상태 변화는 그래프의 뿌리인 atom에서 시작해 selector를 거쳐 컴포넌트로 흐른다.
Recoil core concept
- 우리는 공유상태(shared state)도 React의 내부상태(local state)처럼 간단한 get/set 인터페이스로 사용할 수 있도록 boilerplate-free API를 제공한다. (필요한 경우 reducers 등으로 캡슐화할 수도 있다)
- 우리는 동시성 모드(Concurrent Mode)를 비롯한 다른 새로운 React의 기능들과의 호환 가능성도 갖는다.
- 상태 정의는 점진적이고(incremental) 분산되어 있기 때문에, 코드 분할이 가능하다.
상태를 사용하는 컴포넌트를 수정하지 않고도 상태를 파생된 데이터로 대체할 수 있다.
파생된 데이터를 사용하는 컴포넌트를 수정하지 않고도 파생된 데이터는 동기식과 비동기식 간에 이동할 수 있다.- 우리는 탐색(Navigation)을 일급 객체 개념으로 취급할 수 있고 심지어 링크에서 상태 전환을 인코딩할 수도 있다.
- 전체 애플리케이션 상태를 하위 호환되는 방식으로 유지하기가 쉬우므로, 유지된 상태는 애플리케이션 변경에도 살아남을 수 있다.
이러한 Recoil의 등장 배경에 따라, Recoil의 Core concept인 Atom과 Selector를 살펴보자. Atoms(공유상태)는 상태 단위로 업데이트와 구독이 가능하다. atom이 업데이트되면 구독된 컴포넌트는 새로운 값을 반영해 렌더링한다.
Selector는 atoms나 다른 selectors를 입력으로 받는 순수 함수(Pure function)이다. 상위 aotms 또는 selectors가 업데이트되면 하위 selectors도 재실행된다. 컴포넌트는 이런 selectors를 atoms처럼 구독할 수 있으며 selectors가 변경되면 컴포넌트들도 재렌더링된다.
Server State Management
client state를 다루면서 -특히 Redux와 관련하여- 서버 데이터와의 동기화나 비동기 로직을 처리하는 과정에서 상태관리 매니저가 비대해졌다. thunk와 toolkit과 같은 개념들은 개발자의 허들을 높이고 코드의 분할과 가독성을 비효율적으로 만들었다. 이런 문제점들을 해결하기 위해 Server State Management도 등장했다. 그중 하나인 React-Query를 살펴보자.
React-Query
React-Query의 공식문서에 따르면 자기 자신을 "React Query is hands down one of the best libraries for managing server state. It works amazingly well out-of-the-box, with zero-config, and can be customized to your liking as your application grows." 라고 소개하고 있다. Server State Management 답게, 기능은 아래와 같이 정리할 수 있다.
- API Fetching
- Synchronizing and update server state
- caching
그럼 다음으로 React-Query의 core concept를 살펴보자.
React-Query core concept
React query의 core concept은 3가지 이다.
Queries
query는
unique key에 묶여있는 비동기 선언적 의존성입니다. query는 server로부터 data를 fetch하기 위한 method에 기반한 Promise와 사용할 수 있습니다. 만일 Delete나 Put, Patch등의 method로 server data를 수정해야하는 경우,Mutations를 대신 사용합니다.
query를 component나 custom hook에서 subscribe하고 싶은 경우, 유니크한 queryKey와 promise를 반환하는 queryFn을 인자로 넘깁니다.
import { useQuery } from '@tanstack/react-query'
function App() {
const result = useQuery({ queryKey: ['todos'], queryFn: fetchTodoList })
}Mutations
query와 다르게,mutation은 보통 데이터의 create, update, delete 메소드 혹은 서버의 side-effect를 위해 사용됩니다. 이러한 목적하에 TanStack Query는useMutationhook을 지원합니다.
기본 사용법은 아래와 같다. 아래는 server에 새로운 todo를 작성해 추가하는 예시이다.
function App() {
const mutation = useMutation({
mutationFn: (newTodo) => {
return axios.post('/todos', newTodo)
},
})
return (
<div>
{mutation.isPending ? (
'Adding todo...'
) : (
<>
{mutation.isError ? (
<div>An error occurred: {mutation.error.message}</div>
) : null}
{mutation.isSuccess ? <div>Todo added!</div> : null}
<button
onClick={() => {
mutation.mutate({ id: new Date(), title: 'Do Laundry' })
}}
>
Create Todo
</button>
</>
)}
</div>
)
}
여기서 mutations가 말하는 sever side-effect란 무엇일까?
mutation side-effect
아래는 sandbox와 함께 React-Query의 개념을 익혀볼 수 있는 챌린지 사이트의 링크이다.
