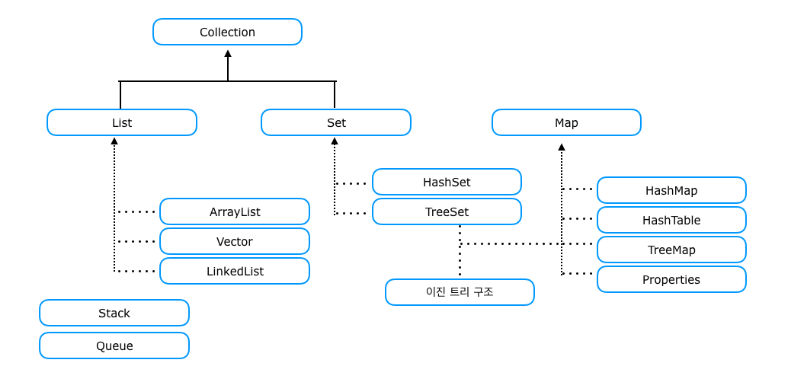
컬렉션 프레임워크
- 여러 개의 데이터 묶음 자료를 효과적으로 처리하기 위해 구조화된 클래스 또는 인터페이스의 모음
- 자료구조 (Data Structure)와 알고리즘 (Algorithm)을 구조화한 클래스
- 자바 인터페이스(Interface)를 구현한 형태로 작성된 클래스
- 대표적으로 List, Set, Map, Stack, Queue 등이 있다.
List Interface
- 목록 관리
- 순서 있는 목록
- 배열 대신 사용
- 요소 추가 / 삭제 / 수정
- 요소의 중복 저장 가능
객체를 일렬로 늘어놓은 구조를 가지고 있다.
객체를 인덱스로 관리하기 때문에 객체를 저장하면 자동 인덱스가 부여되고 인덱스로 객체를 검색, 삭제할 수 있다.
인덱스에는 데이터가 저장되어 있는 참조 값을 가지고 있다.
객체 자체를 저장하는 것이 아닌 객체의 번지를 참조한다.
제네릭
- 모든 컬렉션 프레임워크는 제네릭(generic) 기반으로 구현된 클래스
- 어떤 컬렉션 프레임워크를 생성할 때 어떤 타입을 저장할 것인지 구체적으로 명시하는 것
- 제네릭으로 지정 가능한 타입은 오직 참조 타입 (Reference Type)만 사용 가능
- 기본 타입이 필요한 경우 기본 타입의 Wrapper Class를 사용
List<int.> X ---> List<Integer.> O
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
// 비어있는 리스트인가?
boolean result = list.isEmpty();
// 특정 요소를 포함하고 있는가?
if(list.contains(4)) {
System.out.println("4를 포함한다")
} else {
System.out.println("4를 포함하지 않는다")
}ArrayList
- 패키지 : java.util
- 배열(Array)을 리스트로 구현한 클래스
- 배열보다 쉬운 사용법을 제공
- 주요기능
- 리스트 길이 자동 세팅
- 요소의 추가/수정/삭제
- 인덱스 기반의 접근
- 특정 요소 조회
- 리스트와 배열의 상호 변환
ArrayList list = new ArrayList();
▶List list = new ArrayList():
■ 생성 >
- 제네릭 (Generic) 기반
- 생성할 때 데이터타입을 결정 (구체화)
List <String> list = new ArrayList<String>();■ 요소추가 >
- 인덱스 지정이 없으면 순서대로 저장
- 인덱스 지정도 가능
list.add("월");
list.add("화");
list.add(0,"일");■ 요소제거 >
- boolean remove(Object obj) : obj 제거, 성공하면 true 반환
- Object remove(int index) : index 위치의 요소 제거, 제거한 요소 반환
boolean result = list.remove("일");
System.out.println(result);
String removeItem = list.remove(0);
System.out.println(removeItem);■ 요소수정 >
list.set(0,"일");■ 리스트 확인 >
System.out.println(list);■ 리스트 초기화 >
- 배열을 리스트로 변환
- 고정된 크기를 가짐 (길이가 고정되어 추가, 삭제 불가)
asList(String ... a) → String이 여러개 들어갈 수 있다. 갯수는 정해지지 않음.
List<String> list = Arrays.asList("일","월","화","수")■ 리스트 길이
int size = list.size();
System.out.println(size);■ 개별 요소
String element1 = list.get(0);
String element2 = list.get(1);
String element3 = list.get(2);
String element4 = list.get(3);
System.out.println(element1);
System.out.println(element2);
System.out.println(element3);
System.out.println(element4);■ for문 순회
-
size메소드 호출을 한 번만 진행한다.
