멀티 태스크 & 메타러닝 기초
다루는 주제
멀티 태스크 러닝
- 멀티태스크 러닝에서 다루는 모델과 아키텍처
- 학습 알고리즘들과 실제 어떻게 학습하는 지
- 그 과정에서 발생하는 문제
- 실제 사례 연구
메타 러닝
- 문제 공식화: 첫 강의에서는 대략적으로(informal) 메타러닝 태스크에 대해 설명하였고, 그 부분을 공식화 한다.
- 일반적으로 메타러닝을 다루는 방법
Black Box Adaptation이라는 메타러닝 알고리즘에 대해 배움.
1. Multi-Task Learning
1.1 Notation
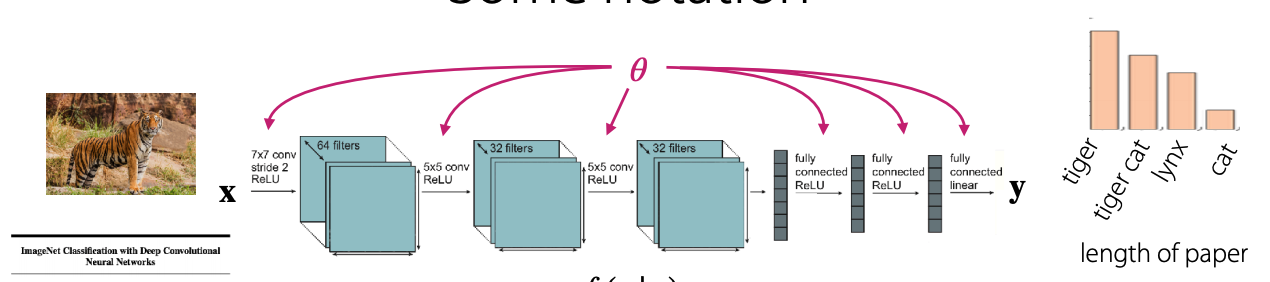
- 신경망은 입력 x 를 받아 y를 출력
- 입력이 주어지면 출력 y에 대한 분포가 생성된다.
- 입력에 따라 y가 항상 분포(distribution)이 되는게 아닌 결정론적(deterministic)이 될 수도 있다.
Single-task Learning에서의 예
- 어떠한 데이터 가 주어져 있고.
- 손실함수(Loss Function)
- 신경망의 웨이트
위와 같을 때,손실함수 를 최소화 하는 웨이트 를 찾는 것.
- 일반적으로 손실함수는 negative log likelihood를 사용하며, 역전파을 이용해서 학습한다.
Multi-task learning에서의 Task란?
과 같이 Task 를 정의 한다.
- 입력 x 에 대한 분포
- 입력값과 손실 함수가 distributions으로 나타나며
- 데이터는 distribution들을 생성한다.
Dataset은 , 으로 구성되며, 일반적으로 강의에서 는 을 의미한다.
1.2 Multi-task Learning에서 Task의 예
위와 같이 정의한 Task에 대해서 아래의 예를 통해 설명하고자 한다.
Task
과 같이 Task 를 정의 한다.
- 입력 x 에 대한 분포
- 입력값과 손실 함수가 distributions으로 나타나며
- 데이터는 distribution들을 생성한다.
Dataset은 , 으로 구성되며, 일반적으로 강의에서 는 을 의미한다.
1) Multi-task Classification
다중 분류 작업의 경우 모든 태스크들에 대해서 손실함수 는 동일하며, 손실함수의 경우 크로스엔트로피를 사용한다.
사용예로는
- 언어별, 손글씨 인식
- 개인화된 스팸필터: 사람마다 스팸의 기준이 다르므로 스팸의 유형이 달라지게 된다. 그래서 사람 간 스팸 분류는 다르게 될 수 있가. 이때 는 이메일의 타입이 다르기 때문에 서로다른 를 갖게 되고, 그에 따라 분류가 달라지게 된다.
2) Multi-label learning
와 는 모든 태스크들에 대해서 동일하다. 다른점은 라벨에 대해 예측을 하길 원하는 것으로 예로는 아래와 같은 것들이 있다.
- 속성인식: 사람이 모자를 쓰고 있는지, 머리색 깔이 다른지
- Scene Undeerstanding: 카메라가 보는 장면의 깊이 등의 장면을 이해하는데 사용.
태스크 마다 가 다른경우
- 태스크에 따라 discrete, continuous label들이 혼합된경우
- 다른 태스크보다 한 태스크에 좀더 집중해야하는 경우.

