
1. 개념
프로그래밍에서 트랜잭션(transaction)은 DBMS에서 일련의 데이터베이스 작업들을 하나의 단위로 묶어서 처리하는 것
트랜잭션의 주요 목적은 데이터베이스의 무결성(Consistency)과 정합성(Integrity)을 보장하는 것입니다.
- 무결성(Consistency)
데이터베이스의 저장된 데이터가 정확하고 신뢰할 수 있는 상태임을 보장하는 특성 - 정합성(Integrity)
데이터베이스의 상태가 트랜잭션 실행 전후에 항상 일관된 상태로 유지됨을 의미
2. 필요성
이러한 트랜잭션은 왜 필요할까요?
친구에게 송금을 하는 경우를 생각해봅시다.
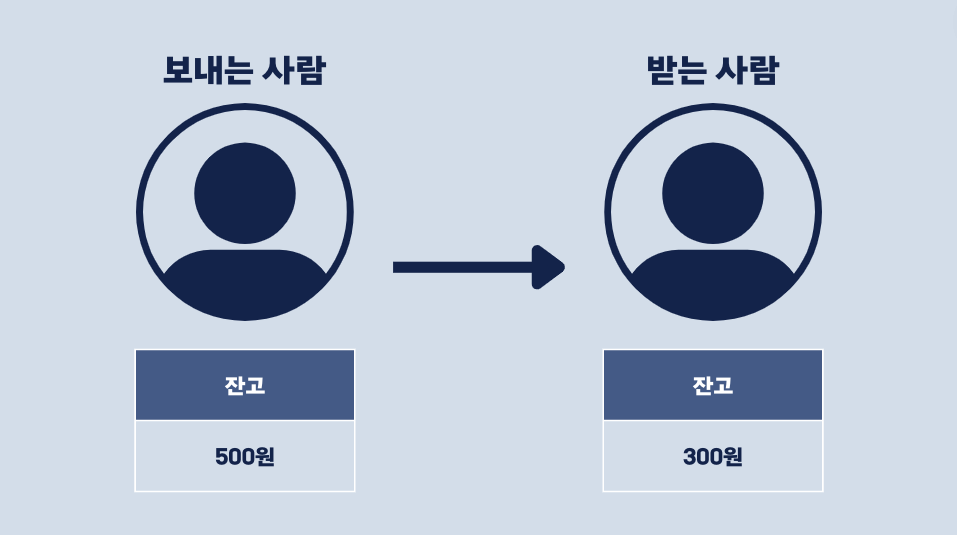
송금하려면 데이터베이스에 다음과 같은 작업을 명령해야 합니다.
- 보내는 사람의 돈 차감
- 받는 사람의 돈 추가
그런데 만약 데이터베이스 연결 불량과 같은 불의의 사고로 1번 수행 후, 2번이 수행되지 않으면 어떻게 될까요?
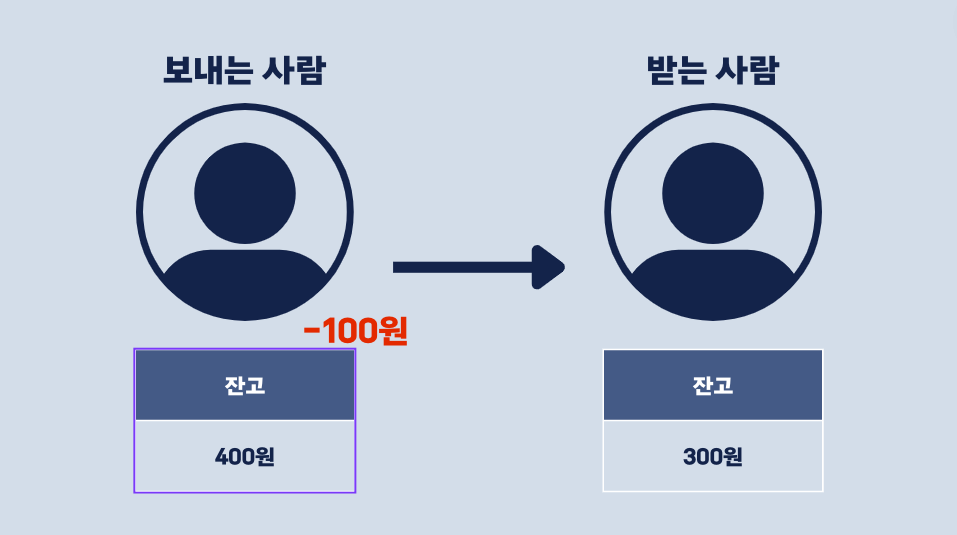
애꿎은 100원만 사라져버렸습니다!
