
그래프를 탐색하는 방법에는 크게 DFS (깊이 우선 탐색)과 BFS (너비 우선 탐색) 이 있다.
💡 그래프란 ?
정점 (node)과 그 정점을 연결하는간선 (edge)으로 이루어진 자료구조- 그래프를 탐색한다는 것은 하나의 정점으로부터 시작해 차례대로 모든 정점들을 한 번씩 방문한다는 것을 말함.
깊이 우선 탐색 (DFS)
최대한 깊이 내려간 뒤, 더이상 깊이 갈 곳이 없을 경우 이전 정점으로 돌아가는 방식이다.
루트 노드에서 시작해서 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색한다.
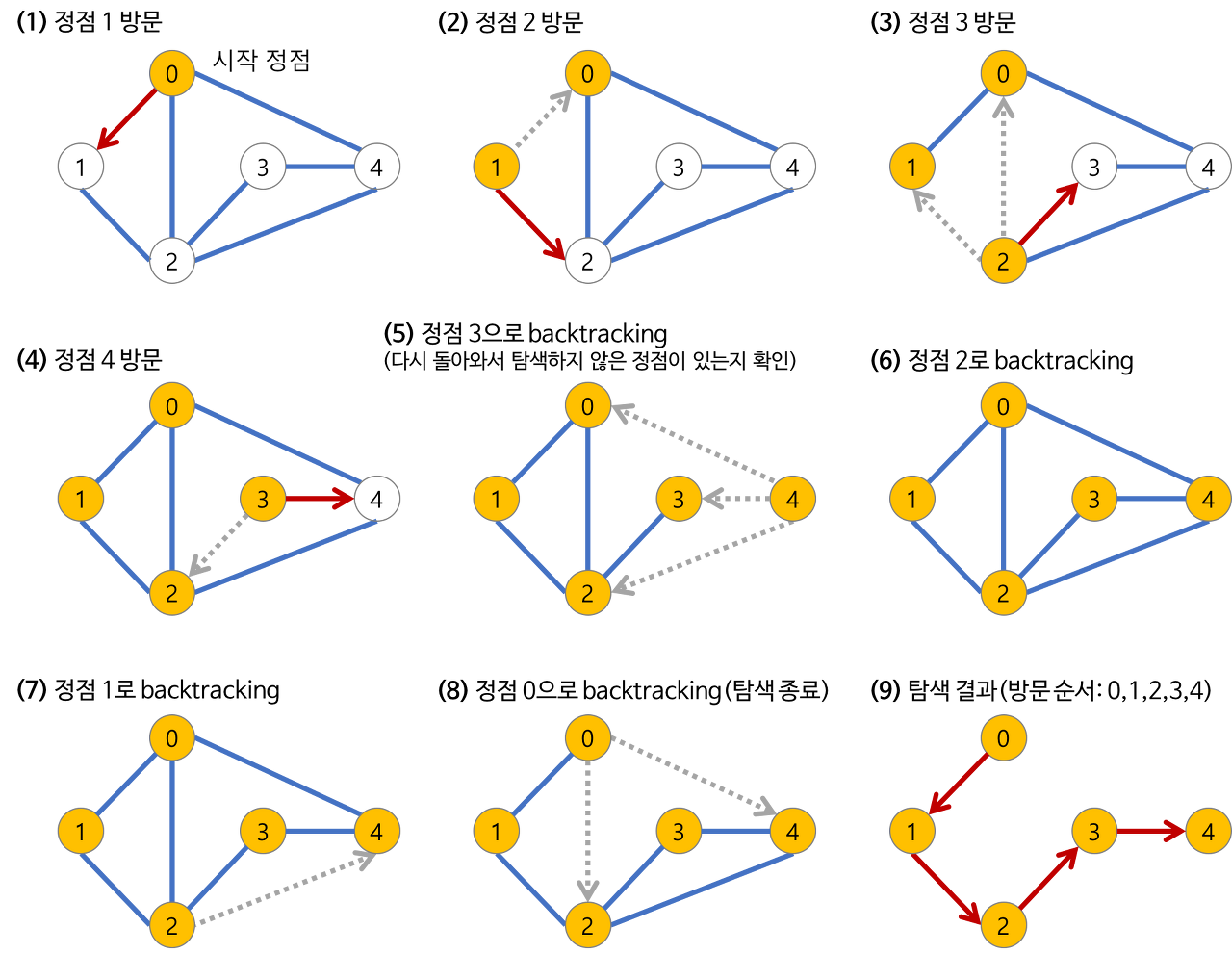
장단점
- 현 경로상의 노드들만 기억하면 되므로 저장 공간의 수요가 적다.
