AWS EC2인스턴스에 음식 객체 인식 AI 모델을 배포하면서 겪은 CPU 100% 문제의 해결과정을 적어보려 합니다.
😡 발생한 문제
PEANUT 프로젝트를 진행하면서 음식 객체인식 AI 모델을 배포하는 과정이었습니다.
AI모델 컨테이너를 빌드하는 과정에서 서버가 멈췄습니다. 예전에 동일한 모델을 배포한 경험이 있었고, 이번에도 동일한 환경을 적용하여 동일한 모델을 이었습니다. 핫스팟을 사용하여 단순 네트워크 문제라 인식했지만, 다른 와이파이를 사용해도 동일한 문제를 겪었습니다. 또한 모델 경량화 작업도 진행하여서 용량 문제도 아니었습니다.
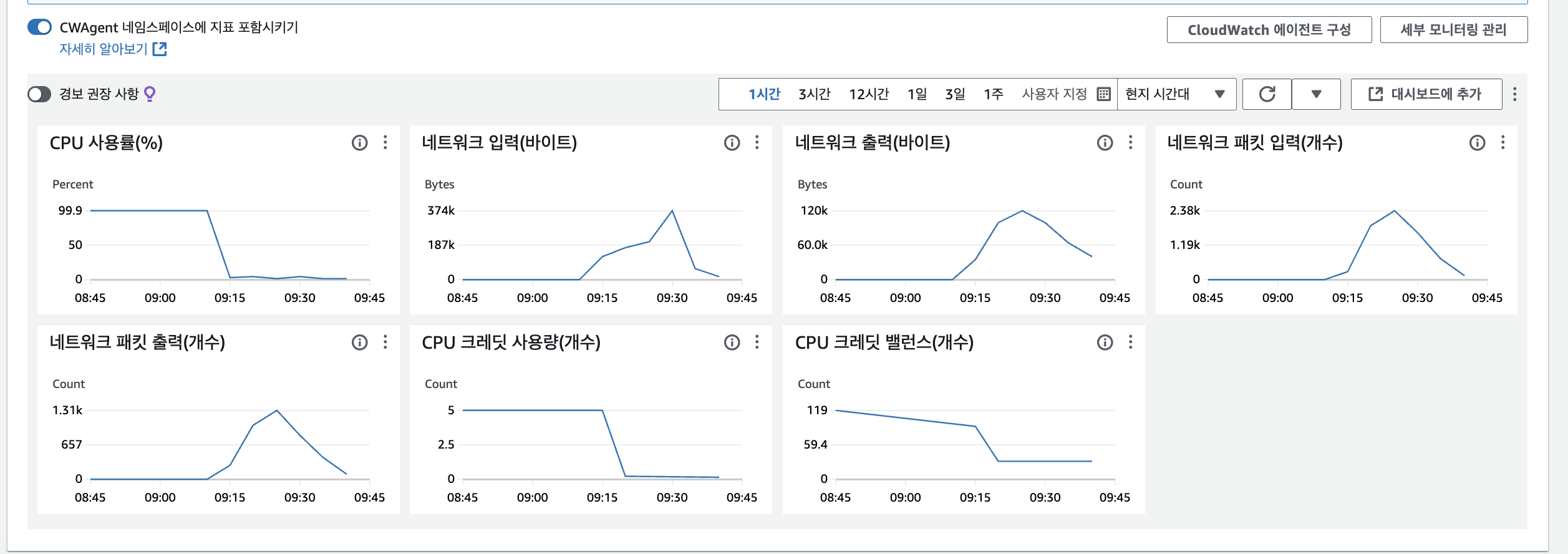
저는 AWS EC2 인스턴스의 문제라 생각이 되었고, AWS EC2 인스턴스를 모니터링을 해보았습니다. 그런데!!!
CPU 사용률이 갑자기 기하급수적으로 올랐고, 99%이상을 도달하면서 서버가 멈췄습니다.
왜 문제가 발생하였을까?
제가 알고 있는 문제 원인은 크게 3가지입니다.
-
고부하 작업 실행 -> 데이터 처리, 대규모 계산, 이미지 또는 비디오 처리 등과 같은 CPU 집약적인 작업이 실행될 때 CPU 사용량이 급증할 수 있습니다.
-
서비스 과부하: 웹 서버, 데이터베이스 또는 애플리케이션 서버가 많은 요청을 처리할 때 CPU 부하가 증가할 수 있습니다. 특히, 비효율적인 코드나 쿼리로 인해 과도한 CPU 자원을 소모할 수 있습니다.