이런 사고를 예방하기 위해 트랜잭션으로 두 작업을 묶어줘야 합니다!
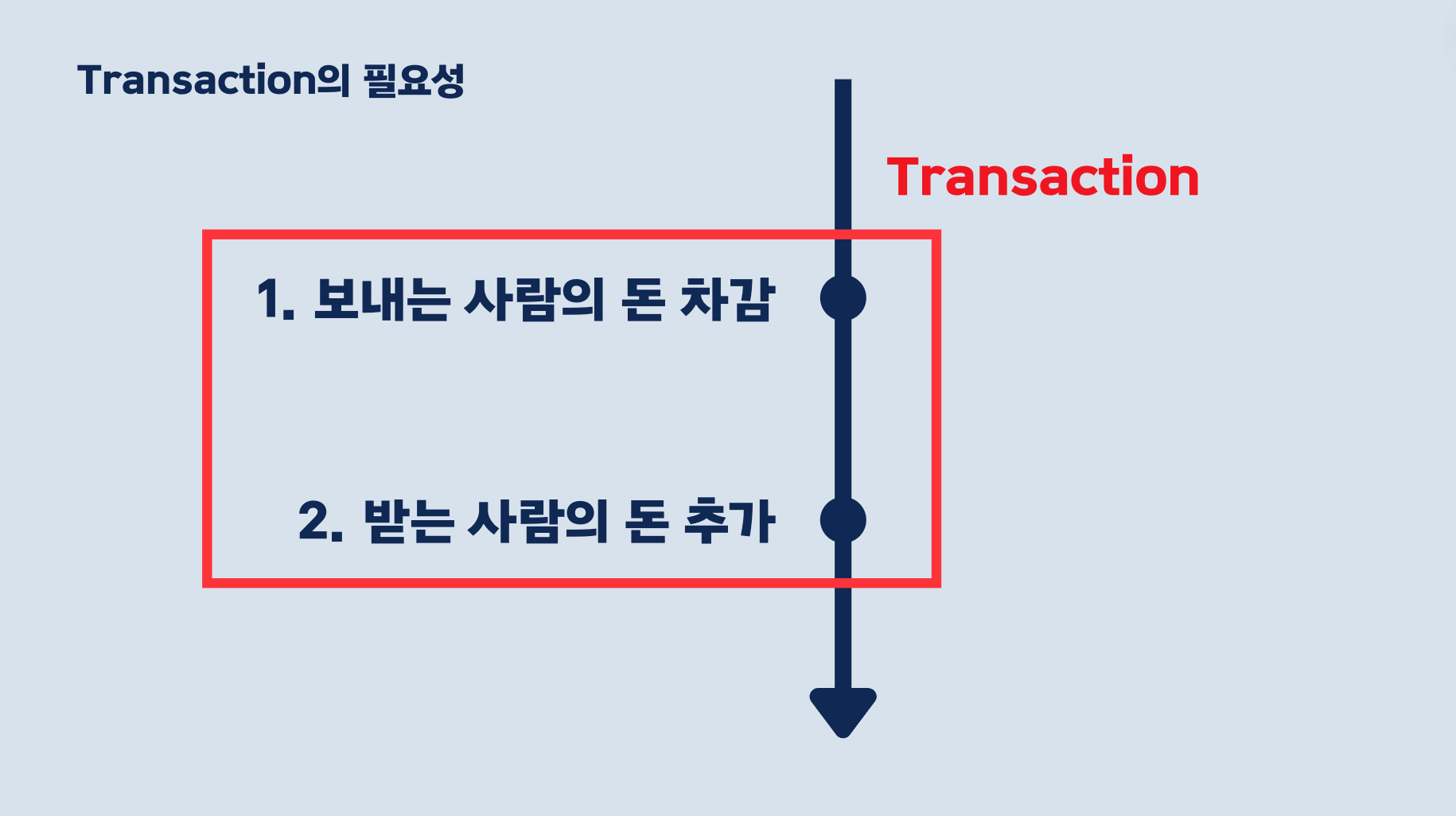
