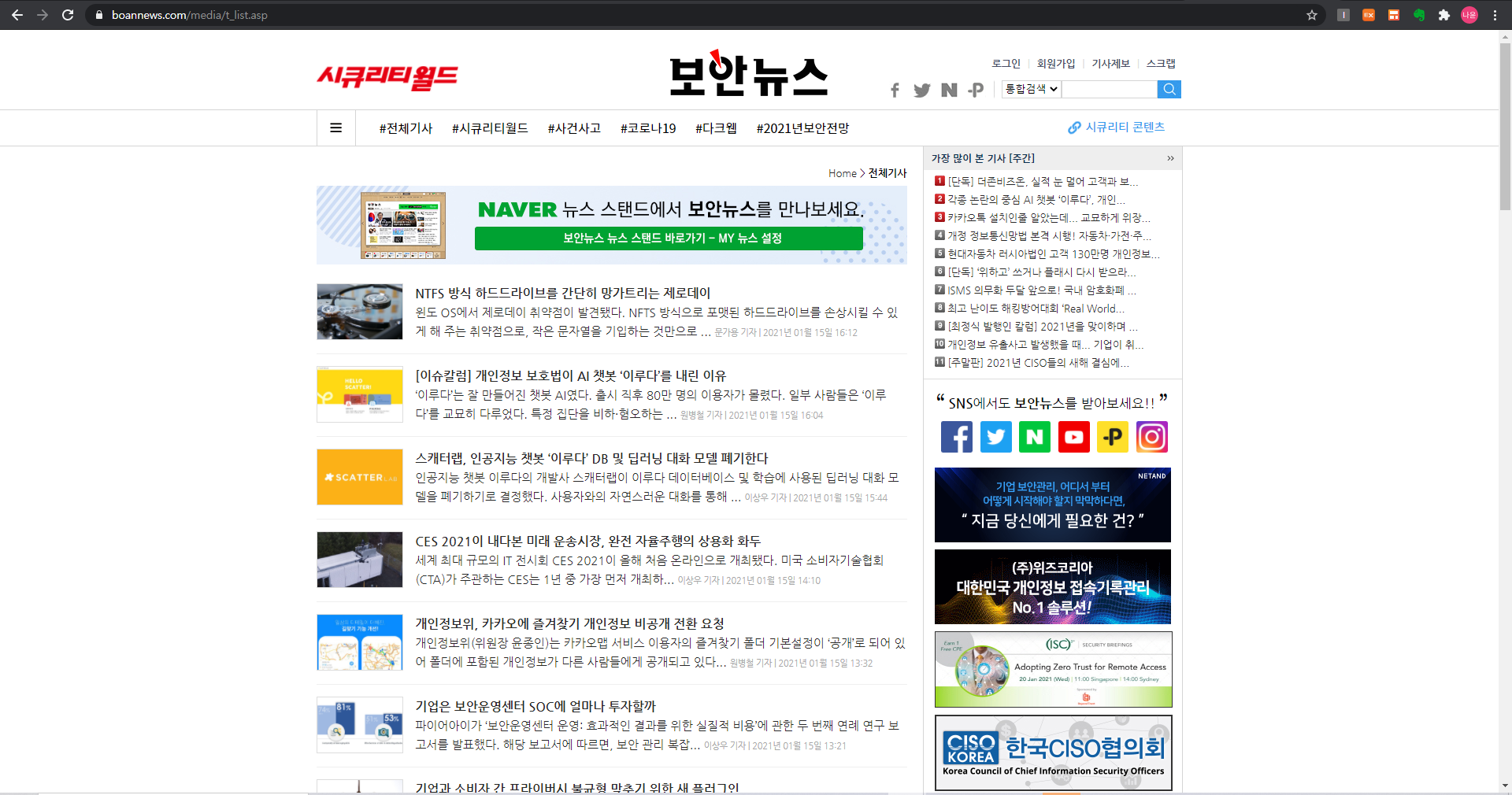
학교 인턴으로 시작한 곳에서 최신 보안 이슈를 알려주는 챗봇을 구현하게 되었다.
파이썬 beautiful soup으로 크롤링을 하고, django를 서버로 쓴다.
보안뉴스, 데일리시큐, wired 총 세 개의 페이지를 크롤링하고 크롤링한 결과를 취합한 후 JsonResponse를 이용해 json형태로 반환한다.