-
스팸 공격 또는 DDoS 공격: 외부에서 서비스에 대한 스팸 요청이나 DDoS 공격이 발생하면 CPU 사용량이 급증할 수 있습니다. 보안 그룹이나 방화벽 설정을 통해 이런 공격을 차단해야 합니다.
그럼 이 문제 중 가장 원인이 될 가능성이 높은 원인은 첫 번째 입니다.
device = 'cpu'
model = torch.hub.load('ultralytics/yolov5', 'custom', path=str(model_path), force_reload=True).to(device)
AI 모델 코드중 다음과 같은 부분을 확인 할 수 있었습니다.
모델이 사용할 장치는 cpu로 고정을 해놓은 부분을 확인하였고, 이 부분 때문에 메모리 사용 과다로 인한 문제가 원인이라고 생각했습니다.
사실 대용량 데이터를 처리하고, 딥러닝 모델 같은 고속 병렬 처리 작업을 하는 AI 모델은 보통 GPU를 사용하는 것을 권장합니다. 사실 gpu를 사용하여 CUDA 환경에서 배포하였다면 이런 일이 생기지 않았을 확률이 높습니다. 그러나 저는 AWS EC2 프리티어를 사용하고 있었기 때문에 gpu를 사용할 수 없는 환경이었습니다.
내가 생각한 원인이 맞을까?
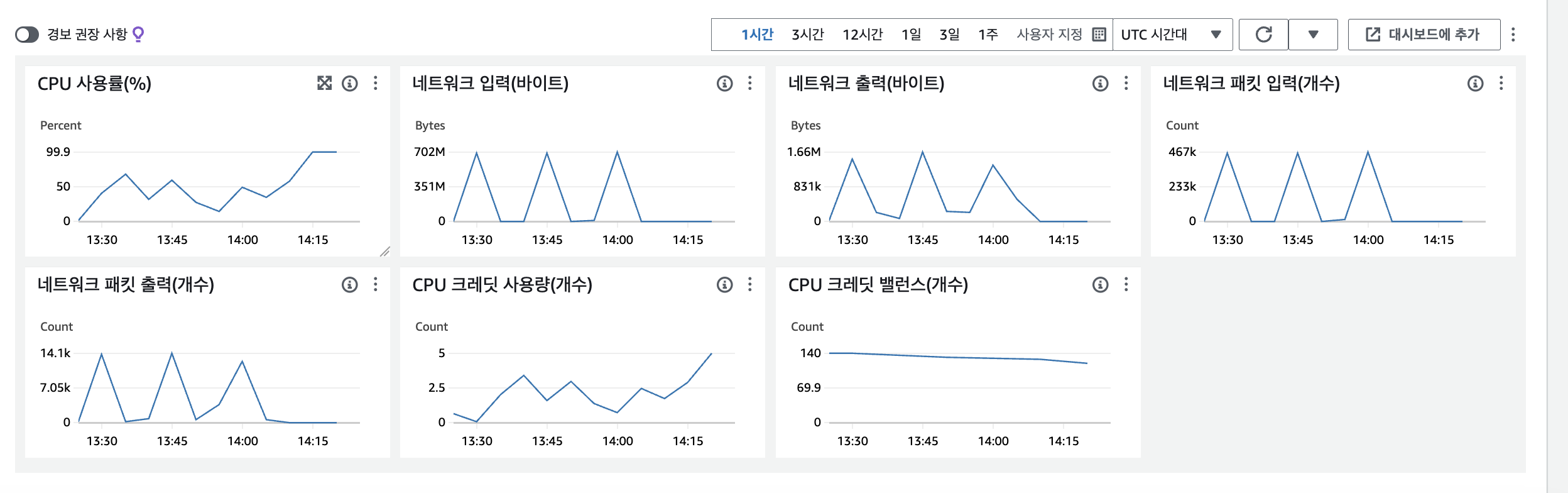
일단 제가 꼽은 원인 중 하나가 AI 모델이 무거워서 CPU가 올라갔다고 판단했지만 실제 AI모델 배포를 할 때만 CPU가 올랐는지에 대해서는 직접 확인하지 않았습니다.
CPU를 일시적으로 낮추기 위하여 인스턴스를 재부팅하고 기다렸습니다. 3분 정도 지나니 CPU는 다시 0~3사이로 떨어졌고, 이전과 동일한 과정을 AI 모델 도커 빌드를 시작했습니다. 이때 급격히 CPU가 상승하는지 확인하기 위하여
top커맨드를 사용하여 보았습니다.
