위의 사이트를 참고하면서 작성한 내용입니다.
#프로세스 & 스레드
#프로세스
프로그램을 메모리 상에서 실행 중인 작업
#스레드
프로세스 안에서 실행되는 여러 흐름 단위
기본적으로 프로세스마다 최소 1개의 스레드 소유 (메인 스레드 포함)
하나의 프로세스가 생성될 때, 기본적으로 하나의 스레드(메인 스레드)를 같이 생성한다.
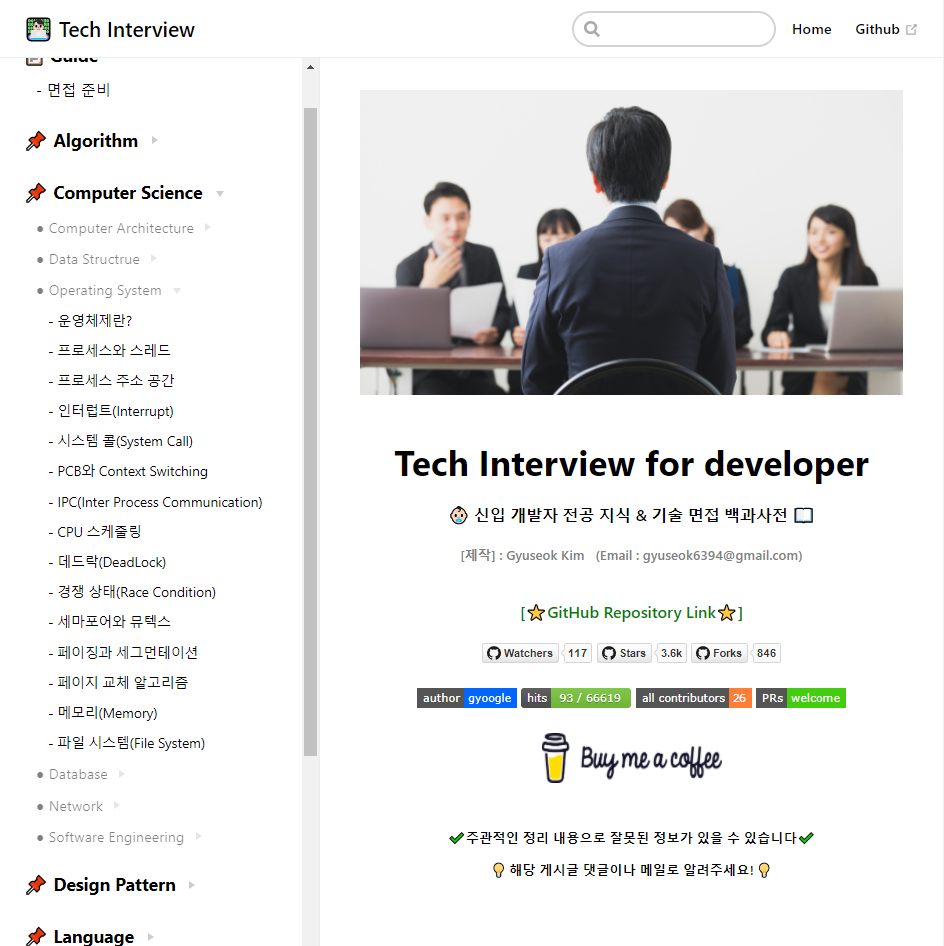
프로세스는 각각 별도의 주소공간 할당 (각 프로세스가 독립적이다)
- Code: 코드 자체를 구성하는 메모리 영역(프로그램 명령)
- Data: 전역변수, 정적변수, 배열 등 (초기화된 데이터)
- Heap: 동적 할당 시 사용 (new(), malloc() 등)
- Stack: 지역변수, 매개변수, 리턴 값 (임시 메모리 영역)
스레드는 Stack만 따로 할당 받고 나머지 영역은 서로 공유
즉, 프로세스는 자신만의 고유 공간과 자원을 할당받아 사용하는데 반해, 스레드는 다른 스레드와 공간, 자원을 공유하면서 사용하는 차이가 존재함
#멀티프로세스
하나의 컴퓨터에 여러 CPU 장착 -> 하나 이상의 프로세스들을 동시에 처리(병렬)
- 장점: 안전성(메모리 침범 문제를 OS 차원에서 해결)
- 단점: 각각 독립된 메모리 영역을 갖고 있어, 작업량이 많을 수록 오버헤드 발생. (컨텍스트 스위칭으로 인한 성능 저하)
#Context Switching(컨텍스트 스위칭)
프로세스의 상태 정보를 저장하고 복원하는 일련의 과정
멀티프로세스 환경에서 CPU가 어떤 하나의 프로세스를 실행하고 있는 상태에서 인터럽트 요청에 의해 다음 우선 순위의 프로세스가 실행되어야 할 때 기존의 프로세스의 상태 또는 레지스터 값을 저장하고 CPU가 다음 프로세스를 수행하도록 새로운 프로세스의 상태 또는 레지스터 값으로 교체하는 작업을 말한다.
즉, 동작 중인 프로세스가 대기하면서 해당 프로세스의 상태를 보관하고, 대기하고 있던 다음 순번의 프로세스가 동작하면서 이전에 보관했던 프로세스 상태를 복구하는 과정을 말함.