- 기존배열
String[] arr = {"일","월","화","수"}; for ( int i = 0; i < arr.length; i++ ) { System.out.println(arr[i]); } for (int i = 0; i < list.size(); i++ ) { System.out.println(list.get(i)); }→ list의 사이즈 메소드를 여러번 호출하여 성능이 떨어짐
- 개선
for(int i = 0, length = list.size(); i < length; i++) { System.out.println(list.get(i)); }→ list의 사이즈 메소드를 한번만 호출
- 향상 for문 순회
for(String element : list) { System.out.println(element); }
Set Interface
- 집합 관리
- 순서 없는 목록
- 교집합 / 합집합 / 차집합 등
- 요소 추가 / 삭제 / 수정
- 요소의 중복 저장 불가능
인덱스 정보를 포함하고 있지 않은 집합의 개념과 같은 컬렉션이다.
인덱스 정보가 없으므로 데이터를 중복 저장하면 중복된 데이터 중 특정 데이터를 지칭해 꺼낼 방법이 없다.
저장 순서가 유지되지 않기 때문에 인덱스로 객체를 검색해서 가져오는 get(index) 메소드도 없다.
인덱스가 없기 때문에 순서가 없음
hash set
- 패키지 : java.util
- 집합을 관리하기 위한 구조
- 중복된 요소가 저장되지 않는 특성을 가짐
- 인덱스가 없어 순서대로 저장되지 않는 특성을 가짐
- 해시(Hash)를 이용하기 때문에 삽입, 삭제, 검색이 빠름
- HashSet의 주요기능
- 세트 길이 자동 세팅
- 요소의 추가/수정/삭제
- 리스트와 세트의 상호 변환
- 교집합, 합집합, 차집합, 부분집합 등 집합 연산
set인터페이스의 대표 구현 클래스.
모든 데이터를 하나의 주머니에 넣어 관리하므로 입력 순서와 다르게 출력될 수 있다.
객체가 같은 내용을 지니더라도 가리키는 주소가 다르면 다른 값을 지닌다.
■ 세트 생성
Set<String> set = new HachSet<String>();■ 요소 추가
set.add("일");
set.add("월");
set.add("화");
set.add("수");
set.add("수"); // 중복 저장 시도■ 요소 제거
boolean result = set.remove("일");
System.out.println(result);■ 세트 확인
System.out.println(set);■ 세트의 초기화
- 리스트를 세트로 변환하는 방식으로 초기화 진행
Set<String> set = new HashSet<String>(Arrays.asList("일", "월", "화", "수"));■ 세트의 길이
int size = set.size();
System.out.println(size);■ 향상 for문 가능 ( 인덱스가 없으므로 일반 for문 불가능 )
for(String element : set) {
System.out.println(element);
}Set<Integer> set1 = new HashSet<Integer>(Arrays.asList(1,2,3,4,5));
Set<Integer> set2 = new HashSet<Integer>(Arrays.asList(3,4,5,6,7));
Set<Integer> set3 = new HashSet<Integer>(Arrays.asList(6,7));■ 교집합
- 교집합의 결과는 retainAll() 메소드를 호출한 set에 저장
set1.retainAll(set2);
■ 합집합
- 합집합 결과는 addAll() 메소드를 호출한 set에 저장
set1.addAll(set2);
■ 차집합
- 차집합 결과는 removeAll() 메소드를 호출한 set에 저장
set1.removeAll(set2);
■ 부분집합 여부 판단
boolean result1 = set1.containAll(set3); // set3가 set1의 부분집합이면 true
boolean result2 = set2.containAll(set3); // set3가 set2의 부분집합이면 true
■ 중복 요소가 있는 리스트 → 세트 변환 → 다시 리스트로 변환
List<String> list = new ArrayList<String>();
list.add("일");
list.add("월");
list.add("화");
list.add("화");
Set<String> set = new HashSet<String>(list);
list.clear(); // list 요소 모두 제거
list = new ArrayList<String>(set);Map ★
키(Key)와 값(Value)으로 구성된 객체를 저장하는 구조를 가지고 있는 자료구조.
