나는 이 FineTuning을 해봤어요
1.나는 이 FineTuning을 해봤어요

DeepSeek 때문에 전 세계가 뜨겁다. 빈 수레인지 아닌지 아직은 잘 모르겠지만, 확실한 건 가능성이다. 운이 좋게 '최적화'에 미친 스터디장을 만나 요즘 즐겁게? 공부 중이다. week2: model training anatomy 2주차 스터디 내용을 요약
2025년 2월 5일
2.Gradient Accumulation & Checkpointing
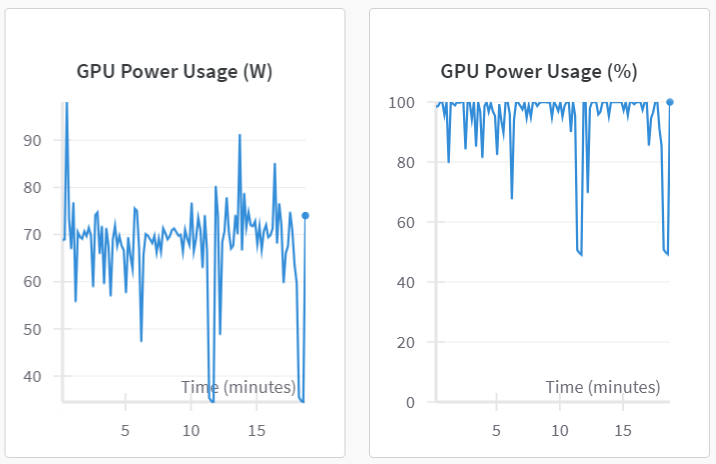
week4: Gradient Accumulation & Checkpointing 1️⃣ Gradient Accumulation ✔ 개념 Gradient Accumulation은 큰 배치 크기를 사용하고 싶지만, GPU 메모리가 부족할 때 사용하는 기법이다. 원래
2025년 2월 12일
3.Mixed precision training

week5: Mixed precision training파라미터(Weights)와 옵티마이저는 FP32 유지, 활성값(Activation)만 FP16/BF16로 변환하여 속도를 향상시키는 기법FP32 < TF32 < FP16/BF16 (속도 증가)32비트를
2025년 2월 19일
4.Optimizer choice
week6: Optimizer choice 옵티마이저(Optimizer)란? 👉 쉽게 말하면, 머신러닝 모델이 더 좋은 정답을 찾도록 도와주는 알고리즘! 모델이 학습할 때는 손실 함수(loss function, 예: MSE, Cross-Entropy 등)를 줄이
2025년 2월 26일