
네트워크 계층
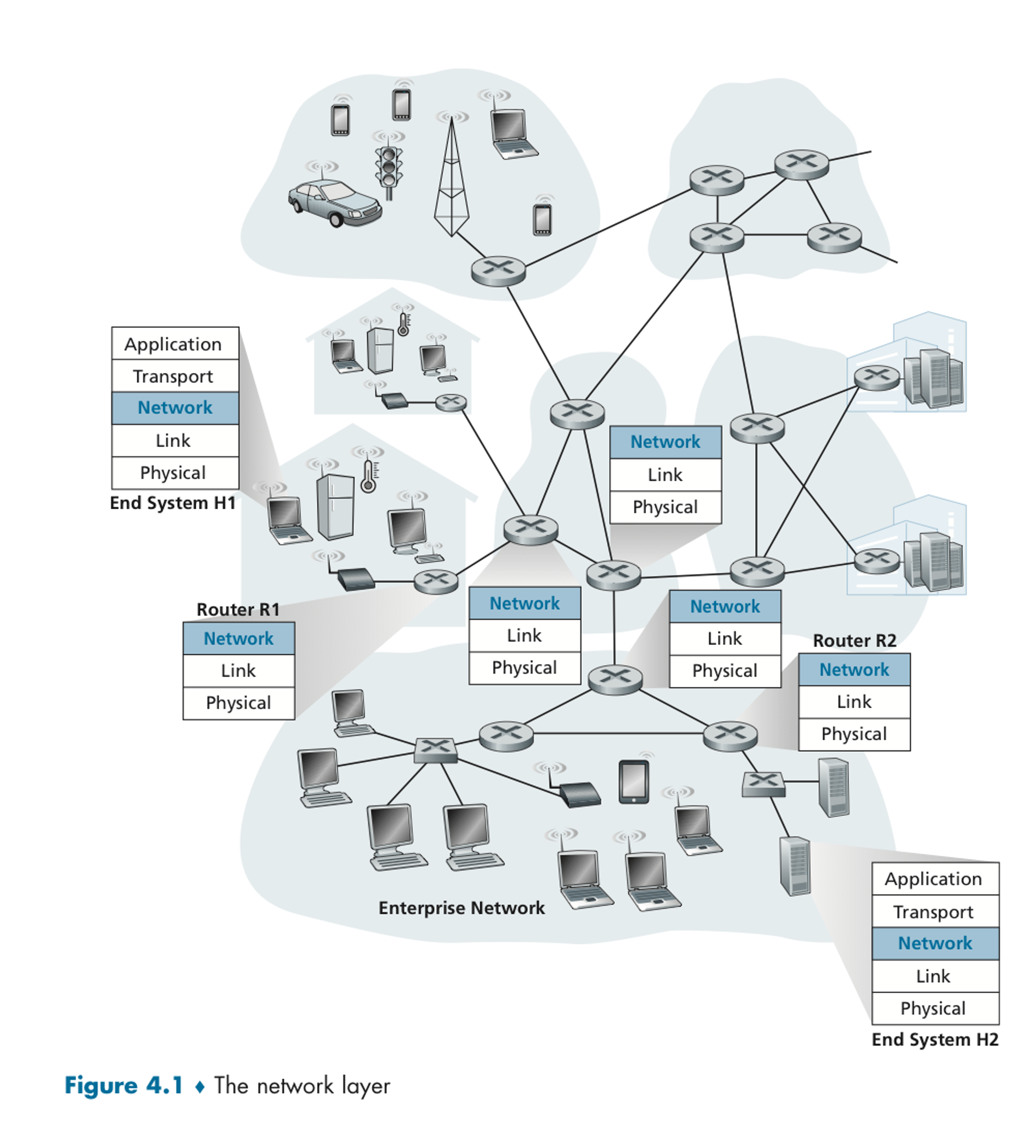
Forwarding
packet이 라우터의 input link에 도달했을 때, 라우터는 패킷을 적절한 output link로 전송시켜야 한다.
Routing
Router 라우터란?
