
CLOVA OCR 이란
CLOVA OCR은 NCloud에서 제작된 AI Service입니다. 사용자가 전송한 문서나 이미지를 인식하고, 분석하여 사용자가 지정한 영역에서 텍스트와 데이터를 추출하며 미리 등록한 템플릿과의 유사도를 통해서 사용자가 개입하지 않고도 문서를 자동으로 분류하는 것이 가능하기 때문에 다양한 업무에서 효과적으로 활용이 가능합니다.
CLOVA OCR이 제공하는 기능들
NAVER CLOUD FLATFORM에서 제시한 기능들입니다.
- 이미지나 문서에서 인식 결과를 추출: 문서를 인식하고 사용자가 지정한 영역의 텍스트와 데이터를 정확하게 추출합니다.
- 문서 처리 자동화와 액션 연동: 등록된 템플릿과의 유사도를 통해 문서를 자동 분류하여 효과적인 업무 워크플로우 설계합니다.
- 인식 결과 검증 프로세스: 인식된 결과값을 검증할 수 있어 반복 검증 업무를 줄이고 신뢰도 향상됩니다.
- 다양한 서비스에 연계하여 활용 가능하도록 쉽고 간편한 Restful API 제공: 인식에 사용할 언어와 이미지 데이터를 입력받고, 그에 맞는 인식 결과를 텍스트로 반환합니다.
특허명세서 도면
특허명세서에서 도면(Drawings)은 발명의 구조, 작용, 특징 등을 시각적으로 표현한 요소로서, 발명의 이해를 돕고, 명세서의 기술 내용을 보완하는 데 매우 중요한 역할을 합니다. 아래 사진이 도면입니다.
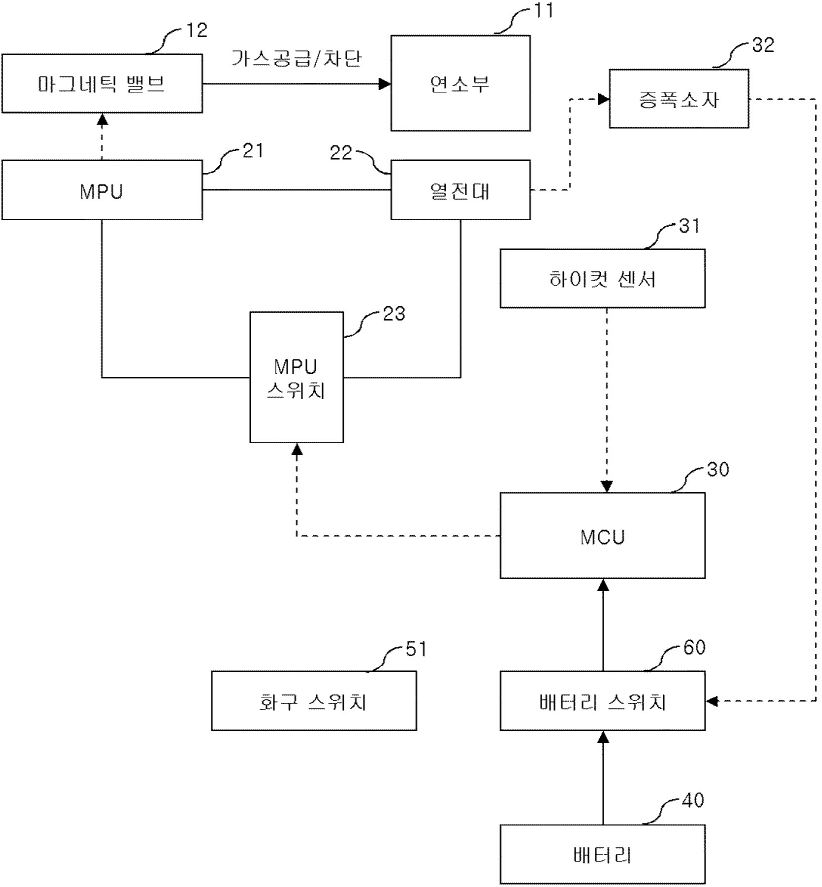
위 도면은 린나이 "가스 쿡탑"이라는 특허명세서에 있는 도면을 참고하였습니다.
