시작하며
드디어 빅데이터분석기사 자격증에 합격했다. 취업준비 시절 필기 따두고 한 동안 잊고 살다가 실기 시험 만료일이 다가와서 실기 준비를 했다. 필기 취득 후 2년안에 실기를 따야 최종 합격인데 2년을 꽉 채울만큼 미루다가 드디어 땄다..! (그 동안 많은 일들이 있었네. 신입을 두 번이나 했지만 결국은 데이터 사이언티스트까진 아니고 데이터 분석가로 취뽀 성공😉)
거두절미 하고 지금 회사에 신입으로 들어온 지 5개월차여서 적응하다보니 실기 시험을 A부터 Z까지 준비할 시간은 없었기에 최대한 효율적인 방법으로 틈틈히 공부하였다. 그 방법이 돌아보니 지름길인 것 같고 시간이 부족한 현대사회인들에게 도움이 될 듯하여 후기를 쓰게 되었다.ㅎㅎ 누군가에겐 도움이 되길 바라며..
그나저나 내가 올렸던 SQL For문 관련 게시글이 다시보니 2만회가 넘었다...? 좋아요는 4개라 이렇게 조회수가 클 줄 몰랐는데 이번 글은 5만회를 찍었으면 좋겠다!ㅎㅎ
❓ 자격증이 데이터 분석가 취업에 도움이 됐나요?
아, 주변에서도 많이 궁금해했던 질문 먼저 정리를 하려고 한다. 우선 이 자격증이 '분석 업무를 잘 할 수 있다.'라는 부분을 표현할 수 없지만 분석 업무에 관심을 갖고 노력해왔어요.라는 부분에선 어필이 된 것 같다. 다시 취준생이 되더라도 하나의 어필점으로 만들기 위해 취득할 것 같다. 나는 현재 글로벌 온라인몰 사이트의 UX를 데이터로 분석하는 일을 하고 있다. 신입 공채로 입사를 하였고 그때 직무명이 '데이터분석'이었다. 그래서 면접볼 때에도 '데이터 분석에 관심이 있어 ADsP, 빅데이터분석기사 자격증을 준비하며 공부해왔다.'라는 식으로 관심을 드러냈다.
합격 인증
필기, 실기 시험 다 안정적으로 합격했다. 특히 실기시험은 외워서 푸는 단답형을 제외하고는 만점 받았는데 외우는 건 여전히 자신이 없고 내용도 방대하기 때문에 실기 위주로 공부 방법을 풀려고 한다!
필기시험 합격🎉
