머신러닝 K-MOOC 복습 TIL
강의 : http://www.kmooc.kr/courses/course-v1:SSUk+SSMOOC20K+2022_T1/about
머신러닝의 3가지 카테고리
-
Supervised Learning : 지도학습
Classification
-> y의 대표적인 아웃풋이 범주(Class)인 경우
Regression
-> Continous한, 연속적인 값인 경우 -
Unsupervised Learning : 비지도학습
Clustering
초반부에는 Supervised Learning에 집중 -
Reinforcement Learning : 강화학습
- Supervised Learning
y = f(x)
x: 입력변수
y: 출력변수
y가 무엇인가에 따라 최종적인 결과물이 달라짐
y가 범주형 변수(강아지, 고양이, 배, 비행기 등등) -> classification
y가 연속형, 숫자 변수 -> regression
관측치의 개수 : n
변수의 개수 : p
x = n*p matrix 이 형태를 띄는 데이터가 많음
-
Classification 예시
x, input data는 이미지일 수도 있고 테이블 형태일 수도 텍스트 형태일 수도 있다 -
Training error
학습 오차
내가 학습시키는 데이터에 대해 발생하는 오차 -
Validation error
예측 오차
일반화 오류
내가 학습시킨 모델이 일반적으로 좋은가
데이터를 모델에 넣어 출력된 y와 실제 y의 차이에서 발생한 오차
모형이 복잡해지면 학습오차는 학습을 많이 시킬수록 쭉 줄어들지만
예측 오차는 줄어들다가 다시 상승
모형이 너무 단순하면 -> 과소적합(Underfitting)
모형이 너무 복잡해서 쓸데없는 패턴까지 학습했다 -> 과대적합(Overfitting)
적합한 포인트를 찾아야 한다
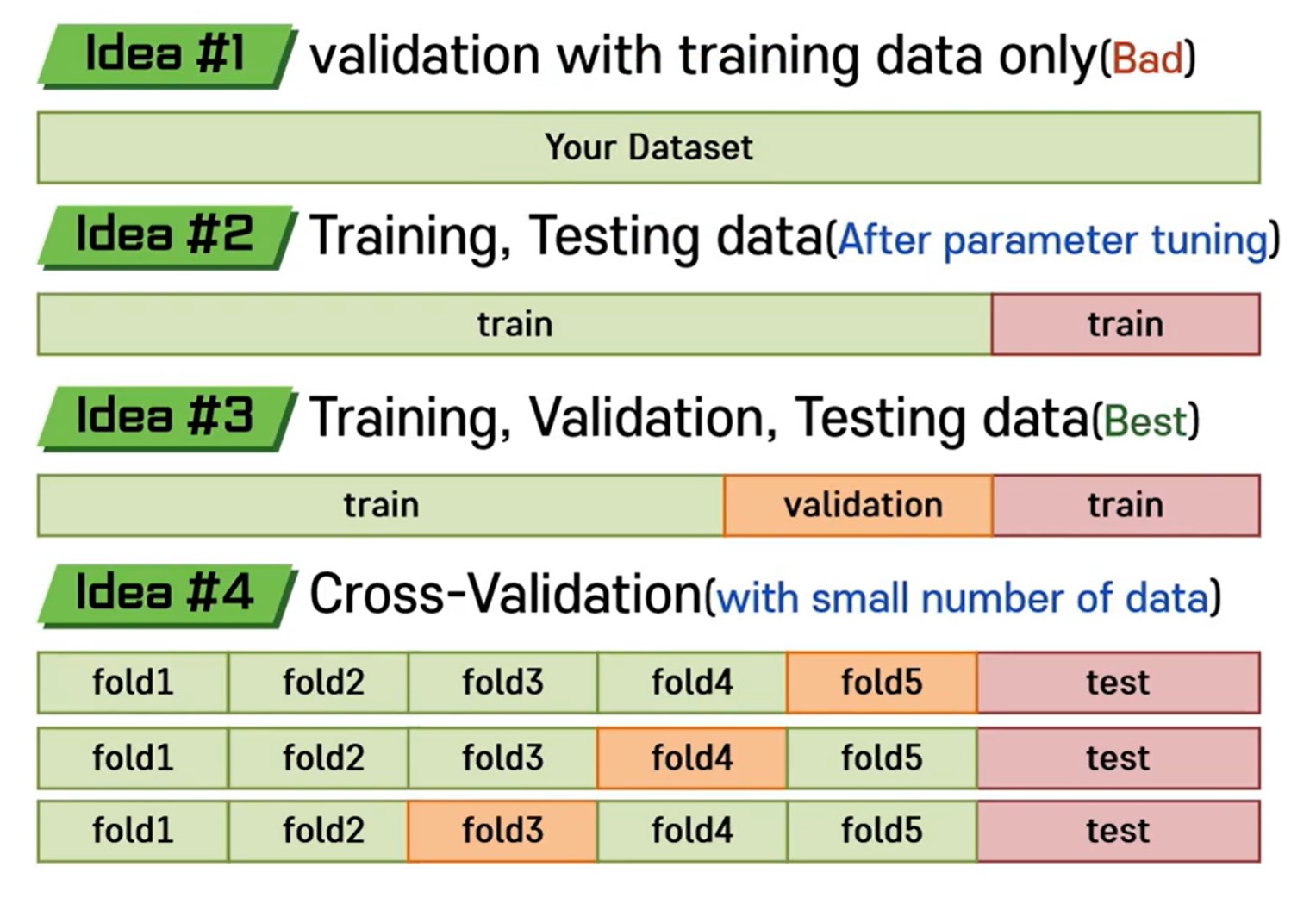
이미지 출처 : 실습으로 배우는 머신러닝 1-3
가장 좋은 건 3번째 방법
마지막은 데이터 수가 적을 때 사용한다
Data 관련용어
- Dataset
정의된 구조로 모아진 데이터 집합 - Data Point(Observation)
데이터 세트에 속해있는 하나의 관측치 - Feature(Variable, Attribute)
데이터를 구성하는 하나의 특성
숫자형, 범주형, 시간, 텍스트, 이진형 - Label(Target, Response)
입력 변수들에 의해 예측, 분류되는 출력 변수