도면의 목적
- 명세서 보조: 서면으로 설명된 발명의 내용을 시각적으로 명확하게 전달합니다.
- 심사관 및 제3자의 이해를 도움: 복잡한 기계, 회로, 구조물 등의 구성을 쉽게 파악할 수 있습니다.
CLOVA OCR를 이용한 특허명세서 도면의 도면 부호 추출
제작할 API <기존에 제공하는 API 가 아닌 특허명세서 도면에 있는 도면부호를 추출하는 API>
- 도면에 있는 모든 텍스트 추출하는 API(OCR 응답 그대로)
- 직접 필터링하여 도면 부호 텍스트만 추출하는 API
- 특허명세서에 있는 도면 사진을 전송하여 이미지에 있는 텍스트 데이터들을 뽑아옵니다.
- 그 텍스트중 도면부호만 뽑아서 결과를 반환합니다.
- 이때 이때 '숫자' 또는 '영문+숫자'로만 이루어진 텍스트만 뽑도록 정규식을 이용해서 패턴을 지정합니다.
CLOVA OCR 사용 방법
CLOVA OCR는 유료이기 때문에 아래 링크를 참고하여 결제 후 진행합니다.
CLOVA OCR 사용 준비
SpringBoot를 이용한 CLOVA OCR를 이용한 특허명세서 도면의 도면 부호 추출 과정
CLOVA OCR - General OCR
위 공식문서를 참고해서 API 요청/응답 값을 확인하고, 진행합니다.
CLOVA OCR은 두 가지 방법으로 API를 제작할 수 있습니다.
두 가지 방법
1. Content-Type: application/json : URL 로 이미지 전송
2. Content-Type: multipart/form-data : 직접 File로 이미지 전송
1번(Content-Type: application/json으로 이미지 URL 전송)은 간편하지만 보안상 취약할 수 있고, 2번(multipart/form-data로 파일 직접 전송)은 비교적 안전하고 테스트에 더 적합한 방식입니다. 즉, 저는 로컬에서 이미지 OCR API 테스트를 진행하고, 도면 부호만 뽑는 필터링을 진행할 것이기 때문에 2번 방법으로 하였습니다.
🧾 개발 환경
Java 17
Spring Boot 2.5.6
Maven
Swagger 2.9.2
CLOVA OCR (general/custom model)
📁 프로젝트 구조
├── main
│ ├── java/org/springboot/ncpocr
│ │ ├── controller → API 엔드포인트 (파일 업로드)
│ │ ├── service → CLOVA OCR 호출 및 도면부호 필터링 로직
│ │ ├── dto
│ │ │ ├── request → OCR 요청 DTO (version, requestId, images)
│ │ │ └── response → OCR 응답 DTO (OcrResponseDto, ImageResult)
│ │ └── config → Swagger 설정 등
│ └── resources
│ └── application.properties코드
요청 및 응답 형식은 위 링크의 공식문서에 존재하기 때문에 Service와 Controller만 정리하였습니다.