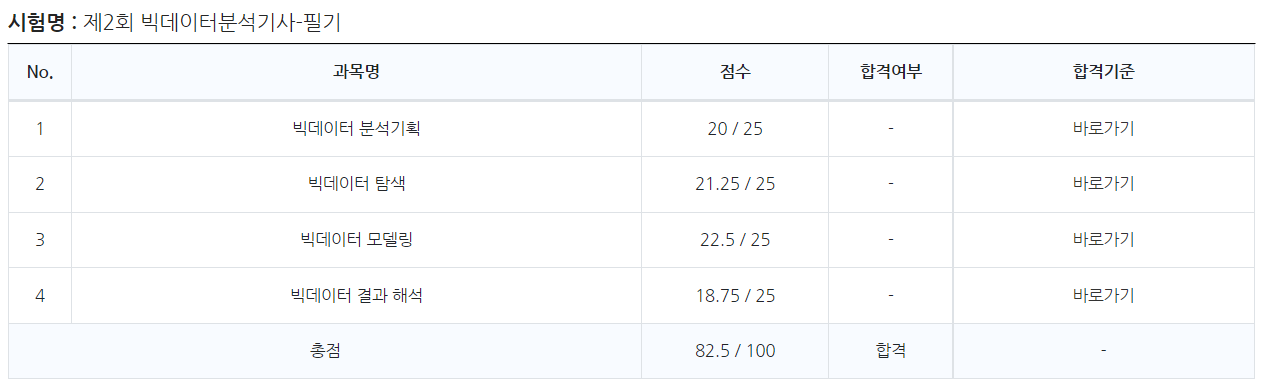
실기시험 합격🎉🎉
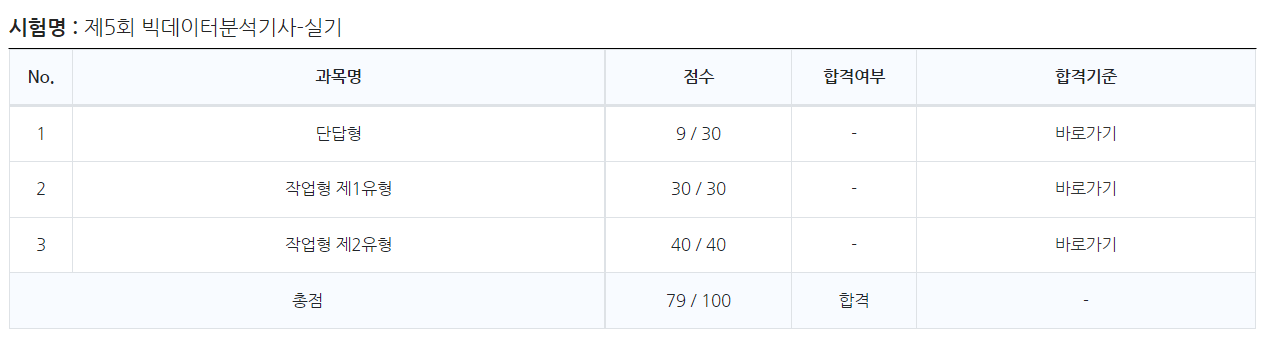
단답형
내 단답형 눈감아... 단답형은 나올 수 있는 범위가 너무 커서 인터넷에 떠도는 단답형 정리 문서만 제대로 외우고 가자!는 전략이었는데.. 예.. 이건 시간적 여유가 된다면 문제집에 있는 단답형 문제들을 외우면 될 것이고, 시간이 부족하다면 최소한 외울 부분만 외우고 작업형에 몰두하는게 좋을 듯하다.
작업형 제1유형
나는 파이썬을 사용해본 적이 있었지만, 항상 검색찬스를 이용했기 때문에 간단한 코드도 검색없이 작성하는 건 어려운 상태였다. 그래서 책으로 찬찬히 익히는 방법보단 예시 문제를 최대한 많이 풀어보고 반복하는 방식으로 연습했다. 그때 많이 도움이 됐던 사이트가 있었는데 이렇게 무료로 예시 문제를 다 공유해주셔서 넘 많은 도움을 받았다..💛
빅데이터분석기사 자격증과 관련해서 얻을 수 있는 모든 자료를 정리해놓았다. 빅분기 관련 강의도 인프런에서 제공하고 계시는 것 같은데 혹시나 파이썬이 처음이라거나 연습문제를 시도하기 어려운 상태라면 들으면 좋을 듯 하다. 그치만 혼자 연습할 수 있는 문제도 다 무료로 올려놨으니 혼자 연습해도 충분한 상태의 문제 퀄리티다! 짱짱😎
나는 그 중에서도 아래로 쭉 내려가면 작업형1 예상문제만 반복 연습하고 시험을 보았는데, 파이썬, R 버전으로 다 올려놓으셔서 본인이 시험 볼 언어를 골라서 연습하면 된다. 여기에 있는 문제들만 제대로 익히고 가도 제1유형은 아주 무난하게 합격할 수 있다. 5회 실기 시험의 경우 여기에 있던 연습문제들 보다는 훨 쉽게 나왔다!

나는 자주 틀리는 문제 위주로 3-4번 돌리고 갔다. 검색이 원천 차단되기 때문에 애매하게 알면 모르니만도 못 한 결과가 나오기 때문에 아래처럼 자주 틀리는 부분 정리해가면서 혼자 풀 수 있는 영역을 좁혀 나갔다.