Key는 중복 저장 불가, Value는 중복 저장 가능
중복된 key값이 들어오면 기존의 값은 없어지고 새로운 값으로 대치된다.
hash map
map -> mapping
구조 : Map < Key, Value>
- 패키지 : java.util
- 키(key)와 값(value)으로 하나의 Entry가 구성되는 자료 구조
- 저장하려는 데이터는 값이고, 값을 알아내기 위해서 키를 사용
- 값(Value)은 중복이 가능하지만 키(key)는 중복이 불가능
- 해시(Hash)를 이용하기 때문에 삽입, 삭제, 검색이 빠름
- HashMap의 주요 기능
- 요소의 삽입/삭제/수정
- 일치하는 키(key) 검색
- 일치하는 값(value) 검색
// Map 생성
// Map<Key, Value>
Map<String, String> dictionary = new HashMap<String, String<();
// 추가
// 새로운 key값을 사용하면 추가
dictionary.put("apple", "사과"); // put(Key, Value) 사과라는 value를 꺼내려면 apple이라는 key값이 필요
dictionary.put("banana", "바나나");
dictionary.put("tomato", "토마토");
dictionary.put("mango", "망고");
dictionary.put("melon", "멜론");
// 수정
// 기존의 Key 값을 사용하면 수정
dictionary.put("melon", "메론");
// 삭제
// 삭세할 요소의 key를 전달하면 삭제되고 삭제된 value 반환
String removeItem = dictionary.remove("tomato");
System.out.println(removeItem); // 토마토
// 값(Value)의 확인
System.out.println(dictionary.get("apple")); // 사과
System.out.println(dictionary.get("peach")); // null
// Value를 String으로 관리하기
Map<String, String> map1 = new HashMap<String, String>();
map1.put("title", "어린왕자");
map1.put("author", "생텍쥐베리");
map1.put("price", 10000 +"");
// Value를 String으로 관리하기
Map<String, Object> map2 = new HashMap<String, Object>();
map2.put("title", "홍길동전");
map2.put("author", "허균");
map2.put("price", 20000);
Map<String, Object> map = new HashMap<String, Object>();
map.put("title", "소나기");
map.put("author", "황순원");
map.put("price", 20000);
// Entry 단위로 순회 (for)
for(Map.Entry<String, Object> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
// Key를 이용한 순회 (for)
for(String key : map.keySet()) {
System.out.println(key + " : " + map.get(key));
hash algorithm
- 해시(Hash)
다양한 길이를 가진 데이터를 고정된 길이를 가지는 데이터로 매핑(Mapping) 한 값
어떤 데이터를 저장할 때 해당 데이터의 해시값을 계산해서 인덱스(index)로 사용함
어떤 데이터를 검색할 때 해당 데이터의 해시값을 인덱스(index)로 사용하면 되기 때문에 빠른 조회가 가능
Hash 기반 컬렉션
-
자바의 해시 (Hash)
- 모든 객체는 Object클래스의 hashCode()메소드가 반환하는 값을 해시값으로 사용
- Object 클래스의 hashCode() 메소드는 객체의 참조값을 반환하기 때문에 모든 객체는 서로 다른 해시값을 가짐
- 필드값이 동일한 객체도 서로 다른 해시값을 가지므로 서로 다른 객체로 인식함
- 필드값이 동일한 경우 동일한 객체로 인식시키기 위해서는 hashCode() 메소드를 목적에 맞게 오버라이드 해야함
-
해시(Hash)기반 컬렉션
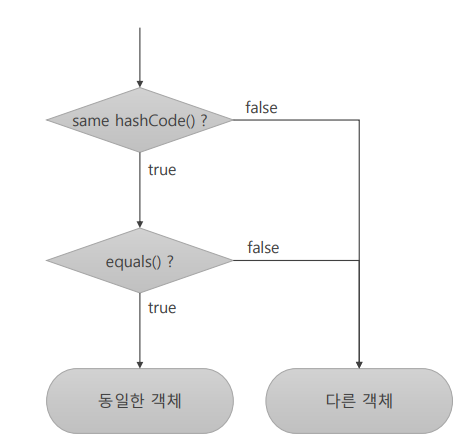
- HashSet, HashMap, HashTable 등
- 요소들의 중복 저장 방지하기 위해서 hashCode() 메소드와 equals() 메소드를 사용함
- 우선 hashCode()메소드를 비교해서 해시값이 같으면 동일한 객체일 가능성이 있는 것으로 판단
- 다른 해시값을 가지는 경우 동일한 객체일 가능성이 없으므로 equals()메소드를 호출하지 않음
Entry 단위 순회
Entry : key , value
for ( Entry entry : map, entrySet() )
entry.getKey()
entry.getValue()
Key 단위 순회
map.getKey == value
for (String key : map.keySet())
map.get(key)
tree map
- 이진 트리 (binary tree)
- 모든 노드는 2개의 자식을 가질 수 있다
- 작은 값은 왼쪽, 큰 값은 오른쪽에 저장한다.
