Anomaly Detection
normal (정상) sample과 Abnormal (비정상, 이상치, 특이치) sample을 구별해내는 것.
1. 비정상 sample의 사용여부 / label 유무에 따른 분류
Supervised Anomaly Detection
학습 데이터 셋에 정상 sample과 비정상 sample의 data와 label이 모두 존재하는 경우 (지도학습)
! 지도학습 : 정확도가 높아야하는 경우에 주로 사용됨, 비정상 sample이 많을 수록 더 높은 성능을 보임
하지만, Anomaly Detection이 적용되는 일반적인 산업 현장에서는 정상 sample보다 비정상 sample의 발생 빈도가 적기 때문에 Class-Imbalance(불균형) 문제 발생
이를 해결하기 위해 Data Augmentation (증강) , loss function(손실함수) 재설계, Batch Sampling 등을 수행함
*loss function: 알고리즘이 예측한 값과 실제 정답의 차이를 비교하기 위한 함수
*Batch sampling: 활성화함수의 활성화값 또는 출력값을 정규화(정규분포로 만든다)하는 작업
https://sacko.tistory.com/category/Data Science/문과생도 이해하는 딥러닝
Semi-supervised Anomaly Detection
위 방식의 가장 큰 문제점은 비정상 sample을 확보하는 데에 어려움이 있다는 것임.
(= Class-Imbalance 가 심하다)
이를 해결하기 위해 정상 sample만 이용해서 모델을 학습하기도 하는데 이 것이 바로
semi-supervised learning or One-class classification 이라고 함.
! 준지도 학습 or OCC: 정상 sample들을 둘러싸는 dicriminative boundary 를 설정하고, 이 boundary를 최대한 좁혀 밖에 있는 sample들을 모두 비정상으로 간주하는 것
One-Class SVM: 위 방법인 One-Class Classification을 사용하는 대표적인 방법론.
이 아이디어에서 확장해 딥러닝을 기반으로 OCC 방법론을 사용하는 deep SVDD 논문이 잘 알려져 있다네요.
- Deep SVDD 방법론 모식도
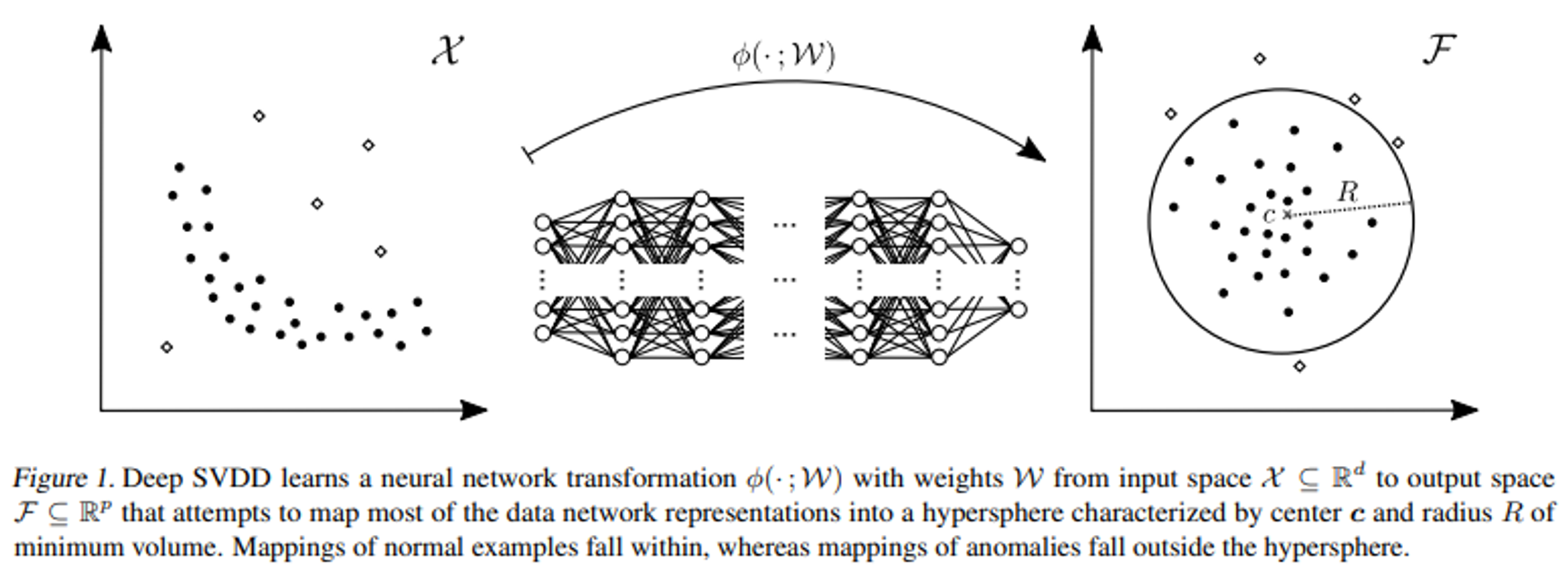
Unsupervised Anomaly Detection
위 방식은 정상 sample이 필요함.
