Backend 공부 끄적 (9)
다른 사이트 정보를 한 번 가져오자 => Scraping / Cheerio
axios get으로 원하는 주소를 입력하면 안에 있는 html 태그와 정보들을 가져올 수 있다.
여기서 원하는 정보를 알고리즘으로 따로 빼올수있는데 복잡하기 때문에 Cheerio같은 라이브러리를 사용한다.
discord에서 도메인을 치면 아래와 같이 홈페이지 정보가 나오는데
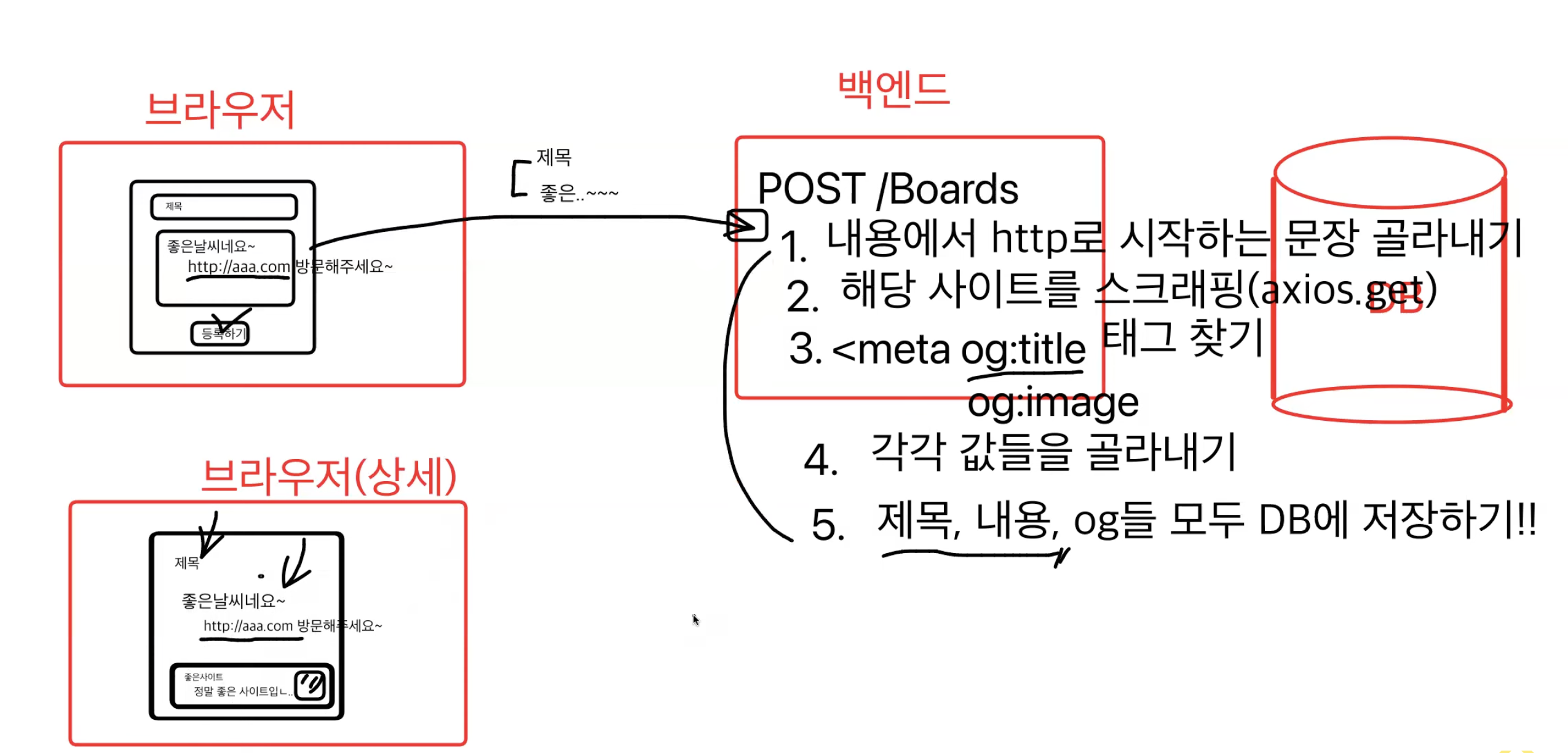
개발자들끼리 암묵적으로 약속된 meta tag에 og:title, og:image 같은 내용들을 스크랩핑해오는 것이다.
<head>
<meta og:title />
<meta og:image />
</head>보통 프론트에서 meta 태그를 활용하여 만들어준다.
백엔드에서는 만약 사용자가 브라우저에서 게시글 내용에 url을 담고 게시글을 작성한다면, 게시글 상세 페이지에 meta tag를 스크랩핑해서 게시글 상세페이지에 출력될 수 있게 해주는 것이다.
다른 사이트 정보를 꾸준히 가져오자 => Crawling / Puppeteer
영리적 목적이거나 무차별적인 크롤링은해서는 안된다.
https://naver.com/robots.txt 라고 도메인 뒤에 robots.txt를 입력하면
크롤링에대한 가이드가 나오는데 허용되지 않았다고 하더라도 절대적인것은 아니다.

프론트엔드 개발자