Router에는 여러개의 인터페이스가 존재한다. 각각의 Interface의 IP 주소의 subnet은 각기 다 다르다. 즉 다른 말로, subnet의 교집합이라고 말할 수 있다. Router의 구조도는 아래와 같다.
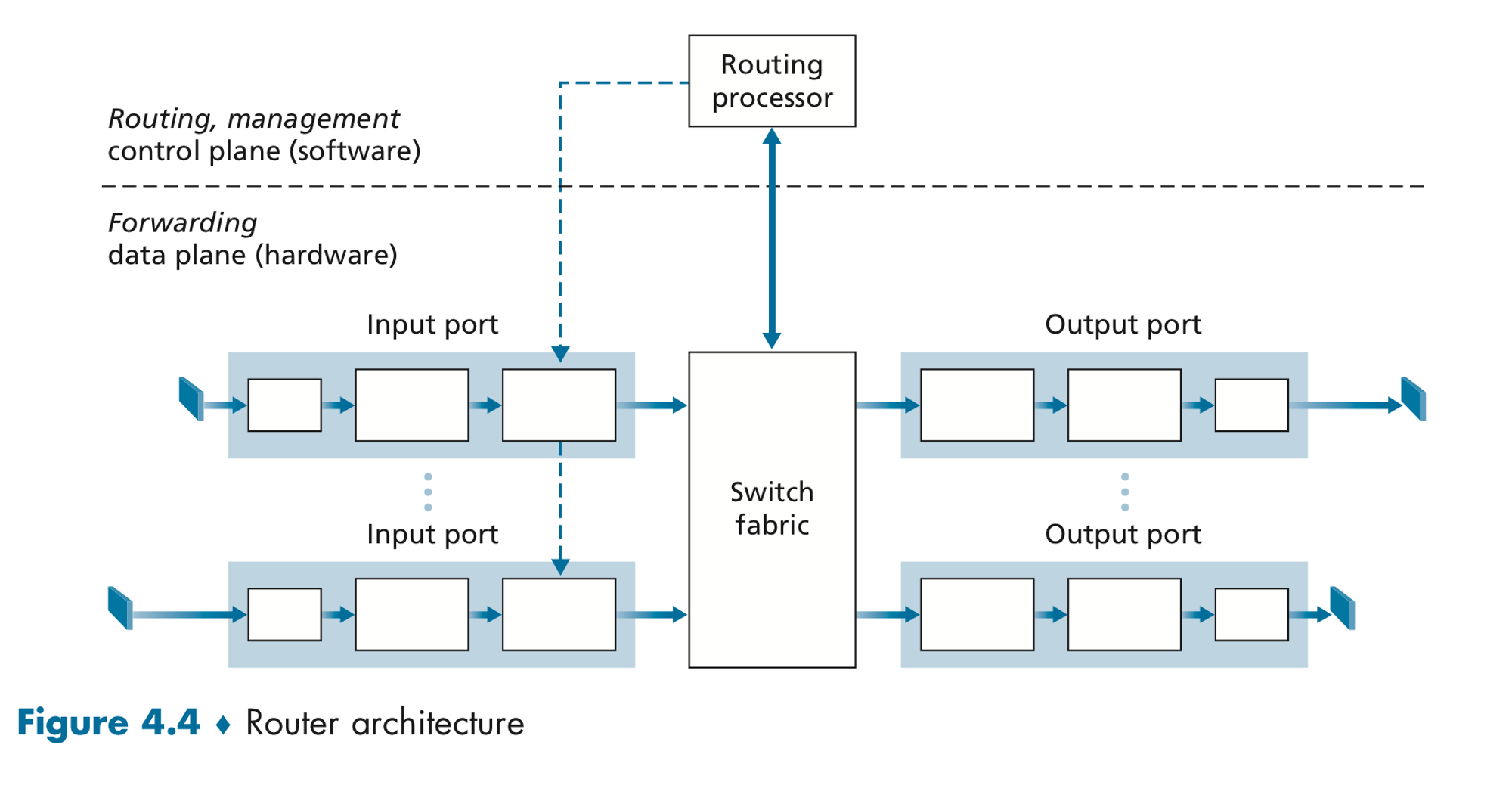
Routing processor: Forwarding table을 만들고 각각의 input port에 table을 저장한다.Input port: 만들어져있는 table을 읽고 들어온 input data forward
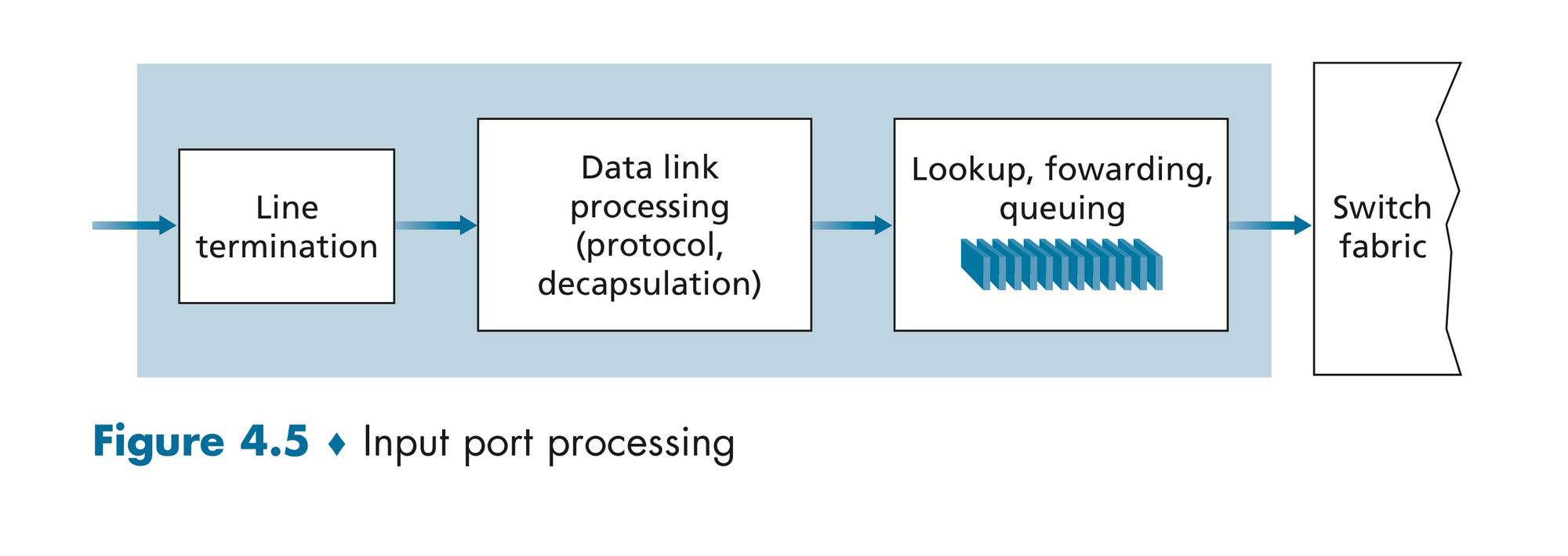
Input port를 자세히 들여다보면 위 그림과 같다. 들어온 data를 들여다보고, data forward를 위한 entry matching이 일어나게 된다. 이때, data entry가 forward 처리속도 보다 빠르다면, 어쩔 수 없이 queuing이 발생한다.
이를 최대한 방지하기 위해, 독립적이로 만들어진 Forward table들이 Input port마다 저장되어 병렬적으로 빠르게 실행한다.
IP Address
IPv4 Datagram

IP 주소 계층화
계층화의 장점 : prefix가 같으면 같은 네트워크에 속한다. 즉, 라우터에 들어가는 forwarding table이 같아지면서 단순화되어 매칭도 쉬워진다.
- Network ID를 24bit로 제한했을 때의 단점
: 2^8인 256개만이 Host ID를 서포트할 수 있다. 따라서, 호스트 크기가 큰 경우 prefix를 줄이고 hostID 크기를 키우기도 한다.
즉, prefix (networkID)와 hostID는 고정되어있지 않고 유연하게 지원할 수 있다.