- 목표 노드가 깊은 단계에 있을 경우 해를 빨리 구할 수 있다.
- 해가 없는 경로에 깊이 빠질 가능성이 있다.
- 얻어진 해가 최단 경로가 된다는 보장이 없다.
- 깊이가 무한히 깊어지면 스택 오버플로우가 날 위험이 있다.
구현 (코드)
DFS 는 인접 행렬 (adjacency matrix)과 인접 리스트 (adjacency list)를 통해 구현할 수 있다.
인접 행렬
- 2차원 배열에 정점과 간선을 넣어 인접 배열 생성 (연결 관계 추가)
- DFS 호출하면 방문 배열에 방문 처리 후, 정점 출력
- 현재 정점과 인접한 정점들을 순회하며 (Iterator 활용) 인접 정점 탐색
3.1. 아직 방문하지 않은 정점이면 방문 처리 후 DFS 재귀 호출 - 더 이상 방문하지 않은 정점 없을 때까지 탐색 후 종료
import java.util.*;
public class DFS {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 정점의 개수
int m = sc.nextInt(); // 간선의 개수
int v = sc.nextInt(); // 탐색을 시작할 정점의 번호
boolean visited[] = new boolean[n + 1]; // 방문 여부를 검사할 배열
int[][] adjArray = new int[n+1][n+1];
// 인접 행렬에 연결된 노드 추가 (양방향)
for(int i = 0; i < m; i++) {
int v1 = sc.nextInt();
int v2 = sc.nextInt();
adjArray[v1][v2] = 1;
adjArray[v2][v1] = 1;
}
System.out.println("DFS - 인접행렬 / 재귀로 구현");
dfs(v, adjArray, visited);
}
//DFS - 인접행렬 / 재귀로 구현
public static void dfs(int v, int[][] adjArray, boolean[] visited) {
int l = adjArray.length-1;
visited[v] = true;
System.out.print(v + " ");
for(int i = 1; i <= l; i++) {
if(adjArray[v][i] == 1 && !visited[i]) { // 연결돼있고 아직 방문 전이라면
dfs(i, adjArray, visited);
}
}
}
}DFS 하나당 N번의 루프를 돌게 되고, 총 N개의 정점을 모두 방문해야 하므로 O(N^2) 의 시간복잡도를 가진다.
인접 리스트
- 리스트에 정점과 간선을 넣어 인접 리스트 생성 (연결 관계 추가)
다음 단계들은 위의 인접 행렬 단계와 같음.
- 인접 행렬과 달리 해당 정점을 기준으로 연결된 정점만 탐색하게 되므로 if문에서 연결되었는지 확인하는 조건문을 필요 x, 방문 여부만 체크 !
import java.util.*;
public class DFS {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 정점의 개수
int m = sc.nextInt(); // 간선의 개수
int v = sc.nextInt(); // 탐색을 시작할 정점의 번호
boolean visited[] = new boolean[n + 1]; // 방문 여부를 검사할 배열
LinkedList<Integer>[] adjList = new LinkedList[n + 1]; // 인접 리스트
// 초기화 과정 (꼭 필요 !!)