각각의 페이지에서 헤드라인을 5개만 가지고 나오기 때문에 크롤링한 결과를 취합해서 결과를 반환하는 데까지 오랜 시간이 걸리지는 않지만 그다지 효율적인 방식은 아닌 것 같다.
각 사이트에서 title, link, author, date 4개의 데이터를 가지고 나온다.
보안 뉴스를 예로 들면
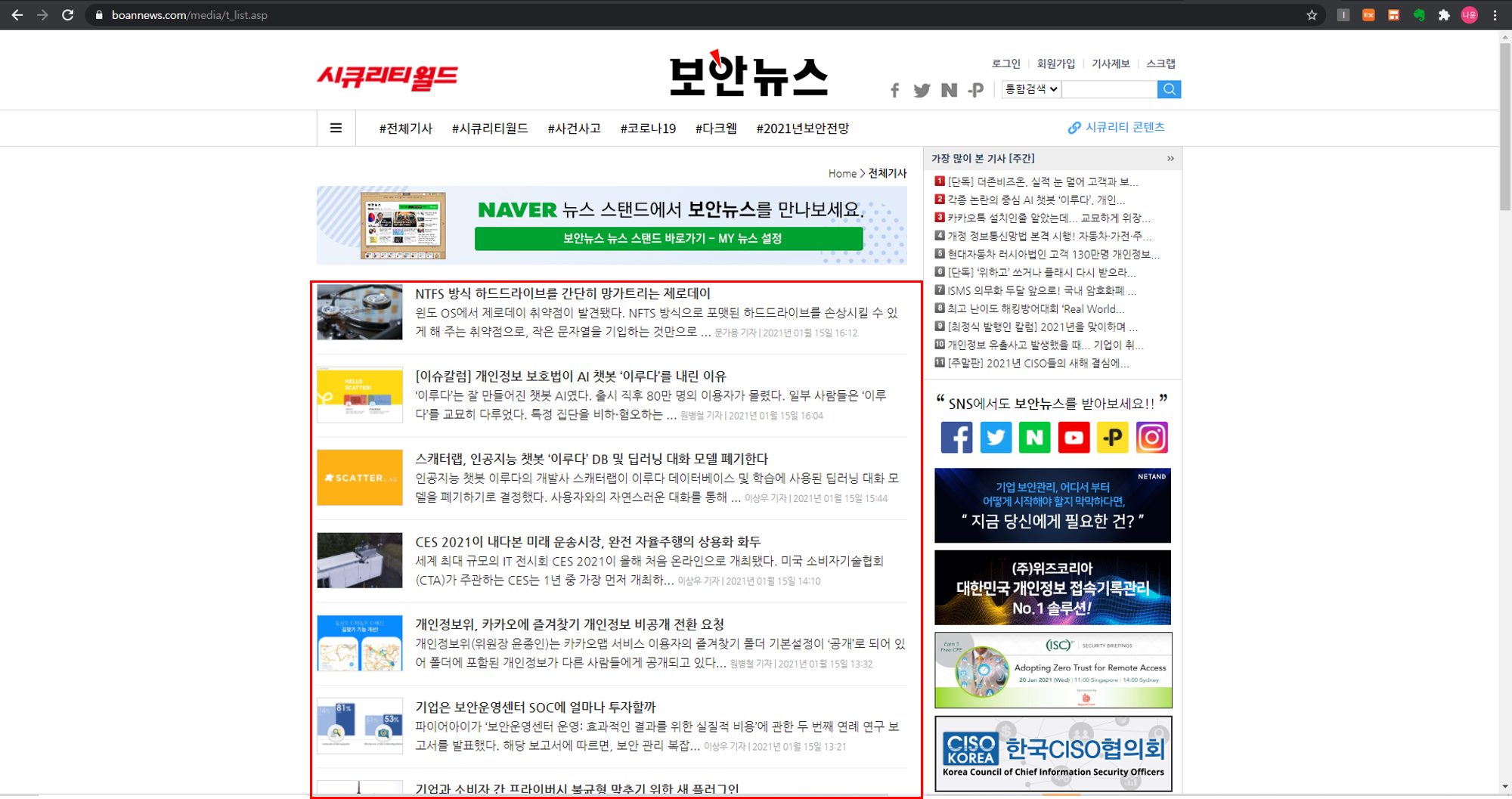
위의 부분을 크롤링을 하는 데, 아래 부분(title, link, author, date)만 크롤링한다.