IP fragmentation
링크 계층 프레임이 전달할 수 있는 최대 데이터 양을 MTU(Maximum Transmission Unit)라고 한다. MTU 제한에 따라, IP packet이 링크로 전달될 수 있도록 단편화가 일어난다. 이때, IP header에 fragment 분할 정보를 같이 전송하여, 추후 reassemble이 가능하도록 한다.
IP header에 fragement 단편화를 위해 아래와 같은 field들이 존재한다.
ID, 16bits: 각 조각이 동일한 데이터그램에 속하면 같은 일련번호를 공유함flag, 3bits: 분열의 특성을 나타내는 플래그- 첫번 째 bit : 미사용 (항상 0)
- 두번 째 bit : DFbit (Don't Fragment, 0이면 Fragmentation 가능 / 1은 불가능)
- 세번 째 bit : MF bit (More Fragment)
- 현재의 조각이 마지막이면 0
- 더 많은 조각이 뒤에 계속 있으면 1
offset, 13 bits: 8 Byte 단위로 최초의 fragment로부터 어떤 곳에 붙여야하는지 위치를 나타냄
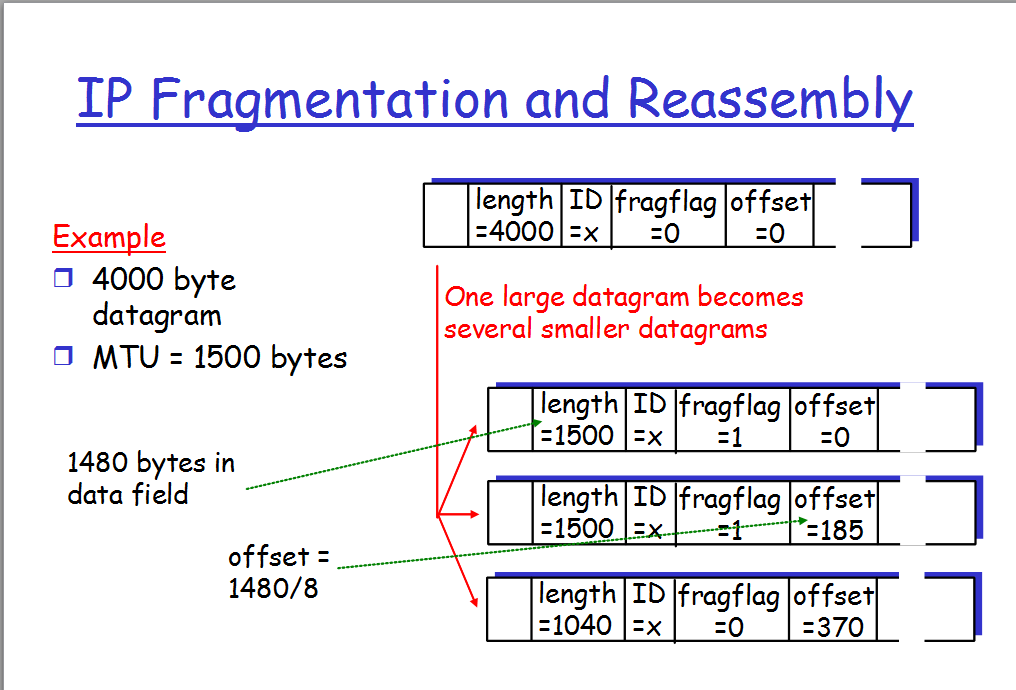
예시로, 4000Byte의 Datagram이 존재하고 MTU가 1500Byte라고 하자. 그렇다면 실제 data payload 크기는 4000 - 20 (header) = 3980 Byte일 것이다. 단편화 과정을 나타내면 아래와 같다.
- MTU가 1500 이므로, 동일한 헤더를 가진 3개의 Fragment로 분할하자.
20(header)Byte + 1480(data) Byte,20(header)Byte + 1480(data) Byte,20(header)Byte + 1020(data) Byte세 가지의 Fragment가 분할된다.- reassemble 과정에서 변환할 수 있도록, 원래 데이터에서의 시작지점인 offset field를 작성한다.
IPv6?