for (int i = 0; i <= n; i++) {
adjList[i] = new LinkedList<Integer>();
}
// 인접 리스트에 연결된 노드 추가 (양방향)
for (int i = 0; i < m; i++) {
int v1 = sc.nextInt();
int v2 = sc.nextInt();
adjList[v1].add(v2);
adjList[v2].add(v1);
}
// 방문 순서를 위해 오름차순 정렬 (자식 여러개면 작은 것부터 방문)
for (int i = 1; i <= n; i++) {
Collections.sort(adjList[i]);
}
System.out.println("DFS - 인접리스트");
dfs(v, adjList, visited);
}
// DFS - 인접리스트 - 재귀로 구현
public static void dfs(int v, LinkedList<Integer>[] adjList, boolean[] visited) {
visited[v] = true; // 정점 방문 표시
System.out.print(v + " "); // 정점 출력
Iterator<Integer> iter = adjList[v].listIterator(); // 정점 인접리스트 순회
while (iter.hasNext()) {
int w = iter.next();
if (!visited[w]) // 방문하지 않은 정점이라면
dfs(w, adjList, visited); // DFS 재귀 호출
}
}
}DFS가 총 N번 호출되긴 하지만 인접 행렬과 달리, DFS 하나당 각 정점에 연결되어 있는 간선 개수만큼 탐색하므로 예측이 불가능하다.
하지만 DFS 가 다 끝난 후를 생각하면 결국 모든 정점과 간선을 한 번씩 검사했다고 볼 수 있으므로 O(N + E) 의 시간복잡도를 가진다.
너비 우선 탐색 (BFS)
최대한 넓게 이동한 다음, 더 이상 갈 수 없을 때 아래로 이동하는 방식이다.
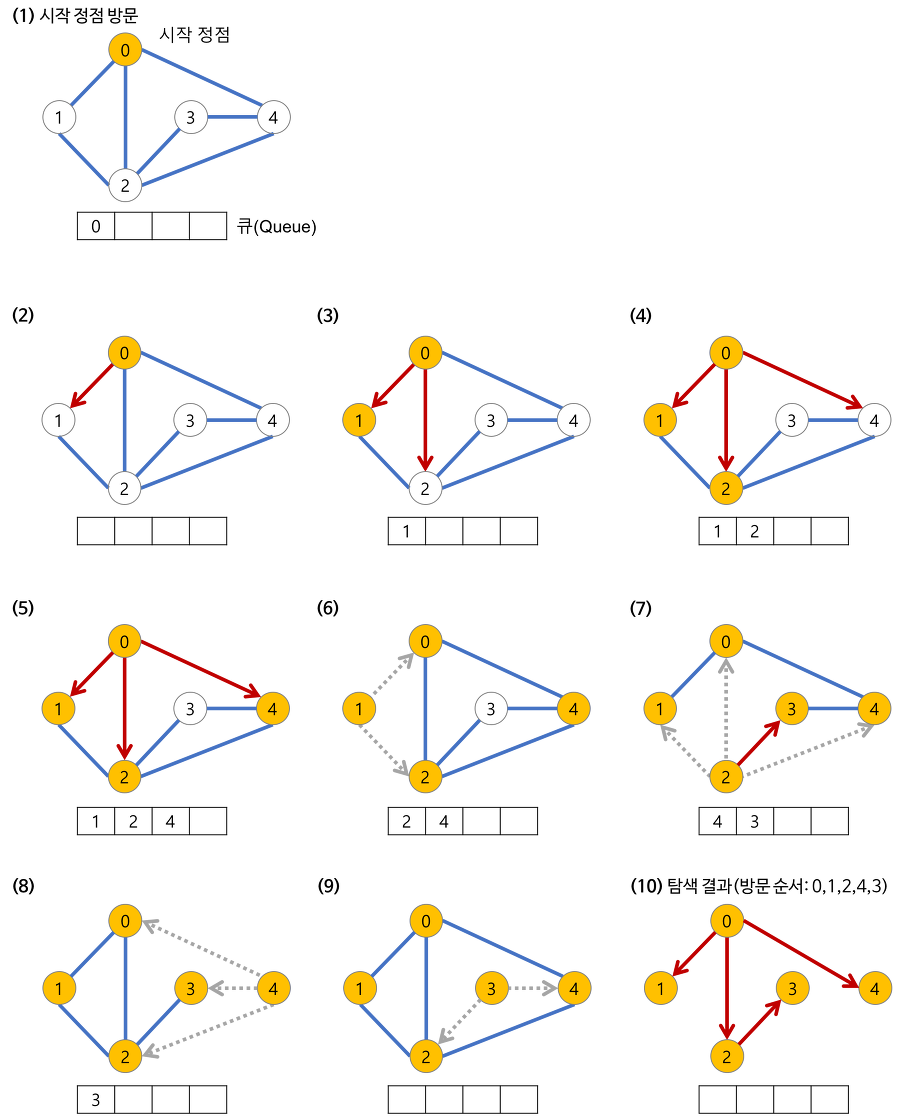
DFS 는 갈림길에서 하나의 길로 들어서서 막다른 길이 나올 때까지 깊게 탐색을 하지만, BFS 는 갈림길에 연결되어 있는 모든 길을 한 번씩 탐색한 뒤 다시 연결되어 있는 모든 길을 넓게 탐색한다.
장단점
- 답이 되는 경로가 여러 개인 경우에도 최단 경로를 얻을 수 있다.
- 경로가 무한히 깊어져도 최단 경로를 반드시 찾을 수 있다.