link는 title을 클릭 시 열리는 링크이다.
# crawling.py
# 최신 보안 뉴스
def boannews():
url = "https://www.boannews.com/media/t_list.asp"
webpage = requests.get(url)
soup = BeautifulSoup(webpage.text, "html.parser")
headline_news = soup.select('div.news_list')
result = dict()
for i, hn in enumerate(headline_news):
headline = str(i + 1)
result[headline] = dict()
result[headline]["title"] = hn.select("span.news_txt")[0].text
result[headline]["link"] = hn.select("a")[0]['href']
result[headline]["author"] = hn.select("span.news_writer")[0].text.split(' | ')[0]
result[headline]["date"] = hn.select("span.news_writer")[0].text.split(' | ')[1]
return result
# 최신 보안 뉴스
def wired_security():
url = "https://www.wired.com"
security_feature = "/category/security"
webpage = requests.get(url + security_feature)
soup = BeautifulSoup(webpage.text, "html.parser")
headline_news = soup.select("div.cards-component__row li.card-component__description")
result = dict()
for i, hn in enumerate(headline_news):
headline = str(i + 1)
result[headline] = dict()
result[headline]["title"] = hn.select('a h2')[0].text
result[headline]["link"] = hn.select('a')[0]['href']
result[headline]["author"] = hn.select('a.byline-component__link')[0].text
# 이 부분!
_soup = BeautifulSoup(requests.get(url+result[headline]["link"]).text, "html.parser")
result[headline]["date"] = _soup.select_one("div.content-header__row.content-header__title-block time").text
return result
# 최신 보안 뉴스
def dailysecu():
url = "https://www.dailysecu.com/news/articleList.html?sc_section_code=S1N2&view_type=sm"
webpage = requests.get(url)
soup = BeautifulSoup(webpage.text, "html.parser")
headline_news = soup.select('div.list-block')
result = dict()
for i, hn in enumerate(headline_news):
author_and_date = hn.select("div.list-dated")[0].text.split(' | ')[1:3]
headline = str(i + 1)
result[headline] = dict()
result[headline]["title"] = hn.select("div.list-titles")[0].text
result[headline]["link"] = hn.select("div.list-titles")[0].find("a")["href"]
result[headline]["author"] = author_and_date[0]
result[headline]["date"] = author_and_date[1]
return result
# 최신 보안 이슈를 크롤링해오고 취합하는 메소드
def newest_news():
_boannews = boannews()
_wired_security = wired_security()
_dailysecu = dailysecu()
result = dict()
for i in range(1, 6):
number = str(i)
b_number = str(i)
w_number = str(i+5)
d_number = str(i+10)
result[b_number] = dict()
result[b_number]["title"] = _boannews[number]["title"]
result[b_number]["link"] = _boannews[number]["link"]
result[b_number]["author"] = _boannews[number]["author"]
result[b_number]["date"] = _boannews[number]["date"]
result[w_number] = dict()
result[w_number]["title"] = _wired_security[number]["title"]
result[w_number]["link"] = _wired_security[number]["link"]
result[w_number]["author"] = _wired_security[number]["author"]
result[w_number]["date"] = _wired_security[number]["date"]
result[d_number] = dict()
result[d_number]["title"] = _dailysecu[number]["title"]
result[d_number]["link"] = _dailysecu[number]["link"]
result[d_number]["author"] = _dailysecu[number]["author"]
result[d_number]["date"] = _dailysecu[number]["date"]
return result각 페이지에 맞게 크롤링을 진행하고 wired 사이트의 경우에는 date 결과를 바로 가지고 올 수 없어서 링크를 타고 들어가서 가지고 나온다.
각각의 보안 이슈들을 크롤링해온 이후에 newest_news에서 취합해서 dictionary 형태로 반환한다.
# views.py
import crawling
@csrf_exempt
def news_list(request):
if request.method == 'GET':
data = crawling.newest_news()
return JsonResponse(data, status=200)위 부분이 GET 요청 시, crawling.newest_news() 로 크롤링해서 결과값을 반환하는 부분이다. JsonResponse를 통해 json 형태로 반환된다.