Transitioning IPv4 to IPv6
Subnet
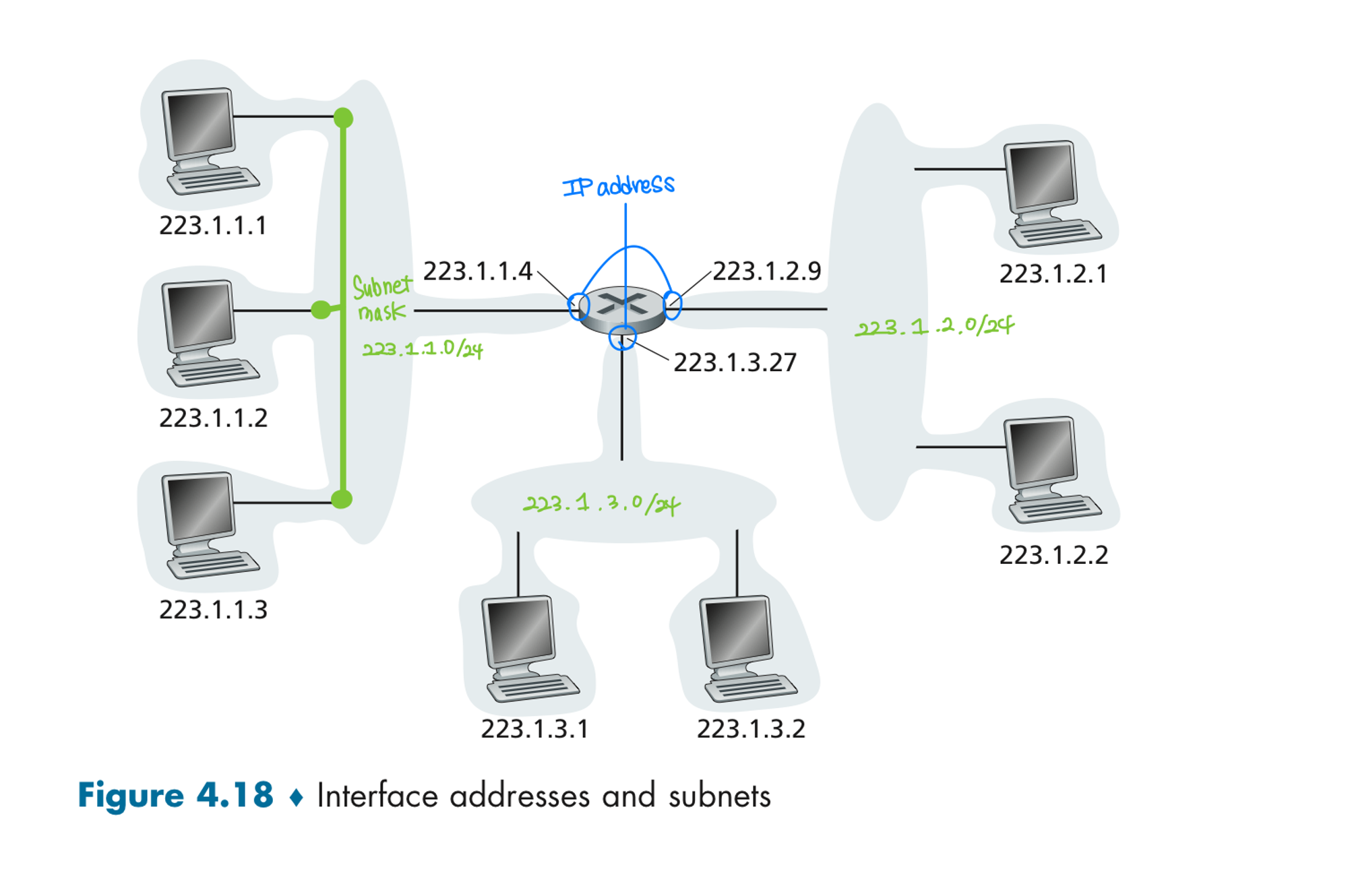
Subnet과 Subnet mask?
Subnet : 같은 networkID를 가진 인터페이스의 집합. 혹은 라우터를 거치지 않고도 연결될 수 있는 인터페이스들의 집합.