AI 모델 도커 빌드 전 cpu가 0.5~2.0 사이를 유지합니다.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1304 ubuntu 20 0 14992 6944 4992 S 0.7 0.7 0:00.78 sshd AI 모델 도커 빌드 후 바로 30 -> 70 -> 90.2로 올랐습니다.
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1304 ubuntu 20 0 14992 2336 2048 R 90.2 0.2 0:10.00 PID USER 즉, AI 모델이 무거워서 일시적으로 90이상 오른 것으로 판단하였습니다.
문제 해결
그렇다면 AWS EC2 프리티어를 사용하는 저는 AI 모델을 배포할 수 없을까? 라는 의문점을 가지고, 많은 정보들을 찾던 중 스왑영역을 생성하여 문제를 해결하도록 시도를 하였습니다.
리눅스에서는 SWAP 메모리를 지정할 수 있습니다.
SWAP 메모리란 ?
RAM이 부족할 경우가 있으므로 HDD의 일정공간을 마치 RAM처럼 사용하는 것이다. 그래서 우리는 반 강제적으로 RAM을 증설한 듯한 효과를 만들수 있습니다.
스왑 공간 크기 계산
| 물리적 RAM의 양 | 권장 스왑 공간 |
|---|---|
| RAM 2GB 이하 | RAM 용량의 2배(최소 32MB) |
| RAM 2GB 초과, 32GB 미만 | 4GB + (RAM – 2GB) |
| RAM 32GB 이상 | RAM 용량의 1배 |
스왑 공간은 절대로 32MB 미만이 되지 않아야 합니다. 어쨌든 EC2 프리티어를 통해서 RAM을 획득할 수 있는 것은 1GB이므로, 2GB정도로 생각하고 잡으면 됩니다.
스왑 파일을 활용한 문제 해결
- dd 명령어를 통해 swap 메모리를 할당합니다.
sudo dd if=/dev/zero of=/swapfile bs=128M count=16- 128씩 16개의 공간을 만드는 것이기 때문에 count를 16으로 할당하는 것이 좋습니다. 즉, 2GB정도 차지하는 것입니다.
스왑 파일에 대한 읽기 및 쓰기 권한을 업데이트합니다.
$ sudo chmod 600 /swapfileLinux 스왑 영역을 설정합니다.
$ sudo mkswap /swapfile스왑 공간에 스왑 파일을 추가하여 스왑 파일을 즉시 사용할 수 있도록 만듭니다.
$ sudo swapon /swapfile 절차가 성공했는지 확인합니다.
sudo swapon -s /etc/fstab파일을 편집하여 부팅 시 스왑 파일을 활성화합니다.편집기에서 파일을 엽니다.
sudo vi /etc/fstab파일 끝에 다음 줄을 새로 추가하고 파일을 저장한 다음 종료합니다.
/swapfile swap swap defaults 0 0다음과 같이 적용되었는지 확인합니다.
free -h
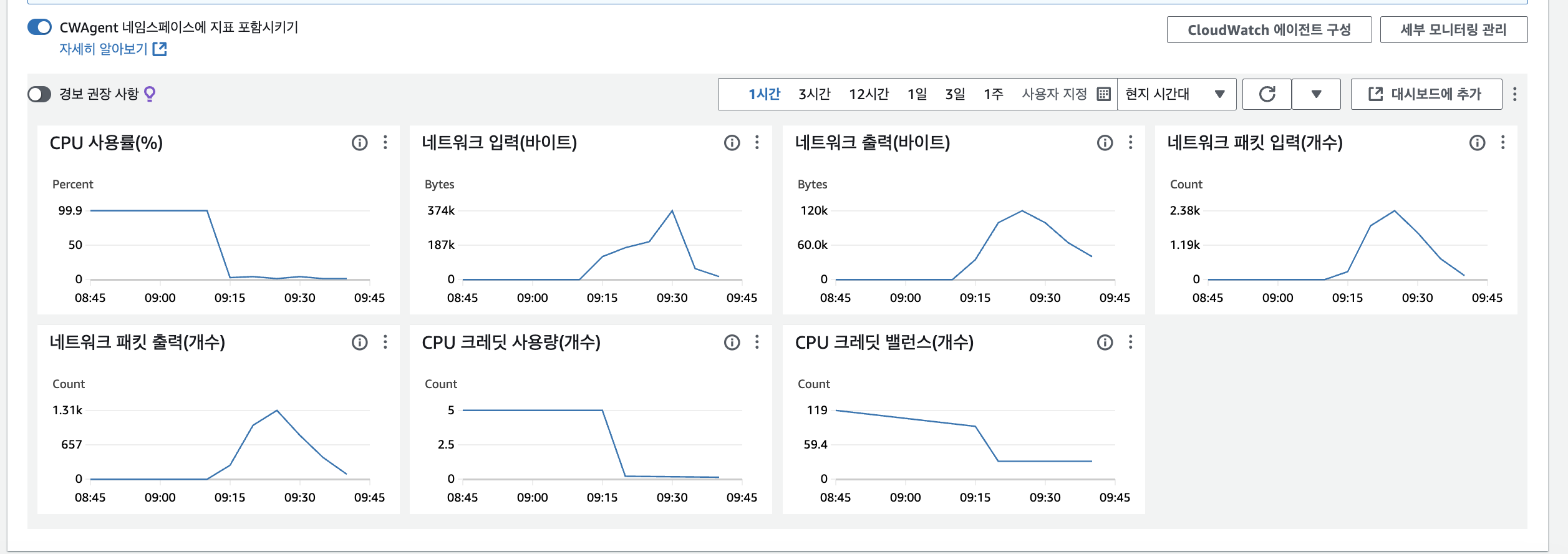
스왑 메모리 설정 후 AI 모델 빌드
현재는 이렇게 잘 빌드가 되었고, 잘 배포가 되었습니다.