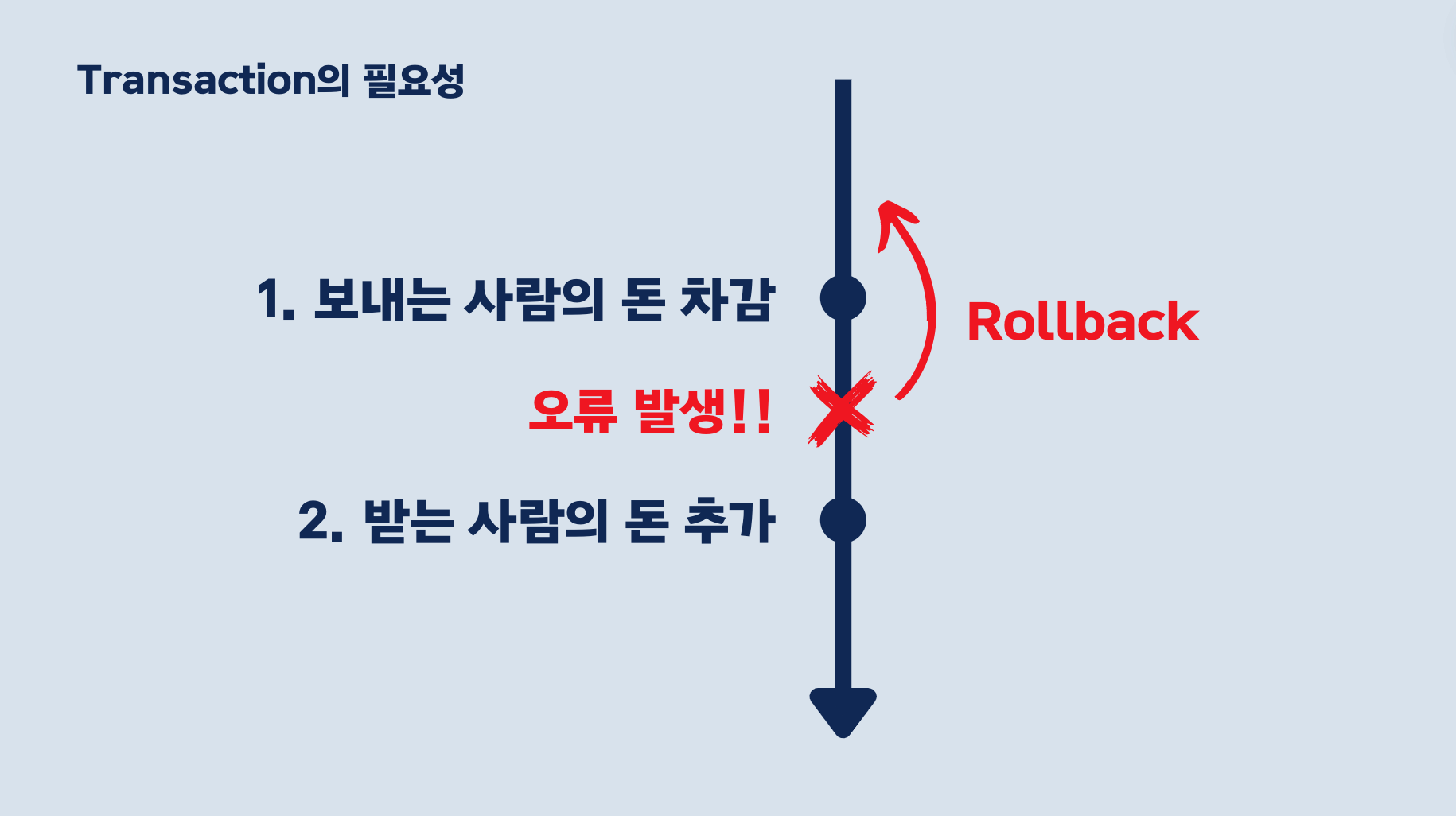
이렇게 하면 오류가 발생했을 때, 트랜잭션을 시작하기 전으로 돌아갈 수 있습니다!