CIDR (Classess Interdomain Routing)
Class A
Class B
Class C
NAT (Network address translation)
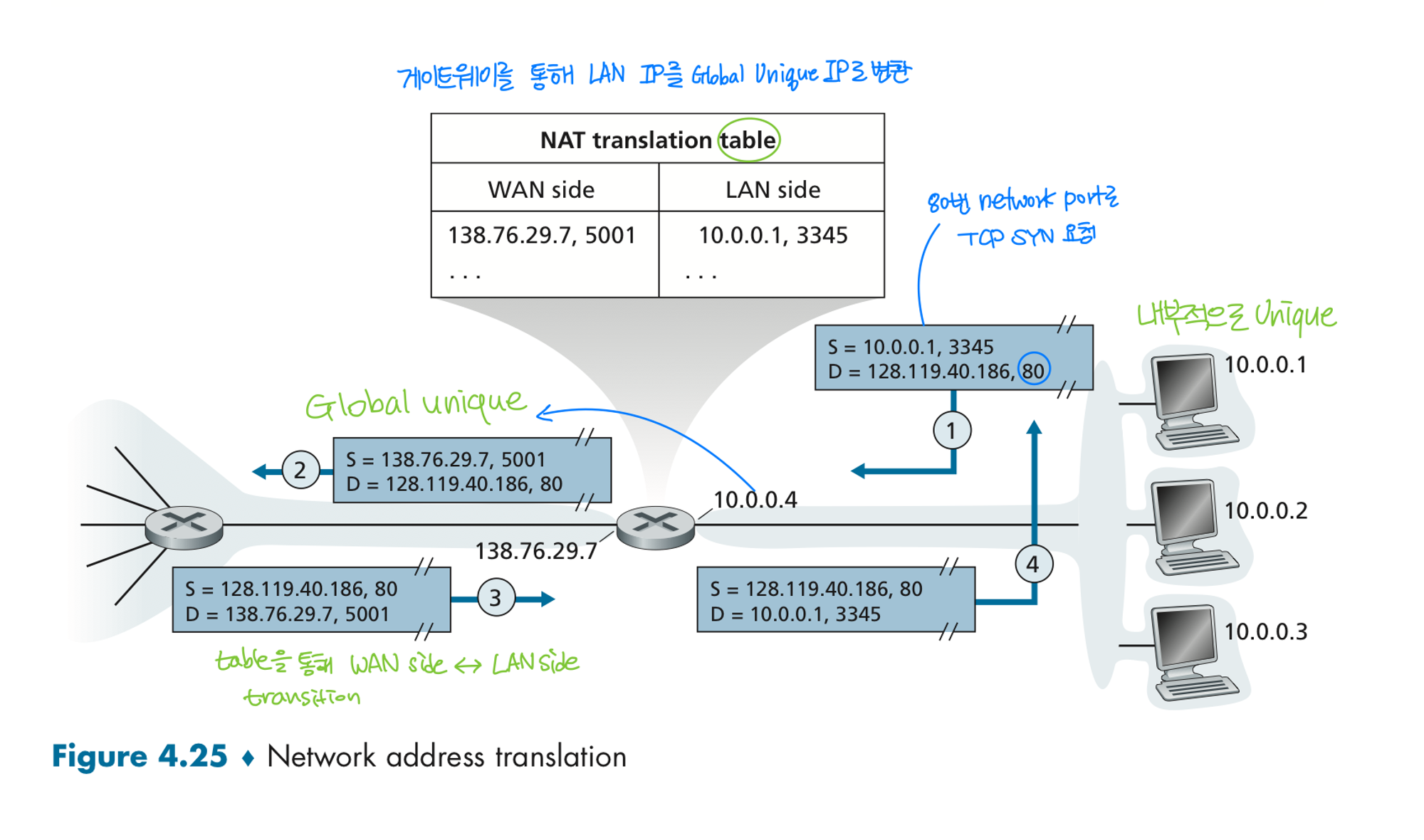
- IP 주소뿐 아니라 포트번호까지 바꾼 이유?