AI 모델 배포 후 AWS EC2 모니터링 CPU 사용량 확인하기
이렇게 이제 CPU 사용량이 확 줄었으며,
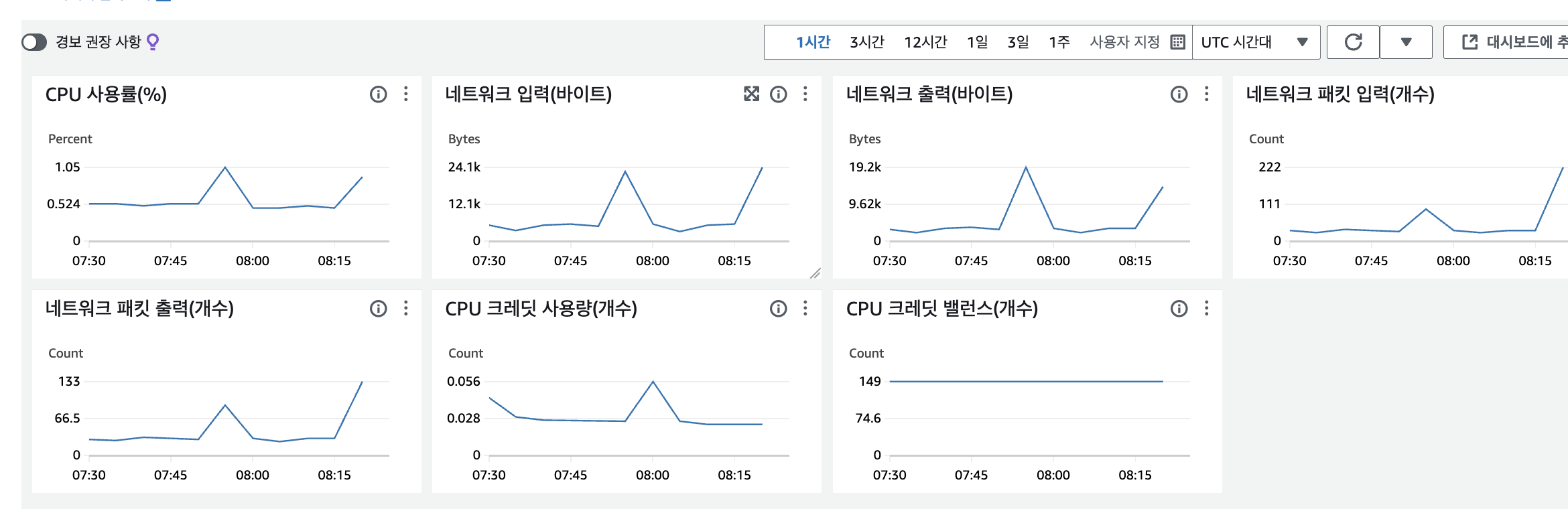
2일이 지난 현재는 CPU가 1~5 사이로 안정적으로 유지되는 것을 확인하였습니다.
마무리
현재 해결한 상황은 100프로 정답이 아니고, 일시적인 해결이라 생각됩니다. AI 모델을 CUDA환경에서 작업하는 것이 더 안정적이지만, 프리티어를 사용하는 시점에서는 최적의 방법이라고 생각됩니다. 다른 방법도 더 찾아볼 예정이며, GPU 환경으로도 배포를 하여 CPU가 어떻게 변화되는지 확인할 예정입니다.