3. 연산
3.1 커밋(Commit)
커밋 연산은 트랜잭션이 성공적으로 완료되었음을 나타내며, 트랜잭션 동안 수행된 모든 변경 사항을 영구적으로 데이터베이스에 적용합니다.
Commit이 실행되면 트랜잭션이 종료되고, 다른 트랜잭션에서 이 변경 사항을 볼 수 있게 됩니다.
Commit 연산은 데이터베이스의 일관성을 보장하는 중요한 작업입니다.
3.2 롤백(Rollback)
롤백 연산은 트랜잭션 중에 오류가 발생했음을 나타내며, 트랜잭션 동안 수행된 모든 변경 사항을 취소합니다.
Rollback이 실행되면 트랜잭션이 시작되기 전에 데이터베이스 상태로 되돌아갑니다.
Rollback 연산은 데이터 무결성을 보호하는 중요한 작업입니다.
4. 특징
이번에는 트랜잭션의 4가지 특징(ACID)에 대해 살펴보겠습니다.
4.1 원자성(Atomicity)
트랜잭션 내의 모든 작업은 하나의 단위로 취급하며, 모두 성공하거나 모두 실패해야 합니다.
중간에 일부 작업만 성공하고 일부 작업은 실패하는 경우가 없어야 합니다. 트랜잭션이 완료되지 않으면, 데이터베이스는 트랜잭션이 시작되기 전 상태로 돌아갑니다.
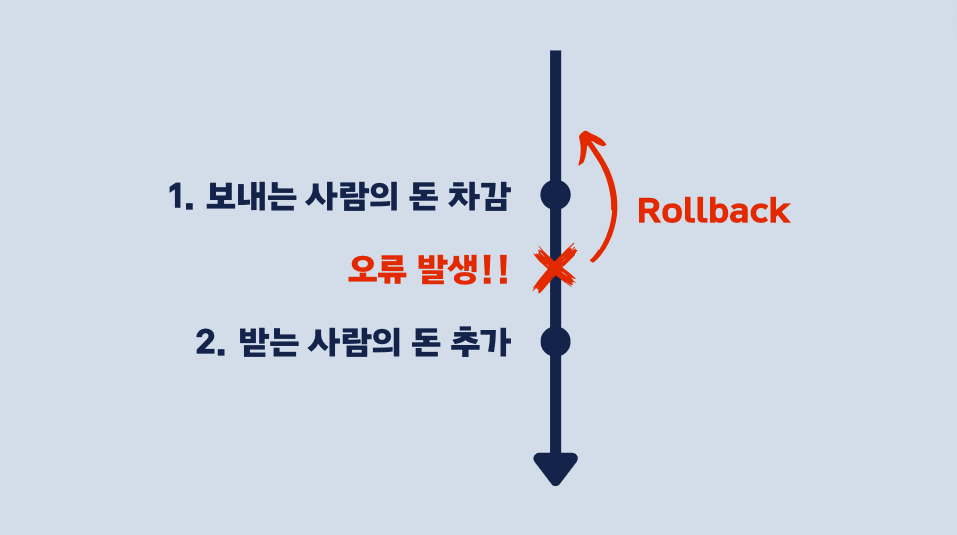
위 예제와 같이 돈을 송금하는 상황에서 중간에 문제가 생겼다면 돈을 보내기 이전의 상태로 돌아갑니다.
4.2 일관성(Consistency)
트랜잭션이 성공적으로 완료되면 데이터베이스는 일관성 있는 상태를 유지해야 합니다.
데이터베이스의 무결성 제약 조건(ex. 기본 키, 외래 키, 도메인 제약 조건 등)이 트랜잭션 전후에 유지되어야 합니다.
4.3 격리성(Isolation)
동시에 실행되는 여러 트랜잭션이 서로 간섭하지 않도록 해야 합니다.
