맞춤형 취약품사 보완 추천 서비스(Duolingo SLAM Data)를 위한 모델 개발 | Knowledge Tracing | Ch.1 데이터 수집 및 전처리
DuolingoKnowledgeTracing
http://sharedtask.duolingo.com/2018.html
데이터 수집
수집된 데이터는 http://sharedtask.duolingo.com/2018.html 2018 Duolingo Shared Task on Second Language Acquisition Modeling (SLAM) 를 위해 제공된 데이터셋을 활용하였습니다. 그 중 영어를 대상으로 서비스화 하기 위해, en_es — English learners (who already speak Spanish) 데이터를 사용했으며, 스페인어를 구사하고 있는 사용자들의 영어 연습을 담은 데이터 입니다. 해당 데이터는 Duolingo 앱 서비스에서 누적된 사용자들의 토큰별 정오답여부를 담은 데이터로, 데이터 포맷은 아래와 같습니다.
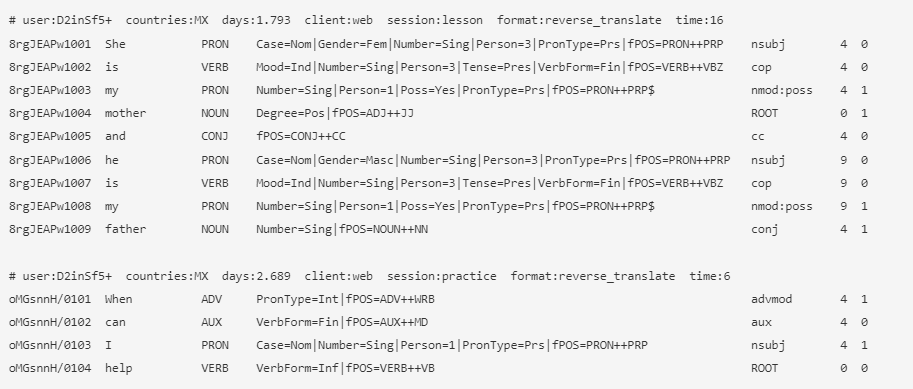
user a B64 encoded, 8-digit, anonymized, unique identifier for each student (may include / or + characters) / 사용자 아이디
countries a pipe (|) delimited list of 2-character country codes from which this user has done exercises / 사용자 국가
days the number of days since the student started learning this language on Duolingo / 사용자가 언어 공부를 하기 시작한 후 지난 일수
client the student's device platform (one of: android, ios, or web) / 사용 플랫폼
session the session type (one of: lesson, practice, or test; explanation below) / 세션 타입
format the exercise format (one of: reverse_translate, reverse_tap, or listen; see figures above) / 연습 포맷(번역, 단어나열, 듣기)
time the amount of time (in seconds) it took for the student to construct and submit their whole answer (note: for some exercises, this can be null due to data logging issues) / 해당 문장을 공부하는 데 걸린 시간
A Unique 12-digit ID for each token instance the first 8 digits are a B64-encoded ID representing the session, the next 2 digits denote the index of this exercise within the session, and the last 2 digits denote the index of the token (word) in this exercise / 토큰(단어)별 id
The token (word) / 단어
Part of speech in Universal Dependencies (UD) format / 품사
Morphological features in UD format
Dependency edge label in UD format
Dependency edge head in UD format (this corresponds to the last 1-2 digits of the ID in the first column)
The label to be predicted (0 or 1) / 정오답
데이터 전처리
이 후 Ch2 에서 사용하게될 DKT 라는 Knowledge Tracing 모델을 소개하며 언급되겠지만, Knowledge Tracing을 위해서는 사용자, 학습하고자 하는 대상(여기서는 토큰 혹은 품사 등), 그리고 그 대상의 정오답 여부, 마지막으로 시간 정보가 필요합니다. 이 데이터들을 통해 사용자별로 순차적인 학습대상의 공부를 통해 정오답 여부가 어떻게 변화하였는지를 LSTM 모델을 통해 학습을 진행하게 됩니다.
txt to Dataframe
저는 사용자별 취약 품사 추천을 목표로 하고있습니다. 따라서, 임의의 사용자가 문장을 연습한 후, 각 품사들의 맞출 확률 혹은 정오답을 예측해야 하며 이를 위해 데이터에서 정의된 품사(Part Of Speech), 그에 0과1로 태깅된 정오답을 시간순서대로(days) 학습하고자, 해당 컬럼만을 추출하여 데이터 프레임으로 정의해주었습니다.
train_data = open("data/train.txt", 'r')
line = train_data.readline()
line_list = []
while line:
if(line.find('# user:') == 0):
user = line[7:line.find(' countries')]
days = line[line.find('days')+5:line.find(' ',line.find('days')+4)]
time = line[line.find('time')+5:line.find('\n')]
elif(line.find('#') == -1 and line != '\n'):
string_list = line.split()
code = string_list[0]
word = string_list[1]
part_of_speech = string_list[2]
correct = string_list[-1]
new_data = {
'user' : user,
'code' : code,
'word' : word,
'pos' : part_of_speech,
'time': time,
'correct' : correct,
'days' : days,
'split' : splitid
}
train_df = train_df.append(new_data, ignore_index=True)
elif(line == '\n'):
splitid+=1
line = train_data.readline()
else:
line = train_data.readline()
train_data.close()
위 코드는 다운받은 데이터(txt)를 데이터프레임으로 바꿔주기 위한 코드입니다.
원본 데이터는 .train 파일이었는데, 이 파일을 다루는 법을 몰라, 데이터를 txt 파일로 변환하여, txt파일을 데이터프레임으로 바꿔주었습니다.
txt파일에서 컬럼들은 모두 탭혹은 띄어쓰기로 구분되어 있고, 그 속에서 원하는 컬럼을 뽑기 위해 find 함수를 사용하느라 시간이 매우 오래 걸렸습니다. 더 효율적인 방법으로 변환할 수 있는 방법이 분명 있을 듯 합니다.
아무튼 앞서 말한대로, 사용자, 품사, 정오답, 학습시간(days) 외에, 문장을 구분해주기위해 문장별 인덱스(split), 해당 문장을 연습하는 데 걸린 시간(time) 을 추가로 저장해주었습니다.
이렇게 하면 DKT 적용을 위한 데이터는 모두 준비되었습니다. 해당 데이터를 가지고 DKT(Depp Knowledge Tracing)에 돌려본 결과, 그리고 간단한 Knowledge Tracing에 대한 설명을 다음 게시글로 정리하겠습니다.