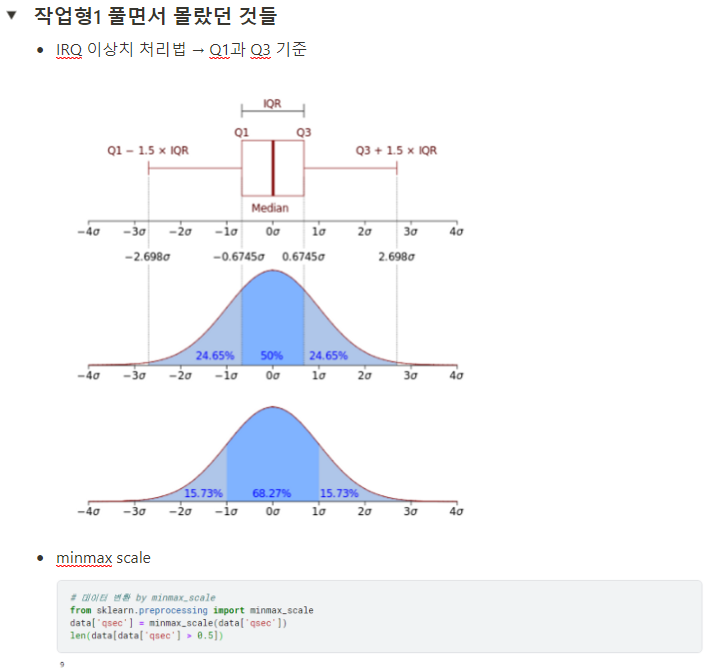
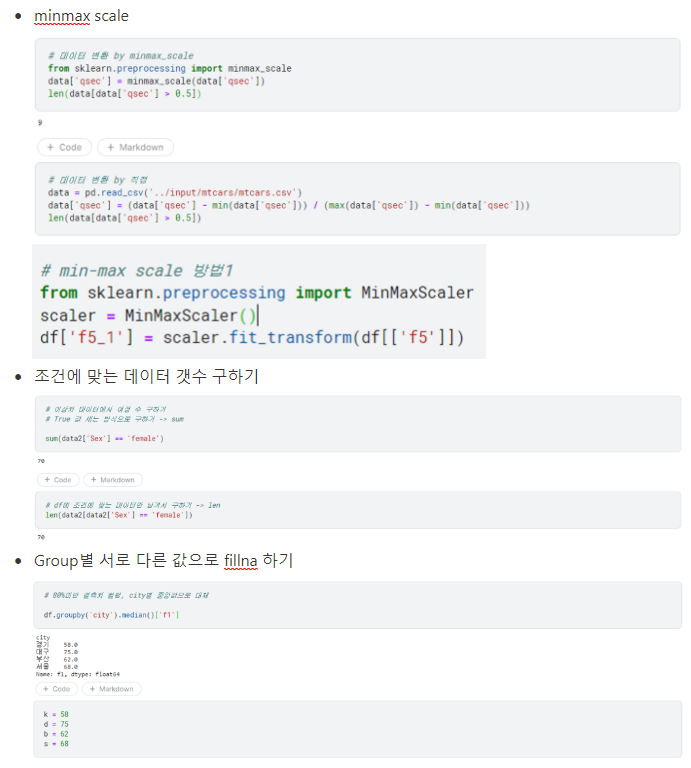
작업형 제2유형
작업형 제2유형은 정석으로 준비하려면 아주 많은 시간이 드는 문제인 것 같다. 1분안에 모든 코드가 다 돌아가 결과값을 내야하기 때문에 아주 정교한 모델링을 요하는 문제는 아닌 것 같다. 그래서 데이터에 적합한 모델을 고르고 하이퍼파라미터를 튜닝하는 작업은 전부 생략하고 (어차피 시간 제한 때문에 시험 환경에선 불가함), 적당한 결과값을 내는 것을 목표로 준비했다.
그렇게 생각하면 제2유형에서 나올 수 있는 문제는 크게 두 가지였다. 분류를 예측하는 문제 혹은 값을 예측하는 문제..! 참고로 5회차에서는 값을 예측하는 문제가 나왔었다. 나는 모든 경우를 랜덤포레스트를 통해 푸는 방법을 택했는데, 그 이유는 활용하기 가장 쉽고 결과값도 무난하기 때문이었다.
풀이 순서
모든 문제의 풀이 순서는 다음과 같다. 문제가 분류이면 6번에서 from sklearn.ensemble import RandomForestClassifier를 값 예측이면 from sklearn.ensemble import RandomForestRegressor를 쓰면 된다. 참 쉽다!
1. 데이터 파일 읽기 -> 응시환경에 기본 제공
2. 필요 없는 칼럼 삭제 -> 모델링에 필요하지 않은 칼럼(ex.고객id, 이름 등) 삭제
3. 결측치 채우기 -> 결측치는 웬만하면 채우는 게 결과값에 좋았다.
4. 라벨인코딩 -> 명목형변수(숫자 외의 값)가 있다면 꼭 해야함
5. Test, Train split -> 내가 만든 모델이 잘 돌아가는 지 확인하려고 일부러 Train데이터를 한번 더 쪼갬
6. 모델 만들기 -> 랜덤포레스트 이용
7. 모델링 잘 됐는지 확인 -> 5번 단계에서 쪼개놨던 데이터로 모델링이 잘 됐는지 확인
8. 결과값 내기
9. 제출 -> 이 부분은 응시환경과 다르게 실제 시험에선 코드 제공을 안 해서 외워가기문제 풀이 코드
한국데이터산업진흥원에서 제공하는 문제를 위와 같은 방법으로 풀어보았다. 접속하여 한 단계씩 직접 입력하여 결과를 확인하면 좋을 것 같다.
