
[수업목표]
1. 어레이와 링크드리스트에 대해 배우고 차이점을 익힌다.
2. 이진 탐색의 효율성과 전제 조건에 대해 배운다.
3. 재귀함수의 방법과 전제 조건에 대해 배운다.
특정 자료구조는 삽입/삭제가 빠르고,
특정 자료구조는 조회가 빠르다.
이처럼 경우에 따라 빠른 자료구조와 알고리즘을 적절히 잘 사용할 수 있어야 한다.
1. Array와 LinkedList

출처 : https://www.faceprep.in/data-structures/linked-list-vs-array/
Array(배열)
- 배열은 크기가 정해진 데이터의 공간이다. 한 번 정해지면 바꿀 수 없다.
- 하지만 python의 경우 내부적으로 동적 배열을 사용하여 배열의 길이가 늘어나도 O(1)의 시간 복잡도가 걸리도록 설계되어 있다. - 배열은 각 원소에 인덱스를 통하여 즉시 접근할 수 있다.
- 배열은 원소 중간에 삽입/삭제를 하기 위해 모든 원소를 다 옮겨야 한다.
- 따라서 배열의 길이인 N만큼, 즉 O(N)의 시간 복잡도를 가진다.
LinkedList(링크드리스트)
- 리스트는 크기가 정해지지 않은 데이터의 공간이다.
- 리스트는 특정 원소에 접근하기 위해 연결 고리를 따라 탐색해야 한다.
- 따라서 최악의 경우에는 모든 node를 탐색해야 하므로 O(N)의 시간 복잡도를 갖는다. - 리스트는 원소를 중간에 삽입/삭제하기 위해 앞 뒤의 포인터만 변경하면 된다.
- 따라서 원소 삽입/삭제에 O(1)의 시간 복잡도가 걸린다. - python의 배열은 LinkedList로 쓰일 수 있다.
python을 통해 LinkedList 구현
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self, value):
self.head = Node(value)
def append(self, value):
cur = self.head
while cur.next is not None:
cur = cur.next
cur.next = Node(value)
def print_all(self):
cur = self.head
while cur is not None:
print(cur.data)
cur = cur.next
def get_node(self, index):
node = self.head
count = 0
while count < index:
node = node.next
count += 1
return node
# index번 째에 새로운 노드 값을 추가하는 것
def add_node(self, index, value):
new_node = Node(value)
if index > 0:
node = self.get_node(index - 1)
next_node = node.next # 원래 해당 인덱스에 있던 노드를 prior_node에 할당
node.next = new_node # index-1에 해당하는 노드의 다음 노드를 new_node로 할당
new_node.next = next_node # new_node의 다음 노드를 prior_node로 할당
elif index == 0:
new_node.next = self.get_node(index) # self.head
self.head = new_node
return new_node
linked_list = LinkedList(5)
linked_list.append(12)
linked_list.append(8)
print(linked_list.get_node(1).data) # -> 5를 들고 있는 노드를 반환해야 합니다!
linked_list.print_all()
print("----")
print(linked_list.add_node(0, 6).data)
print("----")
linked_list.print_all()Array vs LinkedList
| 경우 | Array | LinkedList |
|---|---|---|
| 특정 원소 조회 | O(1) | O(N) |
| 중간에 삽입 삭제 | O(N) | O(1) |
| 데이터 추가 | 모든 공간이 다 찼을 때, 데이터를 추가한다면 새로운 메모리 공간을 할당 받아야 한다. | 모든 공간이 다 찼어도 맨 뒤의 노드만 동적으로 추가하면 된다. |
| 정리 | 데이터에 접근하는 경우가 빈번하다면 Array 사용 | 삽입, 삭제가 빈번하다면 LinkedList 사용 |
2. 이진 탐색(Binary Search)
숫자 업&다운 게임과 유사하다.
범위의 절반으로 나누어 UP이라면 절반 이후의 범위에서 찾고, DOWN이라면 절반 이전의 범위에서 찾는다.
이러한 방법을 이진 탐색이라고 한다.