이러한 설정은 손실함수는 같으며, 데이터의 distribution만 달랐다.
Notation
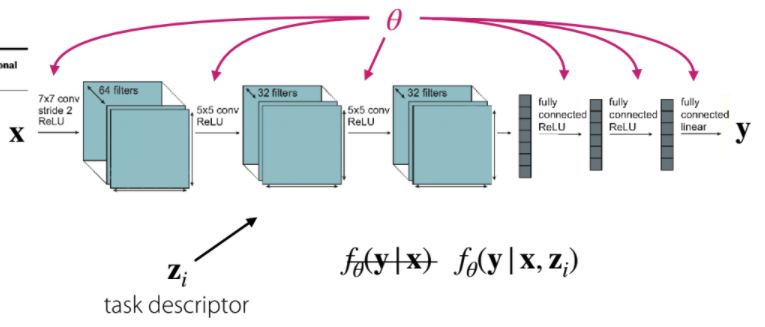
Objective:
- 입력
- 출력
- 태스크에 대한 설명(task descriptor)
- 가 아닌 태스크에 대한 설명이 추가된
task descriptor
태스크에 대한 설명 는 태스크의 인덱스를 나타내는 원핫인코딩을 사용하거나 가지고 있는 어떠한 메타데이터들을 말한다. 여기서 말하는 메타데이터는, 유저의 특징이나 특성을 나타내는 정보, 태스크에 대한 언어 설명, 태스크에 대한 formal specifications들을 말한다.
A model decision and an algorithm decision
- 어떻게 의 조건을 결정할것인가?
- Objective의 최적화는 어떻게 할 수 잇는가?
Conditioning on the task
를 태스크 인덱스로 가정하는 경우, 어떻게 가능한한 파라미터를 작게 공유할 수 있는가?
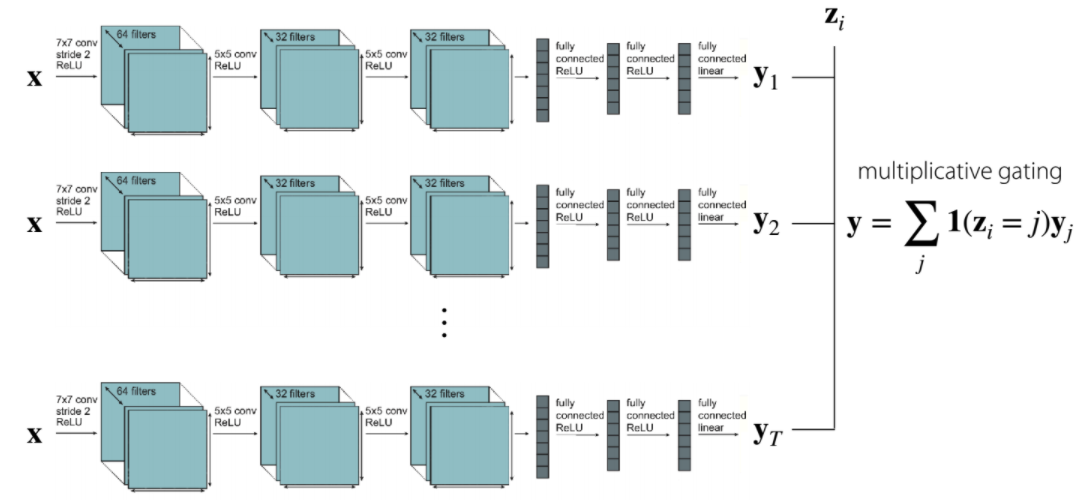
multiplicative gating
싱글 레이어를 이용해서 독립적으로 학습하며, 파라미터들을 공유하지 않는다.
The other extreme
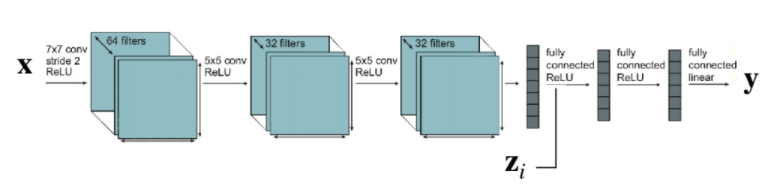
Concatenate with input and/or activations
을 입력이나 activation들에 concat 시켜준다. 이러한 경우 를 직접적으로 따르는 파라미터를 제외한 모든 파라미터들이 공유 된다.
An Alternative View on the Multi-Task Objective
를 공유되는 파라미터 와 task-specific 파라미터 로 볼때, Objective를 다음과 같이 정할 수 있다.