- 노드 수가 적고 깊이가 얕은 해가 존재할 때 유리하다.
- DFS 와 달리
큐를 이용하므로 다음 탐색할 정점들을 저장하므로 더 큰 저장공간이 필요하다.
구현 (코드)
BFS 도 마찬가지로 인접 행렬과 인접 리스트로 구현할 수 있다.
기본 구현 원리는 Queue 를 활용한다는 것이다 !
인접 행렬
- 2차원 배열에 정점과 간선을 넣어 인접 행렬 생성 (연결 관계 추가)
- 큐 생성 후 시작 정점 v 를 큐에 넣음
- 큐의 front 를 꺼낸 후 (poll), 이를 기준으로 간선이 연결되어있고 아직 방문 전이라면 방문 표시해준다.
- 큐가 빌 때까지 탐색 후 종료한다.
import java.util.*;
public class BFS {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 정점의 개수
int m = sc.nextInt(); // 간선의 개수
int v = sc.nextInt(); // 탐색을 시작할 정점의 번호
boolean visited[] = new boolean[n + 1]; // 방문 여부를 검사할 배열
int[][] adjArray = new int[n+1][n+1];
// 인접 행렬에 연결된 노드 추가 (양방향)
for(int i = 0; i < m; i++) {
int v1 = sc.nextInt();
int v2 = sc.nextInt();
adjArray[v1][v2] = 1;
adjArray[v2][v1] = 1;
}
System.out.println("BFS - 인접행렬");
bfs(v, adjArray, visited);
}
// BFS - 인접행렬
public static void bfs(int v, int[][] adjArray, boolean[] visited) {
Queue<Integer> q = new LinkedList<>();
int n = adjArray.length - 1;
q.add(v); // 큐에 추가
visited[v] = true; // 방문 처리
while (!q.isEmpty()) {
v = q.poll();
System.out.print(v + " ");
for (int i = 1; i <= n; i++) {
if (adjArray[v][i] == 1 && !visited[i]) { // 연결돼있고 아직 방문 전이라면
q.add(i);
visited[i] = true;
}
}
}
}
}O(N^2) 의 시간복잡도를 가진다.