: IP주소는 내부적으로 유일한 번호. 그러나, 포트번호는 겹칠 수 있음. 중첩되지않도록 유일하게 테이블을 작성하게 됨
DHCP (Dynamic Host Configuration Protocol)
IP 주소 배정 프로토콜로,
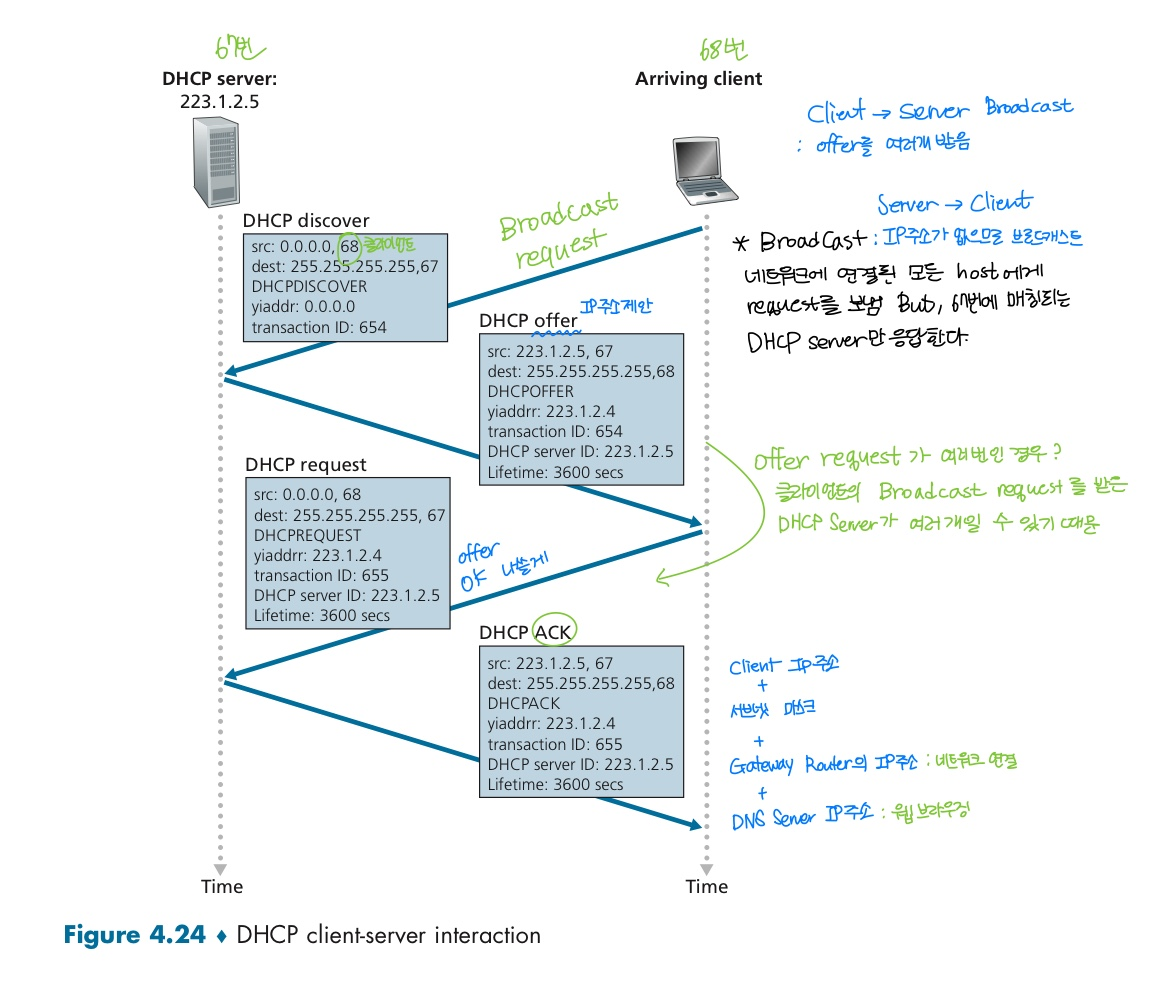
DHCP Discover
DHCP Offer
DHCP Request
DHCP ACK