수 많은 데이터 중에 어떤 것이 정상 sample 인 지 알기 위해서는 정상 sample에 대한 label을 확보하는 과정이 필요함.
그래서 Unsupervised anomaly detection 방법은 대부분의 데이터가 정상 sample이라는 가정을 하여 label 취득 없이 학습시키는 방법임.
단순하게는 주어진 데이터에 대해 Principal Component Analysis (PCA, 주성분 분석)를 이용하여 차원을 축소하고 복원하는 과정을 통해 비정상 sample을 검출할 수 있음
Neural Network 기반으로는 Autoencoder 기반의 방법론이 주로 사용되고 있음.
*Autoencoder: 입력을 code 혹은 latent variable (잠재 변수) 로 압축하는 Encoding과 이를 다시 원본과 가깝게 복원해내는 Decoding 과정으로 진행이 되며 이를 통해 데이터의 중요한 정보들만 압축적으로 배울 수 있음. (PCA와 유사한 동작을 함)
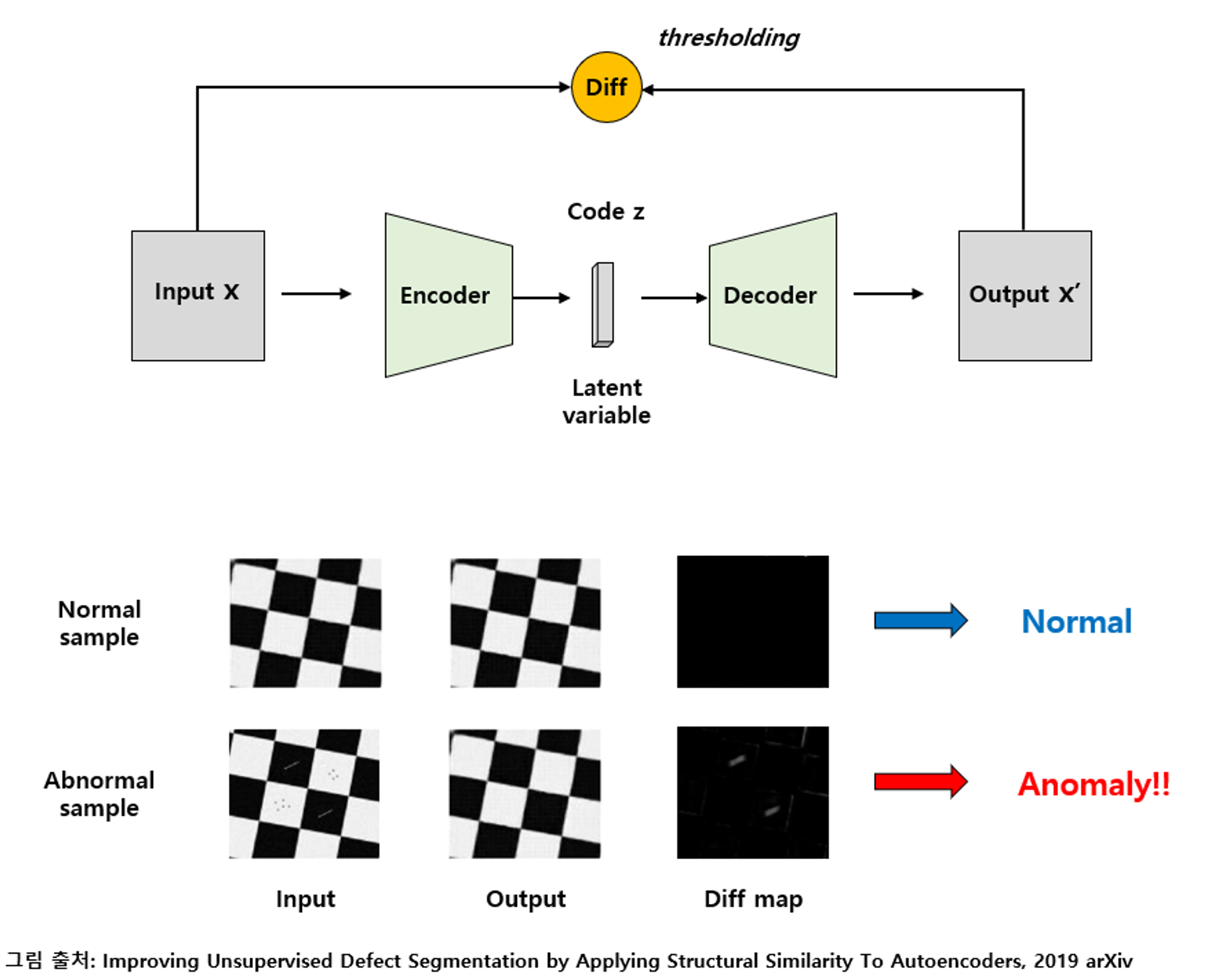
위 그림은 autoencoder를 이용하여 학습하는 과정임
! autoencoder의 code size (= latent variable의 dimension) 같은 hyper-parameter에 따라