각 트랜잭션은 다른 트랜잭션이 완료될 때까지 데이터베이스에 영향을 미치지 않는 것처럼 보여야 합니다. 이를 통해 트랜잭션 간의 충돌을 방지할 수 있습니다.
4.3.1 읽기 이상 현상(Read Phenomena)
더티 리드(Dirty Read)
하나의 트랜잭션이 아직 커밋되지 않은 다른 데이터를 읽는 경우입니다.
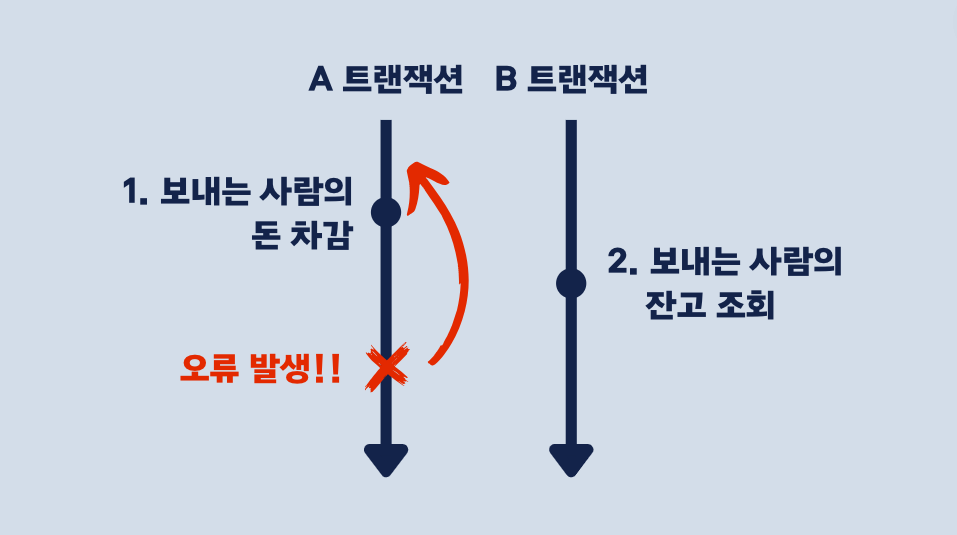
기존 송금 예제처럼 한 트랜잭션(A 트랜잭션)에서 돈을 차감하는 작업을 하고, 또 다른 트랜잭션(B 트랜잭션)에서는 돈을 보내는 사람의 잔고를 조회하는 상황을 생각해봅시다.
위 그림과 같이 A 트랜잭션에서 오류가 발생해서 보내는 사람의 잔고를 롤백(Rollback) 시켰지만, B 트랜잭션에서는 돈이 차감된 값으로 잔고를 조회했습니다.
이러한 문제 상황이 Dirty Read입니다.
논리피터블 리드(Non-repeatable Read)
하나의 트랜잭션이 같은 쿼리를 두 번 수행할 때, 그 사이에 다른 트랜잭션이 해당 데이터를 수정하면 결과가 다르게 나오는 경우입니다.

한 트랜잭션(A 트랜잭션)에서 돈을 차감하는 작업을 하고, 다른 트랜잭션(B 트랜잭션)에서는 잔고를 두 번 조회해봅시다.
위 그림처럼 B 트랜잭션에서 잔고를 조회하는 사이에 A 트랜잭션에서 차감 작업을 해서 두 번의 조회 결과가 서로 다르게 나옵니다.
이러한 문제 상황이 Non-repeatable Read입니다.
팬텀 리드(Phantom Read)
하나의 트랜잭션이 범위 쿼리를 수행하는 동안, 다른 트랜잭션이 해당 데이터를 수정하면 결과가 다르게 나오는 경우입니다.