Context는 프로세스의 PCB(Process Control Block)에 저장된다.
따라서 Context Switching 때 PCB의 정보를 읽어(적재) CPU가 전에 프로세스가 일을 하던 것에 이어서 수행이 가능한 것이다.
PCB의 저장정보
- 프로세스 상태: 생성, 준비, 수행, 대기, 중지
- 프로그램 카운터: 프로세스가 다음에 실행할 명령어 주소
- 레지스터
- 프로세스 번호
Context Switching 때 해당 CPU는 아무런 일을 하지 못한다. 따라서 Context Switching이 잦아지면 오히려 오버헤드가 발생해 효율(성능)이 떨어진다.
#멀티 스레드
하나의 응용 프로그램에서 여러 스레드를 구성해 각 스레드가 하나의 작업을 처리하는 것
스레드들이 공유 메모리를 통해 다수의 작업을 동시에 처리하도록 해줌
- 장점
- 독립적인 프로세스에 비해 공유 메모리만큼의 시간, 자원 손실이 감소
- 전역 변수와 정적 변수에 대한 자료 공유 가능
- 단점
- 안전성 문제
- 하나의 스레드가 데이터 공간을 망가뜨리면, 모든 스레드가 작동 불능 상태 (공유 메모리를 가지기 때문)
멀티스레드의 안전성에 대한 단점은 Critical Section 기법을 통해 대비한다.
Critical Section
하나의 스레드가 공유 데이터 값(임계 영역, critical section)을 변경하는 시점에 다른 스레드가 그 값을 읽으려 할 때 발생하는 문제를 해결하기 위한 동기화 과정 문제를 해결하기 위한 동기화 기법
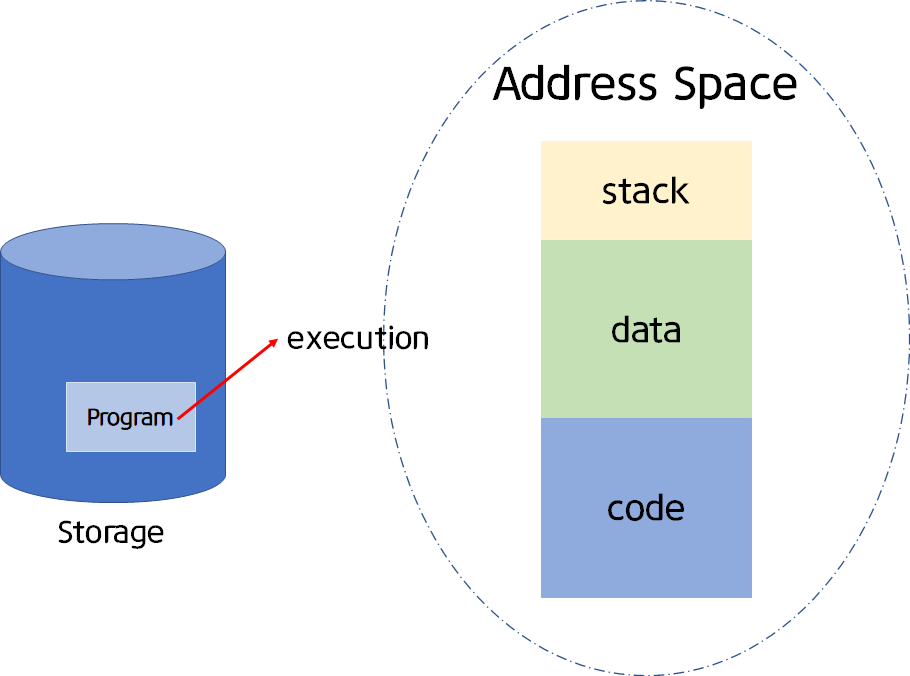
#프로세스 주소 공간
프로그램이 CPU에 의해 실행됨 -> 프로세스가 생성되고 메모리에 프로세스 주소 공간이 할당됨
프로세스 주소 공간에는 코드, 데이터, 스택으로 이루어져 있다.
- 코드 부분(Code Segment)
프로그램의 코드가 저장되어 있다.
읽기만 가능하다.- 데이터 부분(Data Segment)
전역 변수(global variables)같은 데이터가 저장되어 있다.
읽고 쓰기가 가능하다.- 스택 부분(Stack Segment)
함수(function)나 지역 변수(local variables)가 저장되어 있다.
읽고 쓰기가 가능하다.#구역을 나눈 이유
최대한 데이터를 공유하여 메모리 사용량을 줄여야 한다.
Code는 프로그램이 만들어지고 나서는 바뀔 일이 없다. 따라서 같은 프로그램을 실행시켜 몇 개의 Process가 실행되더라도 같은 프로그램이라면 Code 부분은 다 똑같은 내용을 가지고 있게 된다. 따라서 프로그램의 Process일 경우 Code 부분을 공유하여 메모리 사용량을 줄이기 위한 목적이다.
Stack과 Data를 나눈 이유는, 스택 구조의 특성과 전역 변수의 활용성을 위한 것이다.
함수 안에서 공통으로 사용하는 '전역 변수'나 '전역 함수'를 다른 주소 공간에 할당하게 되면 메모리를 아낄 수 있다.
<참고 사이트!>
#참고사이트