아래 화면은 Postsman으로 요청 후 응답값을 받아오는 부분이다.
(위와 같이 구현하면 아래와 같은 화면을 얻을 수 있다.)
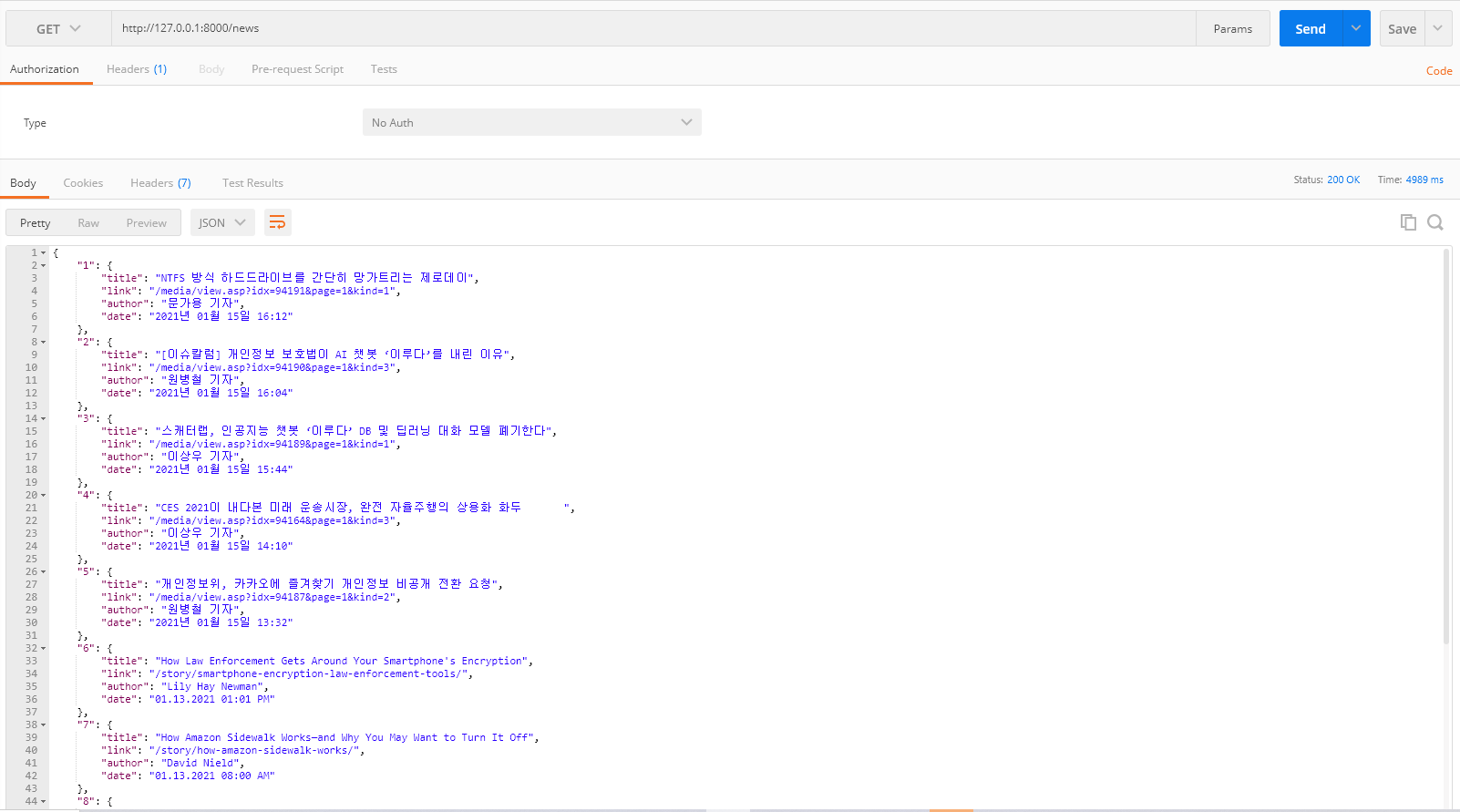
15개의 뉴스 헤드라인을 얻을 수 있다.

뚜벅뚜벅 열심히 공부하는 개발자