인접 리스트
import java.util.*;
public class BFS {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 정점의 개수
int m = sc.nextInt(); // 간선의 개수
int v = sc.nextInt(); // 탐색을 시작할 정점의 번호
boolean visited[] = new boolean[n + 1]; // 방문 여부를 검사할 배열
LinkedList<Integer>[] adjList = new LinkedList[n + 1];
// 초기화 과정
for (int i = 0; i <= n; i++) {
adjList[i] = new LinkedList<Integer>();
}
// 인접 행렬에 연결된 노드 추가 (양방향)
for (int i = 0; i < m; i++) {
int v1 = sc.nextInt();
int v2 = sc.nextInt();
adjList[v1].add(v2);
adjList[v2].add(v1);
}
// 방문 순서를 위해 오름차순 정렬
for (int i = 1; i <= n; i++) {
Collections.sort(adjList[i]);
}
System.out.println("BFS - 인접리스트");
bfs(v, adjList, visited);
}
// BFS - 인접리스트
public static void bfs(int v, LinkedList<Integer>[] adjList, boolean[] visited) {
Queue<Integer> queue = new LinkedList<Integer>();
visited[v] = true;
queue.add(v);
while(queue.size() != 0) {
v = queue.poll();
System.out.print(v + " ");
Iterator<Integer> iter = adjList[v].listIterator();
while(iter.hasNext()) { // 정점과 연결된 정점 탐색
int w = iter.next();
if(!visited[w]) { // 방문 전이면
visited[w] = true;
queue.add(w);
}
}
}
}
}O(N + E) 의 시간복잡도를 가진다.
DFS VS BFS
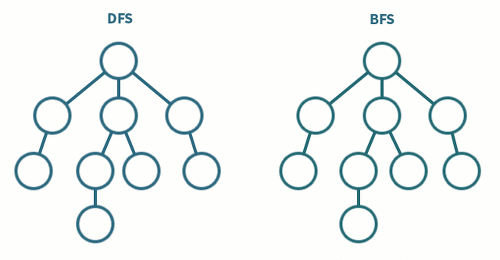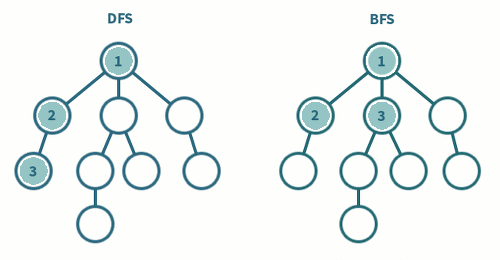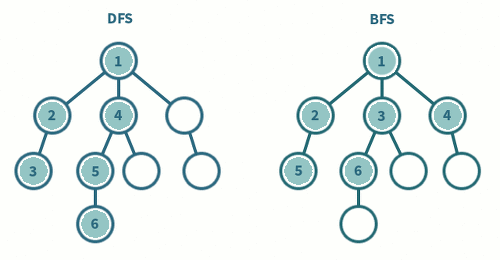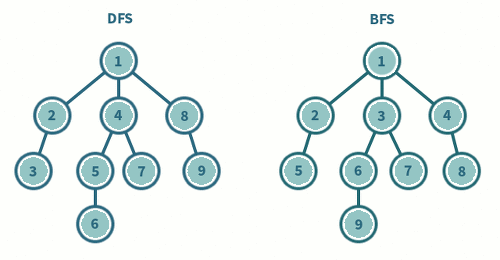
- DFS 는
스택또는재귀, BFS 는큐를 사용한다. - BFS 는 재귀적으로 동작하지 않는다 !!
시간 복잡도
두 방식 모두 조건 내에서 모든 노드를 검색한다는 점에서 시간 복잡도는 동일하다.
텍스트
N 은 노드, E 는 간선 일 때,
- 인접 행렬 :
O(N^2) - 인접 리스트 :
O(N + E)
-> 일반적으로 인접 리스트 방식이 더 효율적
문제 유형
- 경로의 특징을 저장해둬야 하는 문제 -> DFS
- 최단 거리를 구해야 하는 문제 (미로 찾기 등) -> BFS
+) 검색 대상 그래프가 정말 크다면 -> DFS
규모가 그렇게 크지 않고, 검색 시점으로부터 원하는 대상 가깝다면 -> BFS