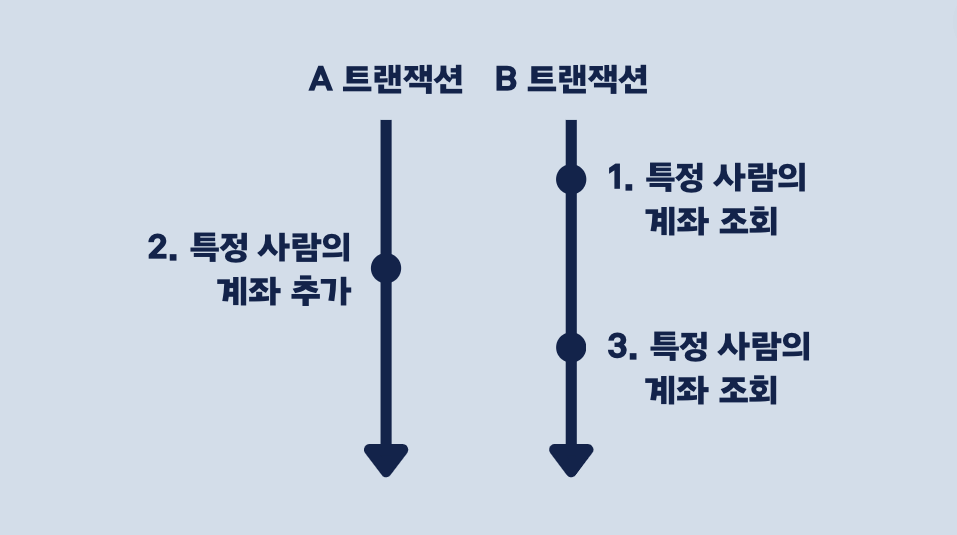
이번에는 앞선 예제들과 조금 다르게 계좌를 추가하고 조회하는 상황을 생각해봅시다.
한 트랜잭션(A 트랜잭션)에서 새로운 계좌를 추가하는 작업을 하고, 또 다른 트랜잭션(B 트랜잭션)에서는 해당 사람의 계좌를 두 번 조회합니다.
위 그림처럼 B 트랜잭션에서 계좌를 조회하는 사이에 A 트랜잭션에서 계좌 추가 작업을 해서 첫 번째 조회에서 없던 계좌가 두 번째에서는 조회됩니다.
이러한 문제 상황이 Phantom Read입니다.
로스트 업데이트(Lost Update)
두 개 이상의 트랜잭션이 동시에 같은 데이터를 읽고 수정하려고 할 때 발생합니다.
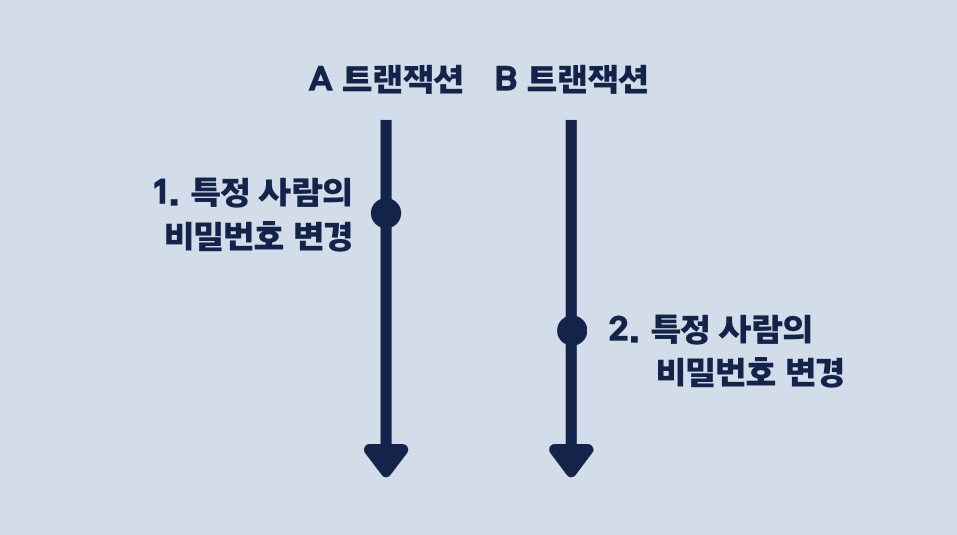
이번에는 누군가가 계좌 비밀번호를 변경한다고 생각해봅시다.
반복적인 요청으로 두 개의 트랜잭션(A, B 트랜잭션)에서 비밀번호를 변경합니다.
