
프로그래머스 디스크 컨트롤러 파이썬 풀이
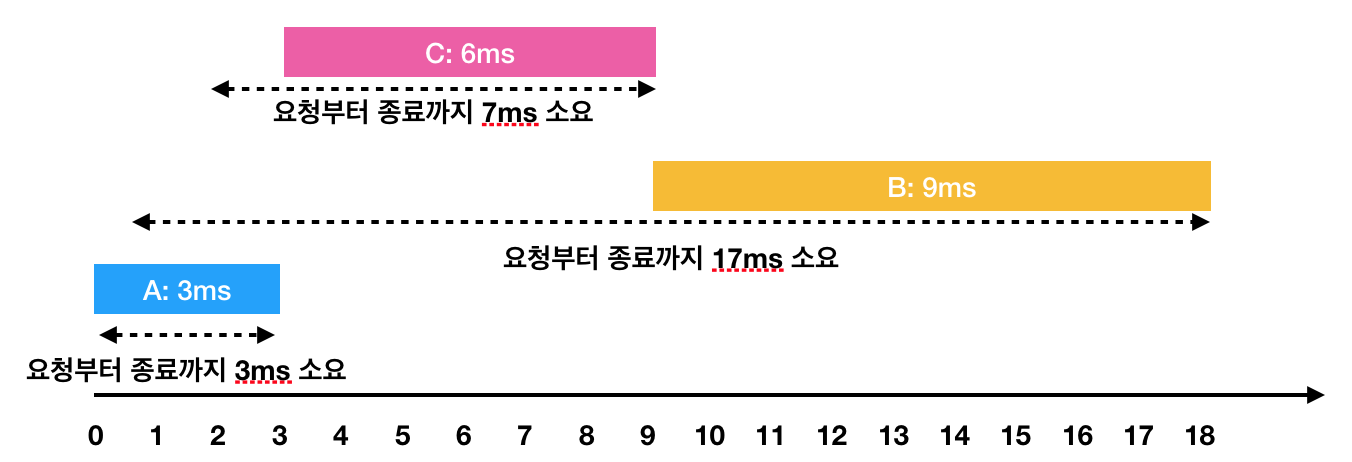 문제 예시에서 볼 수 있듯, 순차적으로 주어진 작업 요청들을 모두 마쳤을 때 그 시간이 최소값을 갖도록 정렬하고 그 평균 수행 시간을 출력하는 문제이다.
문제 예시에서 볼 수 있듯, 순차적으로 주어진 작업 요청들을 모두 마쳤을 때 그 시간이 최소값을 갖도록 정렬하고 그 평균 수행 시간을 출력하는 문제이다.
이는 운영체제 수업에서 배웠던 Shortest Job First 알고리즘을 구현하는 문제이다. 그래서, 처음에는 2차원 배열로 주어진 [요청시간, 수행시간] pair들을 수행시간을 키로 정렬해 문제를 풀고자 했다. 그 코드는 아래와 같다.
1차 코드 수정하기
import heapq as hq
from collections import deque
# 한번에 하나의 요청만을 수행하는 하드 디스크 컨트롤러
# 가장 짧은 요청부터 수행하는 디스크 스케쥴링 알고리즘
def solution(jobs):
jobs.sort(key=lambda x:x[1])
jobs = deque(jobs)
h = [] # 힙에는 처리 후 시간들을 넣을 것임
ans = 0
hq.heappush(h, jobs.popleft())
while jobs:
cur = jobs.popleft()
prev = h[-1]
ans += (cur[0]+cur[1]) - (prev[0]-prev[1])
start = prev[1]
end = start + cur[1]
hq.heappush(h, [start, end])
return ans//len(h) 가장 짧은 인풋으로 입력받은 배열을 2번째 아이템인 수행시간을 기준으로 오름차순 정렬해봤다.i+1번째 요청의 수행 완료 시간은 i번째 요청의 완료 시간 + i+1번째 요청의 소요 시간이다. 여기까지만 구현해보고 코드를 실행시켰다.