< OcrService >
- public OcrResponseDto callOcrApi(File imageFile) throws Exception
public OcrResponseDto callOcrApi(File imageFile) throws Exception {
// 1. Request DTO 생성
OcrRequestDto request = OcrRequestDto.builder()
.version("V2")
.requestId(UUID.randomUUID().toString())
.timestamp(System.currentTimeMillis())
.images(List.of(
OcrRequestImage.builder()
.format("jpg")
.name("sample")
.build()
))
.build();
// 2. DTO → JSON 문자열 변환
String messageJson = objectMapper.writeValueAsString(request);
log.info("messageJson: {}", messageJson);
// 3. JSON 헤더
HttpHeaders jsonHeader = new HttpHeaders();
jsonHeader.setContentType(MediaType.APPLICATION_JSON);
// 4. Multipart 바디 구성
MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();
body.add("message", new HttpEntity<>(messageJson, jsonHeader));
body.add("file", new FileSystemResource(imageFile));
// 5. 최종 헤더 설정
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.MULTIPART_FORM_DATA);
headers.set("X-OCR-SECRET", OCR_SECRET);
HttpEntity<MultiValueMap<String, Object>> requestEntity = new HttpEntity<>(body, headers);
// 6. 요청 실행
ResponseEntity<OcrResponseDto> response = restTemplate.exchange(
OCR_API_URL,
HttpMethod.POST,
requestEntity,
OcrResponseDto.class
);
log.info("응답 결과: {}", response);
// 7. 도면부호만 필터링하여 출력
List<String> figureCodes = extractFigureCodes(response.getBody());
log.info("도면부호만 추출: {}", figureCodes);
return response.getBody();
}
public List<String> extractFigureCodesOnly(File imageFile) throws Exception {
OcrResponseDto dto = callOcrApi(imageFile); // 기존 호출 재사용
return extractFigureCodes(dto); // 도면부호만 추출
}✔ 기능 요약
- 로컬에 있는 이미지 파일을 OCR 서버로 전송하고, 분석 결과를 받아 파싱하는 핵심 메서드입니다.
✔ 상세 설명
요청 JSON 생성:
- 내부적으로 OcrRequestDto를 생성하여 OCR 서버에서 요구하는 메시지 구조를 JSON 형태로 구성합니다.
- 이 구조에는 요청 ID, 타임스탬프, 이미지 이름/포맷 등의 메타 정보가 포함됩니다.
Multipart 요청 구성:
-
Message: JSON 문자열을 포함한 파트
-
file: 이미지 파일을 포함한 파트
이 두 파트를 multipart/form-data로 묶어 전송합니다. -
HTTP 요청 전송:
RestTemplate을 사용해 HTTP POST 방식으로 OCR API에 요청을 보냅니다.
요청 헤더에는 X-OCR-SECRET이라는 인증 키가 포함됩니다.
응답 파싱:
- OCR 서버로부터 받은 응답(JSON)은 OcrResponseDto로 자동 매핑되며, 로그로도 출력됩니다.
후처리:
- 응답 데이터 중 도면부호 텍스트만 정규식 필터링을 통해 추출하여 로그에 남깁니다.
public List<String> extractFigureCodesOnly(File imageFile) throws Exception {
OcrResponseDto dto = callOcrApi(imageFile); // 기존 호출 재사용
return extractFigureCodes(dto); // 도면부호만 추출
}🔍 public List extractFigureCodesOnly(File imageFile)
✔ 기능 요약:
- OCR 서버를 호출하고, 응답 중에서 도면부호(예: 12, 21A, A5 등)만 걸러서 리스트로 반환합니다.
✔ 상세 설명:
-
내부적으로 callOcrApi()를 호출하여 OCR 응답 전체를 받고, 그 응답을 extractFigureCodes() 메서드에 전달하여 도면부호만 추출합니다.
-
이 메서드는 실제 클라이언트나 컨트롤러 단에서 “도면부호만 필요할 때” 사용할 수 있는 편의 메서드입니다.