B 트랜잭션으로 인해 A 트랜잭션의 결과인 비밀번호 값이 덮어쓰여졌습니다.
비밀번호 변경의 경우, 순서만 보장해줄 수 있다면 큰 문제는 없겠지만 덮어쓰여지지 않아야 하는 중요한 정보라면 심각한 문제가 될 수 있습니다.
이러한 문제 상황이 Lost Update입니다.
Lost Update는 격리성뿐만 아니라 일관성에도 영향을 주는 문제입니다.
4.3.2 격리 수준(Isolation Level)
위 문제들을 해결하기 위해 두 트랜잭션을 격리해야 합니다.
어느 정도 수준으로 격리할 것인지 격리 수준(Isolation Level)을 정해야 합니다.
높은 수준으로 격리한다면 성능이 떨어질 것이고, 낮은 수준으로 격리한다면 몇 가지 문제점이 남아 있을 것입니다.
격리 수준은 총 4가지 종류가 있습니다.
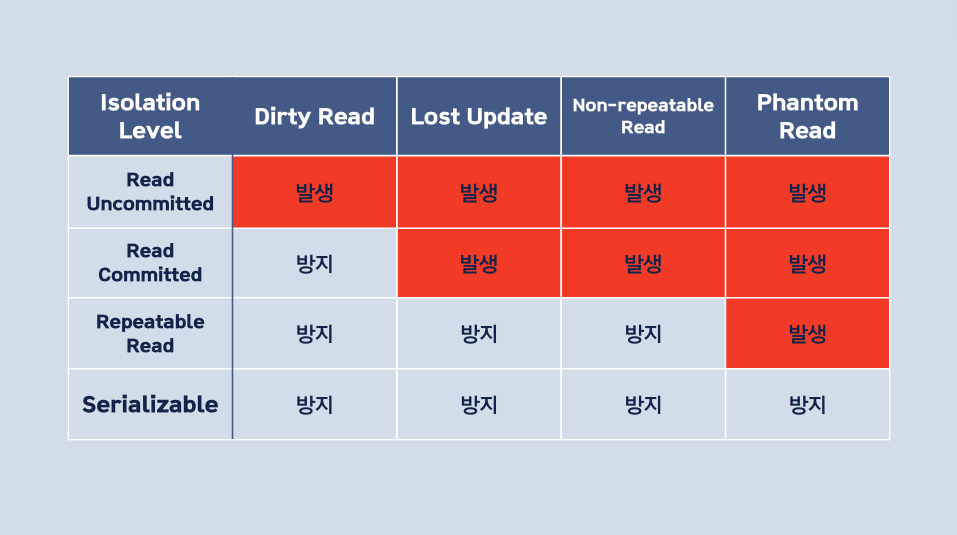
Read Uncommitted
- 가장 낮은 격리 수준
- 트랜잭션이 커밋되지 않은 데이터 읽을 수 있음
- 모든 문제 발생 가능(Dirty Read, Lost Update, Non-repeatable Read, Phantom Read)
Read Committed
- 트랜잭션이 커밋된 데이터만 읽을 수 있음
- Dirty Read 방지
- Lost Update, Non-repeatable Read, Phantom Read 발생 가능
Repeatable Read
- 트랜잭션이 시작된 이후 다른 트랜잭션의 데이터 수정 불가
- Dirty Read, Lost Update, Non-repeatable Read 방지
- Phantom Read 발생 가능
Serializable
- 가장 높은 격리 수준
- 트랜잭션이 순차적으로 수행되는 것처럼 보여짐
- 모든 문제 방지(Dirty Read, Lost Update, Non-repeatable Read, Phantom Read)
4.4 지속성(Durability)
트랜잭션이 성공적으로 완료되면, 그 결과는 영구적으로 데이터베이스에 저장되어야 합니다.
시스템 장애나 오류가 발생하더라도 트랜잭션 결과는 보존되어야 합니다.
결과를 영구적으로 저장한다는 것은 로그를 의미합니다.
로그를 남기는 것까지가 트랜잭션의 역할이기 때문에 로그를 작성하다 오류가 발생하면 롤백해야 합니다.