프로젝트나 실무에 적용하기 전에 학습해보자~!
React-Query challenges
Usage Example
Zustand & React-Query
Redux의 단점들을 극복하고, Server State 관리의 목적을 위해 먹팟 프로젝트에선 Zustand와 React-Query를 조합해 사용했어요.
Server side state management
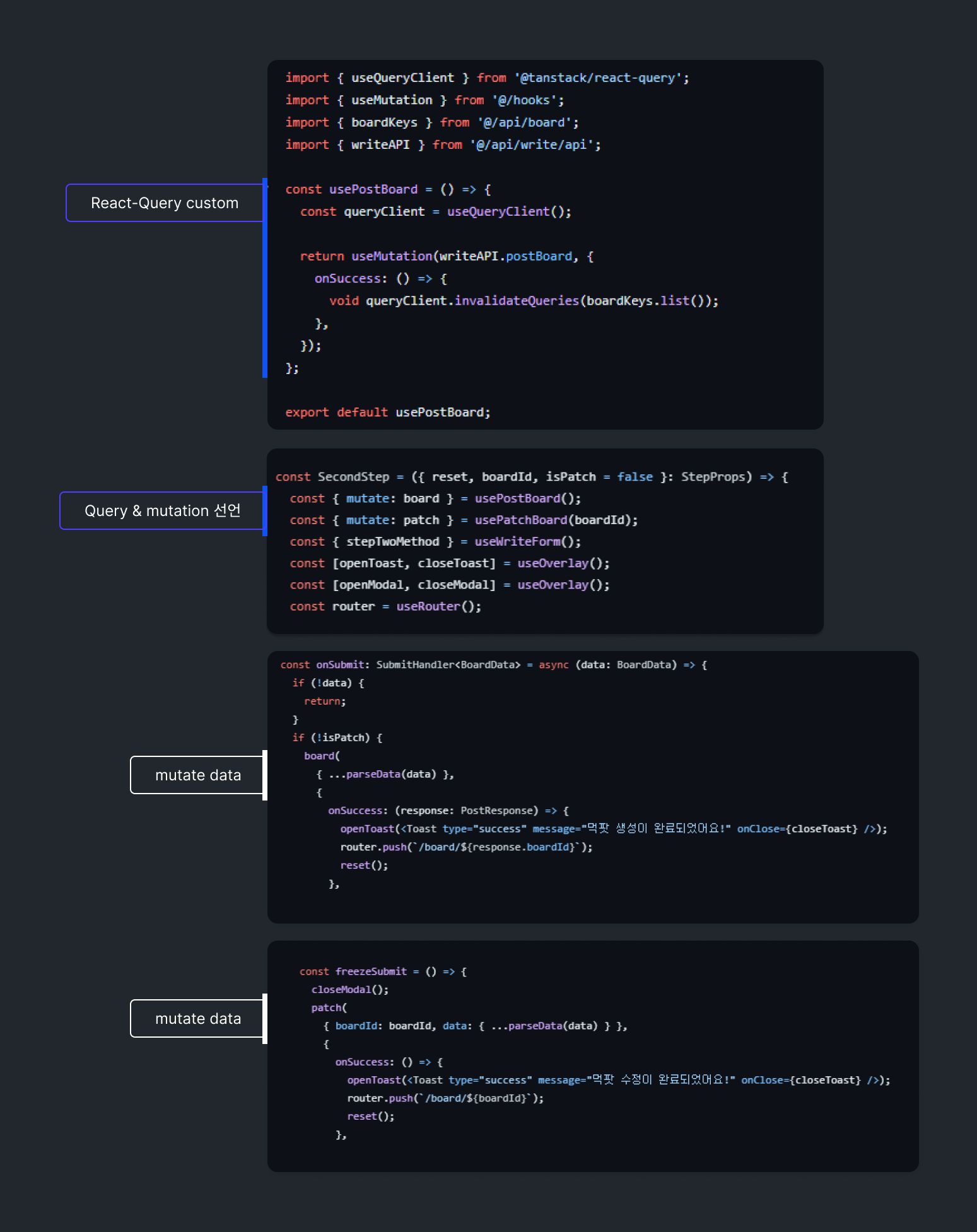
Client state management