// 정규식: 숫자 또는 숫자+영문 1자리 (예: 12, 21A)
private static final Pattern FIGURE_CODE_PATTERN =
Pattern.compile("^(\\d{1,3}[a-zA-Z]?|[a-zA-Z]{1}\\d{1,3})$");
/**
* OCR 응답에서 숫자 도면부호만 추출
*/
private List<String> extractFigureCodes(OcrResponseDto dto) {
return dto.getImages().stream()
.flatMap(image -> image.getFields().stream())
.map(OcrField::getInferText)
.map(String::trim)
.filter(text -> FIGURE_CODE_PATTERN.matcher(text).matches())
.distinct()
.collect(Collectors.toList());
}🔍 private List extractFigureCodes(OcrResponseDto dto)
✔ 기능 요약:
OCR 응답(OcrResponseDto)에서 추출된 모든 텍스트 중, 도면부호에 해당하는 문자열만 정규식을 통해 필터링합니다.
✔ 상세 설명:
- 응답 내부의 이미지 → 필드 → 텍스트 구조를 따라 전부 펼쳐냅니다.
- getInferText()를 통해 각 인식된 텍스트를 가져오고 공백을 제거합니다.
- Pattern.matcher(text).matches()를 사용해 정규식 필터링을 수행합니다.
^(\d{1,3}[a-zA-Z]?|[a-zA-Z]{1}\d{1,3})$위 정규식은 다음 패턴을 허용합니다:
- 숫자 1~3자리 (예: 1, 23, 105)
- 숫자 + 영문자 1자리 (예: 10A, 3B)
- 영문자 1자리 + 숫자 (예: A1, B12)
- 중복 제거 후 List으로 반환합니다.
✅ 정리
메서드명 역할
callOcrApi(File) 이미지 파일을 OCR API에 전송하고 전체 응답을 파싱함
extractFigureCodesOnly(File) OCR 응답에서 도면부호 텍스트만 간편하게 추출
extractFigureCodes(OcrResponseDto) 응답 내 텍스트 중 정규식을 통해 도면부호만 필터링
< 전체코드 >
@Slf4j
@Service
@RequiredArgsConstructor
public class OcrService {
private final ObjectMapper objectMapper = new ObjectMapper();
private final RestTemplate restTemplate = new RestTemplate();
@Value("${OCR_API_URL}")
private String OCR_API_URL;
@Value("${OCR_SECRET}")
private String OCR_SECRET;
public OcrResponseDto callOcrApi(File imageFile) throws Exception {
// 1. Request DTO 생성
OcrRequestDto request = OcrRequestDto.builder()
.version("V2")
.requestId(UUID.randomUUID().toString())
.timestamp(System.currentTimeMillis())
.images(List.of(
OcrRequestImage.builder()
.format("jpg")
.name("sample")
.build()
))
.build();
// 2. DTO → JSON 문자열 변환