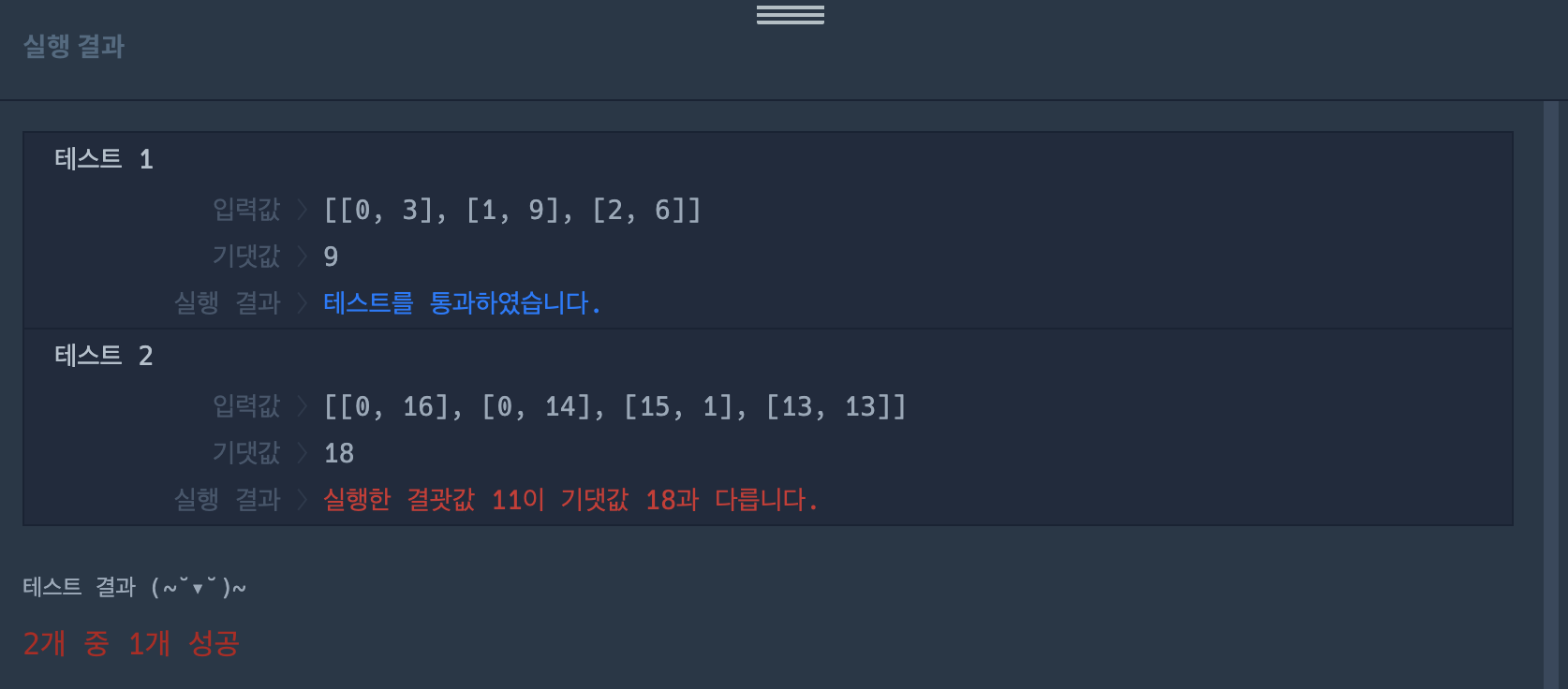
1차 작성 코드의 문제점
그런데 1번 테스트 케이스에선 통과하지만, 2번 테스트 케이스에선 통과하지 못한다. 이유는 1번 같은 경우엔 초과하는 경우가 없지만 2번 예제에선 가장 짧은 수행 시간을 가지는 [15,1]의 요청이 [0,14] 요청 이후에 들어오기 때문에 예외가 발생한다.
그러므로 무조건적으로 가장 짧은 요청 순으로 정렬해 수행하는게 아니라, 요청 시간과 수행시간을 비교해서 스케쥴을 컨트롤해야 한다.
즉, 이 문제에서 요구하는 Shortest Job First 알고리즘은 단순히 수행 시간이 가장 짧은 요청을 수행하는 게 아니라, 완료 시간이 가장 짧은 요청을 먼저 수행하는 알고리즘이다!
로직 갈아 엎기
그래서 앞서 발견한 문제점을 해결하려면 어떻게 해야할까? 문제를 다시 정리하면 현재 수행할 요청은 요청은 완료 시점이 가장 짧은 순으로 수행해야 한다 라는 조건과 현재 수행할 요청의 요청 시간 ≤ 다른 요청들의 완료 시점 조건을 만족해야 한다. 이 조건을 확인하려면 jobs 배열의 모든 요청들을 확인해야 한다. 그러므로 이중 반복문을 써야한다. 다시 코드를 써보자.
2차 작성 과정
# 한번에 하나의 요청만을 수행하는 하드 디스크 컨트롤러
# `현재 수행할 요청의 요청 시간 ≤ 다른 요청들의 완료 시점` 조건을 만족해야 한다.
# 이 조건을 확인하려면 `jobs` 배열의 모든 요청들을 확인해야 한다.
# heap을 사용하면 첫번째 아이템을 기준으로 minheap 정렬을 하므로 배열의 아이템 순서를 바꾸어 정렬한다.
import heapq as hq
def solution(jobs):
h = [] # 현재 수행중인 요청
t = 0
end_t = 0
# 수행 시간의 오름차순으로 정렬하고 요청 시간이 같다면 수행 시간을 내림차순으로 정렬한다.
# 요청시간이 가장 이르고 수행시간이 가장 짧은 프로세스를 수행한다. (heappush)
tasks = sorted([(x[1], x[0]) for x in jobs], key=lambda x: (-x[1], -x[0]))
hq.heappush(h, tasks.pop())
while h:
start, end = hq.heappop(h)
# 요청시간이 수행 완료 시간보다 앞이라면 무엇을 먼저 수행할까?
end_t += start
t += end_t - end
while tasks and tasks[0][0] <= t:
hq.heappush(h, tasks.pop(0))
# 수행중인 요청이 없는 경우
if tasks and not h:
end_t = start + end
hq.heappush(h, tasks.pop(0))
return t // len(jobs)
만약 들어온 요청들 중에서 요청시간과 수행이 끝난 시점이 겹치는 요청이 없다면, 요청의 수행 완료 시간이 (요청시간 + 수행시간)이 된다. 하지만 겹치는 경우가 있을 경우엔 조건에 따라 둘 중에 수행 완료 시간이 최적이 되는 경우를 골라 수행해야 한다.
문제는 2차 작성 코드도 효율성에서 죄다 터진다!
테케는 통과했는데 어디에서 로직이 잘못 된건지 파악이 되지 않아서 차근히 다시 살펴볼 예정..
TIL
- 차근차근 예제를 하나씩 들여다 보며 스텝별로 풀어보자
- 로직을 큰 조건에서 세부 조건으로 쪼개가며 풀어보자