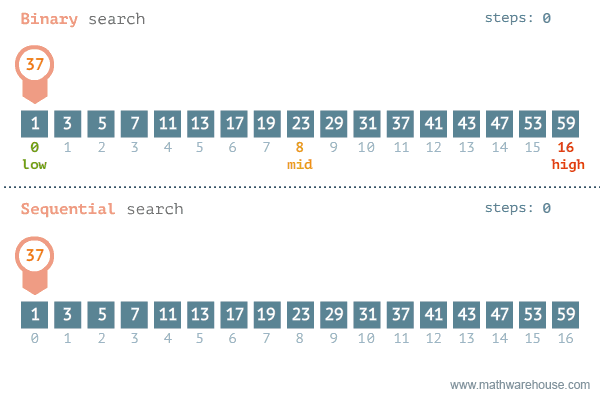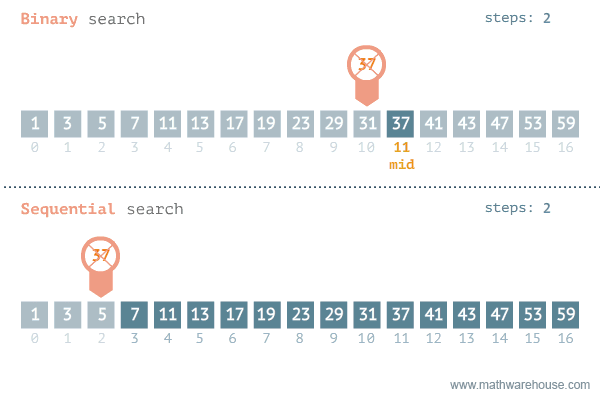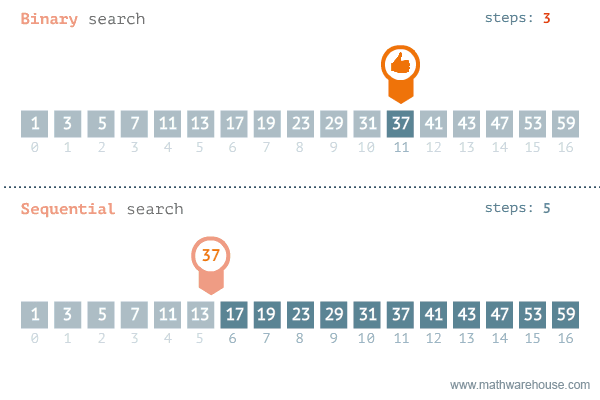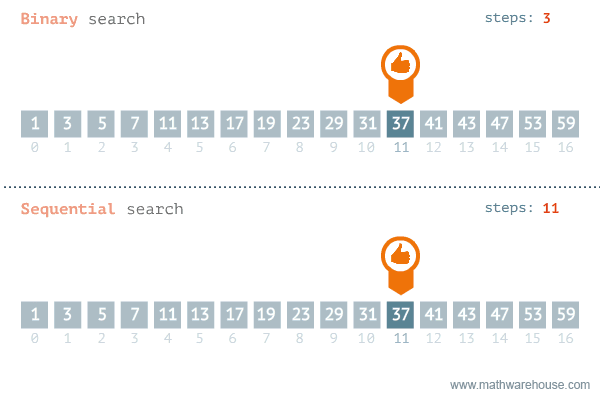
말로 설명하는 것보다 눈으로 보는 것이 더 와닿았다.
이진 탐색 vs 순차 탐색
정렬되어 있는 배열에서만 이진탐색을 사용할 수 있으므로 정렬되어 있다고 가정하면,
이진탐색은 O(logN)의 복잡도를 갖는다.
- 범위를 1/2로 계속 줄여나가기 때문
순차탐색은 O(N)의 복잡도를 갖는다.
- 배열의 길이만큼 탐색해야하기 때문
3. 재귀함수(Recursion)
뜻 : 재귀(Recursion)는 어떠한 것을 정의할 때 자기 자신을 참조하는 것을 뜻한다. [위키백과]
재귀함수를 통하여 간결하고 효율성있는 코드를 작성할 수 있다.
예시 : 팩토리얼(n!) 만들기
def factorial(n):
if n == 1:
return 1
return n * factorial(n - 1)
print(factorial(60))- 탈출 조건을 만들어줌으로써 재귀 함수의 반복을 멈출 수 있다.
- 재귀함수의 목적은 문제의 범위를 점점 좁혀가는 것이다.
- Factorial에서 F(n) = n * F(n-1)로 줄였던 것처럼

나는 날마다 모든 면에서 점점 더 나아지고 있다.