String messageJson = objectMapper.writeValueAsString(request);
log.info("messageJson: {}", messageJson);
// 3. JSON 헤더
HttpHeaders jsonHeader = new HttpHeaders();
jsonHeader.setContentType(MediaType.APPLICATION_JSON);
// 4. Multipart 바디 구성
MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();
body.add("message", new HttpEntity<>(messageJson, jsonHeader));
body.add("file", new FileSystemResource(imageFile));
// 5. 최종 헤더 설정
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.MULTIPART_FORM_DATA);
headers.set("X-OCR-SECRET", OCR_SECRET);
HttpEntity<MultiValueMap<String, Object>> requestEntity = new HttpEntity<>(body, headers);
// 6. 요청 실행
ResponseEntity<OcrResponseDto> response = restTemplate.exchange(
OCR_API_URL,
HttpMethod.POST,
requestEntity,
OcrResponseDto.class
);
log.info("응답 결과: {}", response);
// 7. 도면부호만 필터링하여 출력
List<String> figureCodes = extractFigureCodes(response.getBody());
log.info("도면부호만 추출: {}", figureCodes);
return response.getBody();
}
public List<String> extractFigureCodesOnly(File imageFile) throws Exception {
OcrResponseDto dto = callOcrApi(imageFile); // 기존 호출 재사용
return extractFigureCodes(dto); // 도면부호만 추출
}
// 정규식: 숫자 또는 숫자+영문 1자리 (예: 12, 21A)
private static final Pattern FIGURE_CODE_PATTERN =
Pattern.compile("^(\\d{1,3}[a-zA-Z]?|[a-zA-Z]{1}\\d{1,3})$");
/**
* OCR 응답에서 숫자 도면부호만 추출
*/
private List<String> extractFigureCodes(OcrResponseDto dto) {
return dto.getImages().stream()
.flatMap(image -> image.getFields().stream())
.map(OcrField::getInferText)
.map(String::trim)
.filter(text -> FIGURE_CODE_PATTERN.matcher(text).matches())
.distinct()
.collect(Collectors.toList());
}
}
- OcrController
package org.springboot.ncpocr.controller;
import lombok.RequiredArgsConstructor;
import org.springboot.ncpocr.dto.response.OcrResponseDto;