- key를 기준으로 왼쪽에 작은 값, 오른쪽에 큰 값이 저장된다.
- key를 기준으로 자동으로 정렬되면서 저장된다.
- 크기 비교 및 범위 연산에 적절하다.
Map<Integer, String> map = new TreeMap<Integer, String>();
map.put(65, "제시카");
map.put(85, "에밀리");
map.put(35, "제임스");
map.put(95, "사만다");
System.out.println(map); // key를 기준으로 정렬되어 있음
// 결과
{35=제임스, 65=제시카, 85=에밀리, 95=사만다}
// 순회
for(Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue());
- TreeMap은 TreeMap만 사용할 수 있는 메소드가 다수 있으므로 TreeMap 타입으로 생성하는 것이 좋다.
■ 기본 정렬 : 오름차순 정렬
TreeMap<Integer, String> map = new TreeMap<Integer, String> ();
map.put(65, "제시카");
map.put(85, "에밀리");
map.put(35, "제임스");
map.put(95, "사만다");결과

■ 정렬 변경 : descendingMap() 메소드 호출
- 오름차순 정렬 ↔ 내림차순 정렬
NavigableMap<Integer, String> map2 = map.descendingMap();
for ( Map.Entry<Integer,String> entry : map.entrySet() {
System.out.println(entry.getKey() + " : " + entry.getValue());
}
// 다시 descendingMap() 메소드를 호출하면 오름차순 정렬이 된다.
NavigableMap<Integer, String> map3 = map.descendingMap();
for ( Integer Key : map.keySet()){
System.out.println(key + " : " + map3.get(key));
}결과

Iterator
- 특정 컬렉션 ( interface Collection )에 등록해서 사용
- 순회할 때 사용 ( for문 대용 )
- 주로 Set에서 사용
- 주요 메소드
- hasNext() : 남아있는 요소가 있으면 true 반환
- next() : 요소를 하나 반환
Set<String>set = new HashSet<String>();
set.add("제육");
set.add("닭갈비");
set.add("돈까스");
set.add("김치찌개");
// set를 조회할 반복자 itr 생성
Iterator<String> itr = set.iterator();
// hasNext() : 남아있는 요소가 있으면
// next() : 그 요소를 꺼냄
while(itr.hasNext()) {
String element = itr.next();
System.out.println(element);
}HashMap과 Iterator
- keySet() 메소드로 key만 Set에 저장한다.
- key를 저장한 Set에 Iterator를 등록해서 사용한다.
Map<String, Object> map = new HashMap<String, Object>();
map.put("page", 1);
map.put("column", "제목");
map.put("query", "날씨");
Set<String> keys = map.keySet();
Iterator<String> itr = keys.iterator();
while(itr.hasNext()) {
String key = itr.next();
Object value = map.get(key);
System.out.println(key + " : " + value);
}Collections
- 패키지 : java.util
- 컬렉션을 대상으로 특정 연산을 수행할 수 있는 클래스
- 모든 메소드가 클래스 메소드(Static)로 되어 있음
- 주요 메소드

public static void printMovies(List<String> list) {
for (int i = 0, size= list.size(); i < size; i++) {
System.out.print(list.get(i));
if(i < (size - 1)) { // size-1 : 마지막 요소의 인덱스
System.out.print(" -> ");
}
}
System.out.println();
}
public static void main(String[] args) {
List<String> movies = new ArrayList<String>();
movies.add("아바타");
movies.add("쇼생크탈출");
movies.add("명량");
movies.add("에일리언");
movies.add("여인의향기");
printMovies(movies); // 아바타 -> 쇼생크탈출 -> 명량 -> 에일리언
// movies 리스트를 오름차순 정렬시킴
Collections.sort(movies);
printMovies(movies);
// movies 리스트를 내림차순 정렬시킴
Collections.reverse(movies);
printMovies(movies);
// 특정 요소의 인덱스 반환
// 이진 검색(binary search)을 이용하므로 검색 속도가 매우 빠름
// 단, 크기순으로 정렬이 되어 있어야 함
int idx = Collections.binarySearch(movies, "아바타");
System.out.println(idx);
}