이때 의 조건을 결정하는 것과 어떻게 & 어떤 공유파라미터를 선택하는 것은 동등한 문제이다.
Conditioning: Some Common Choices
조건을 선택하는 방법
일반적인 방법
1. Concatenation-based conditioning
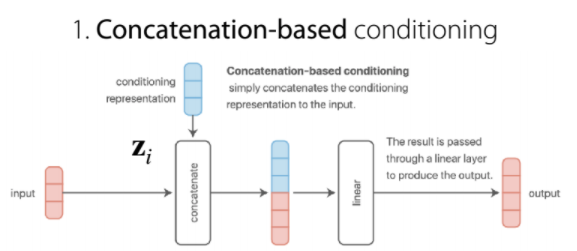 $
$
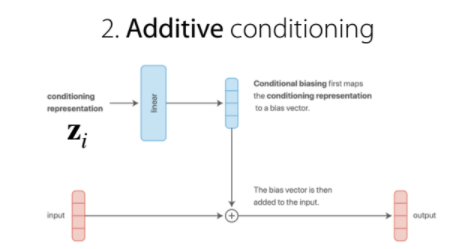
2. Additive conditioning
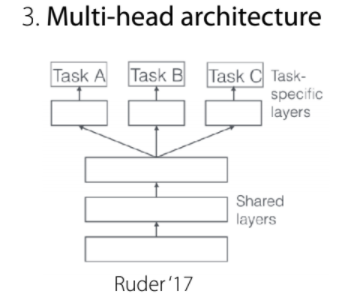
3. Multi-head architecture
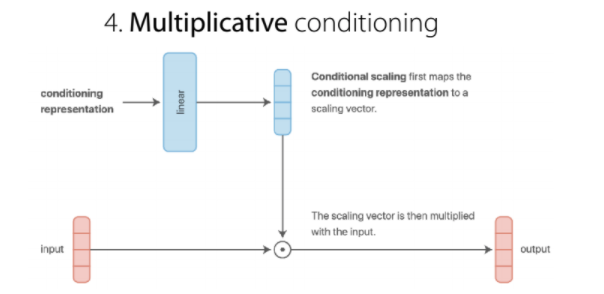
4. Multiplicative conditioning
multiplicative conditioning이 좋은 이유는 보다 표현력이 좋고, recall:multiplicateve gating 때문이라 한다. 그리고 독립적인 네트워크와 헤드들을 일반화 한다.
Condition을 선택하는 다른 복잡한 방법들
위 언급한 4가지를 제외한 condition을 선택하는 다른 여러가지 방법.
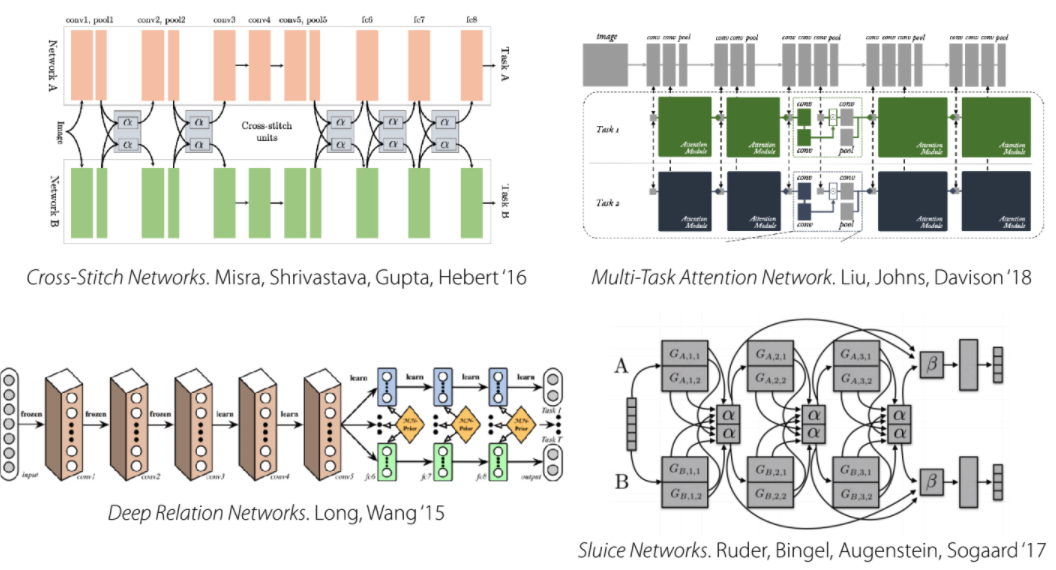
Conditioning Choices
...작성중...