1. 데이터 파일 읽기
import pandas as pd
X_test = pd.read_csv("data/X_test.csv")
X_train = pd.read_csv("data/X_train.csv")
y_train = pd.read_csv("data/y_train.csv")2. 필요없는 칼럼 삭제
X_train = X_train.drop(['cust_id'], axis = 1)
y_train = y_train.drop(['cust_id'], axis = 1) 3. 결측치 채우기
X_train['환불금액'] = X_train['환불금액'].fillna(X_train['환불금액'].mean())
X_test['환불금액'] = X_test['환불금액'].fillna(X_test['환불금액'].mean())4. 라벨인코딩
from sklearn.preprocessing import LabelEncoder
cols = ['주구매상품', '주구매지점']
for i in cols:
ll = LabelEncoder()
X_train[i] = ll.fit_transform(X_train[i])
X_test[i] = ll.transform(X_test[i])
5. test,train나누기
5번은 문제를 푸는 과정에서 실제 시험에선 모델링이 잘 됐는지 확인할 방법이 없기에 추가한 단계이다. Train데이터를 다시 90%와 10%로 나누어 90%으로 모델링을 하고, 10%로 모델링이 잘 되었는지 확인하였다. 이 단계를 추가한 이유는, 실기 점수가 채점 지표별 구간별로 점수를 부여하기 때문에 아주 정확한 모델은 아니더라도 그럭저럭 돌아가는 모델링을 제출하는 것만으로도 합격 확률을 높인다고 생각했다. 5회차 실기 볼 때도 이렇게 확인을 했는데 r2스코어 90%을 보이며 아주 높게 나왔고, 실제 점수도 만점을 받았다!
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val = train_test_split(X_train, y_train['gender'], test_size = 0.1)6-1. 모델 만들기(분류 문제일 때)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_tr, y_tr)6-2. 모델 만들기(값 예측일 때)
from sklearn.ensemble import RandomForestRegressor
model = RandomForestClassifier()
model.fit(X_tr, y_tr)7-1. 확인(분류 문제일 때)
Accuracy score을 통해 모델이 분류를 정확히 확인하는 지 확인(최대 1)
pred_tr = model.predict(X_val)
from sklearn.metrics import accuracy_score
print(accuracy_score(pred_tr, y_val))7-2. 확인(값 예측일 때)
R2스코어(결정계수)를 통해 모델이 값을 얼마나 잘 설명하는 지 확인(최대 100)
from sklearn.metrics import r2_score
pred = model.predict(X_val)
r2_score(y_val, pred)8-1. 결과값(분류일 때)
분류 문제는 특정 값으로 분류될 확률을 구하는 경우도 있다.
pred = model.predict_proba(X_test.iloc[:,1:]) -- 확률을 요할 때
pred = model.predict(X_test.iloc[:,1:]) -- 분류값을 요할 때8-2. 결과값(값 예측일 때)
pred = model.predict(X_test.iloc[:,1:])9. 답안제출
pd.DataFrame({'cust_id': X_test.cust_id, 'gender': pred}).to_csv('003000000.csv', index=False)이 문제 풀이과정 중 3번과 4번 단계에서 추가적으로 결측값 처리를 더 정교하게 한다거나, 정규화를 하는 등 추가할 수 있겠으나 우선 이런 단계로만 풀어도 적당한 점수를 얻는데는 충분하다고 생각한다.
이 단계를 익혔으면 빅데이터분석기사 자료방에 있는 연습 문제를 이 순서대로 풀어보면 된다.ㅎㅎ
작업형2를 푸는 다양한 방법이 있겠지만, 최대한 자신만의 풀이법을 만들고 데이터를 이에 맞춰나가는 것이 제일 간단하면서도 빠른 방법이라 생각한다.
마치며
이상 효율을 중시 여기는 사람의 합격 후기였다 ㅎㅎ 요약하자면 작업형1은 연습을, 작업형2는 풀이 루틴을 만들어 나가는 것이 중요하다는 것이다. 짧은 글인데 쓰는데는 2시간이 걸리는 매직... 그래도 누군가에게 도움이 되었으면 좋겠다!




많은 도움이 되었어요 고맙습니다