import org.springboot.ncpocr.dto.response.code.FigureCodeResponse;
import org.springboot.ncpocr.service.OcrService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.util.List;
@RestController
@RequestMapping("/api/v1")
public class OcrController {
private final OcrService ocrService;
@Autowired
public OcrController(OcrService ocrService) {
this.ocrService = ocrService;
}
@PostMapping("/upload")
public OcrResponseDto handleUpload(@RequestParam("file") MultipartFile multipartFile) throws Exception {
// MultipartFile → File 로 변환
File file = File.createTempFile("upload-", ".jpg");
multipartFile.transferTo(file);
// OCR API 호출
return ocrService.callOcrApi(file);
}
@PostMapping("/upload/codes")
public FigureCodeResponse handleUploadAndExtractCodes(@RequestParam("file") MultipartFile multipartFile) throws Exception {
File file = File.createTempFile("upload-", ".jpg");
multipartFile.transferTo(file);
List<String> codes = ocrService.extractFigureCodesOnly(file);
return new FigureCodeResponse(codes);
}
}
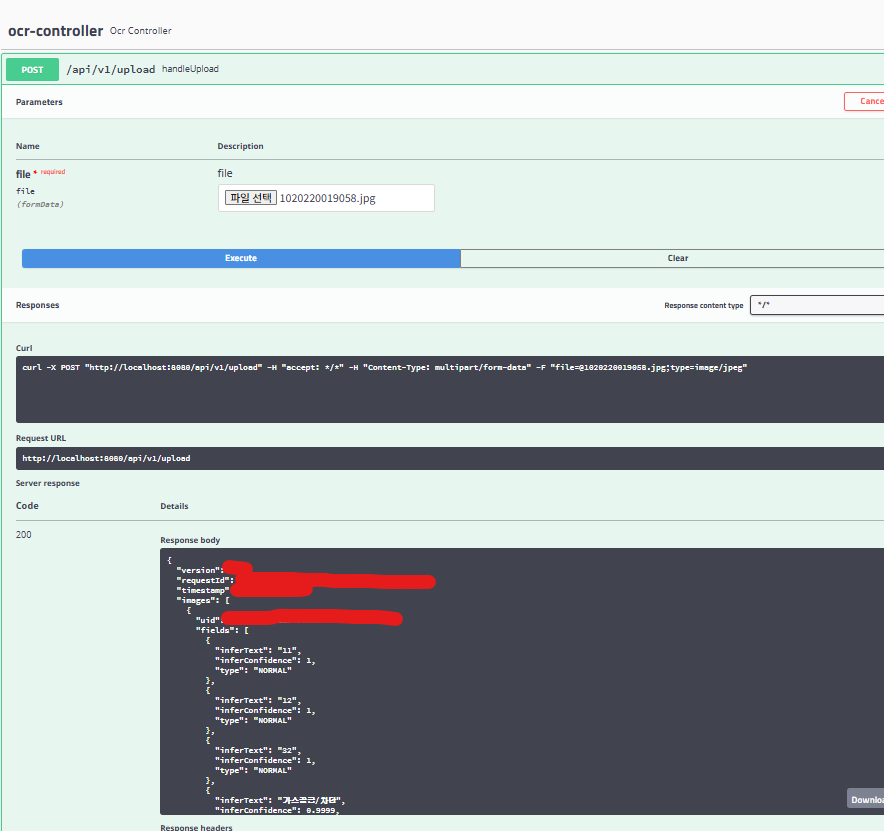
결과 (Swagger)
- /api/v1/upload
- /api/v1/upload/codes
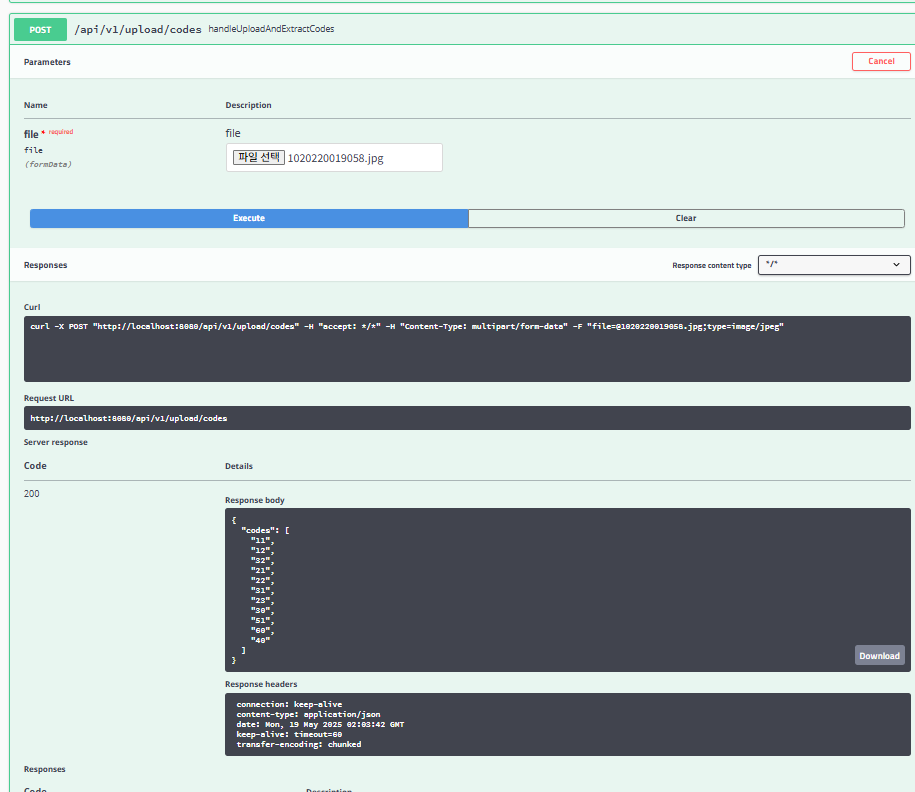
- 필터링한 도면 부호 데이터만 뽑았다.
간단한 🛠️ Troubleshooting
❌ Illegal character in scheme name at index 0: "%22https://... application.properties에서 URL을 복사하면서 "큰따옴표"로 감싸있어서 발생
해결: 큰따옴표 제거
잘못된 예 -> OCR_API_URL="https://..."
올바른 예 -> OCR_API_URL= https://...
❌ Cannot construct instance of ... (no Creators, like default constructor, exist) DTO 클래스에 기본 생성자(@NoArgsConstructor)를 넣지 않아서 발생
해결: 응답 DTO 클래스에 @NoArgsConstructor, @AllArgsConstructor 추가
❌ A bean with that name has already been defined 서비스단에서 직접 RestTemplate을 수동 생성하였는데 동시에 config에 @Bean으로도 등록하여 발생 전자의 방법으로 수정.
해결: 하나의 방식만 사용할 것 - 현재 구조는 new RestTemplate() 사용
